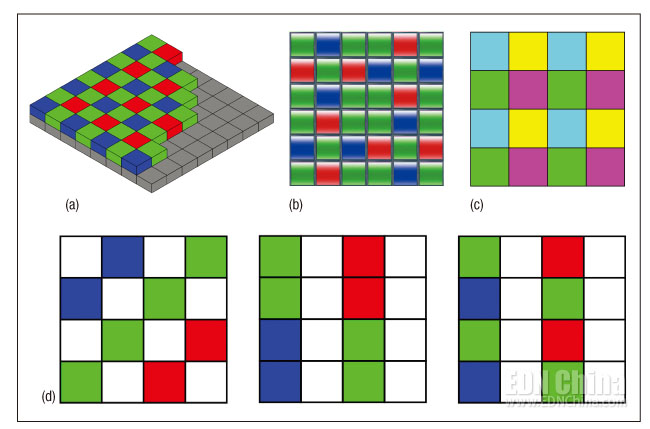
图3,无论采用哪种3D摄像头技术, 都能给出一个物体的深度图(a)。像HTC EVO 3-D智能手机这样的设备也可以用于3D嵌入视觉用途,该手机的立体传感器阵列主要用于捕捉3D静像和频图像(b)。微软的Kinect(c)采用的是结构光方法,测深的方法是在投影仪的前方投射一个知的红外光模式,然后分析它所看到椭圆的形状与方向(d)。
飞行时间(Time of flight)是第三种常见的3D传感器实现方法。与结构光一样,飞行时间摄像头包括一个图像传感器、一只镜片和一个有源发光源。但采用飞行时间方法时,摄像头会根据投射光从光源到投影仪,再回到图像传感器的时间,得出范围或距离(参考文献5)。发光源一般可以是一只脉冲激光器或调制光束,具体取决于设计采用的图像传感器类型。