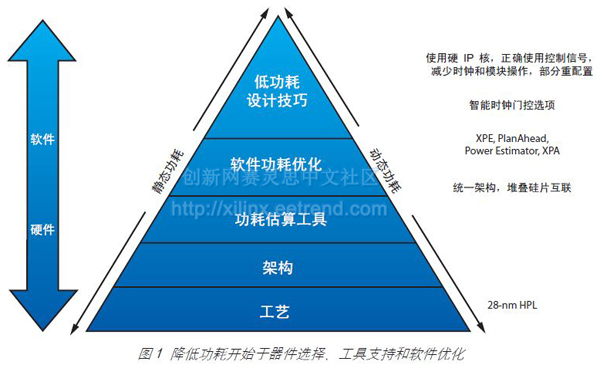
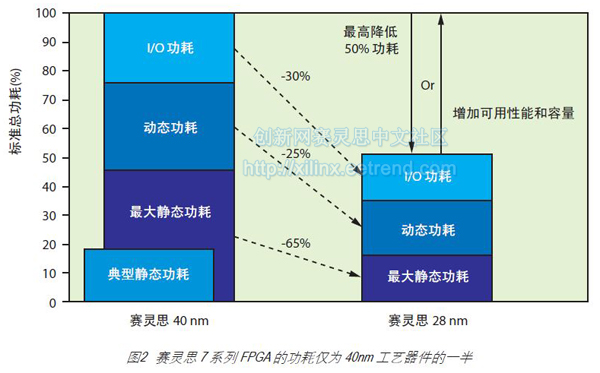
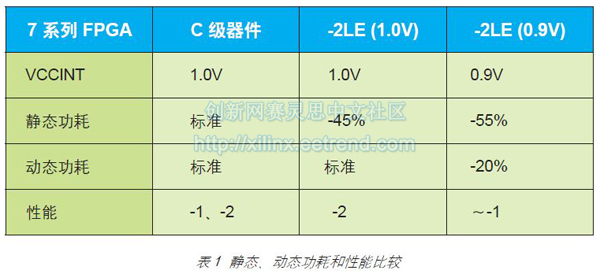
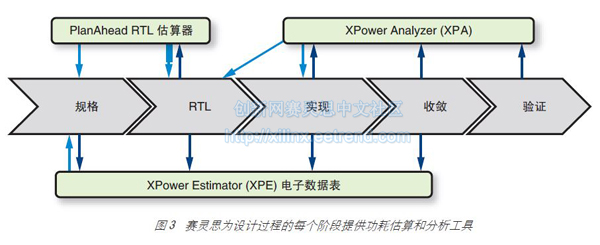
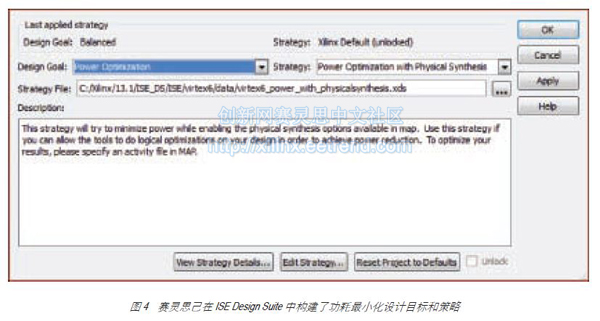
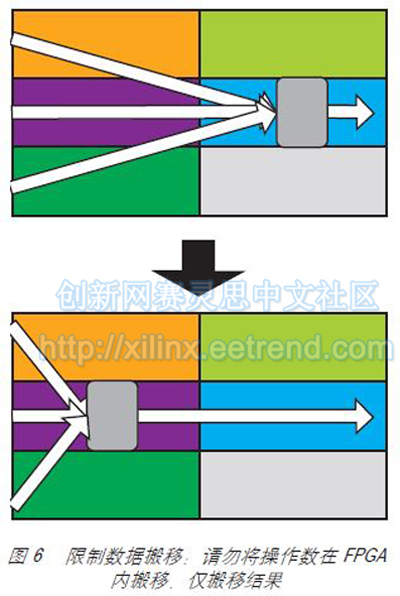
优化FPGA功耗:立竿见影
|
pengpengpang (pengpengpang)当前离线
 
 
论坛元老
|

|
||
|
pengpengpang (pengpengpang)当前离线
论坛元老
|
|
||
中电网 ( 粤ICP备17063136号-2)|联系我们 |论坛统计|Archiver|WAP|
GMT+8, 2024-4-24 11:34, Processed in 0.083631 second(s), 5 queries, Gzip enabled.
Powered by Eccn! 7.0.0
© 2001-2014 ChinaECnet Inc.