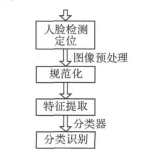
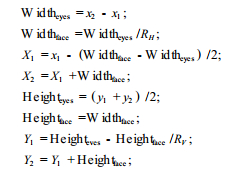图1 人脸识别算法流程
图2 重建人脸图像
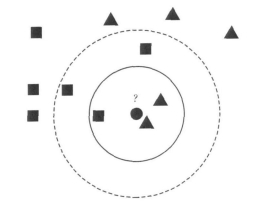
图3 KNN分类器
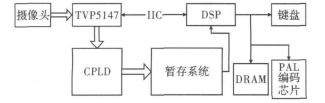
图4 系统结构框图
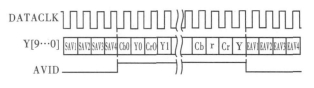
图5 TVP5147输出时序
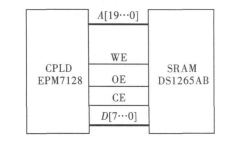
图6 CPLD与SRAM 连接示意图
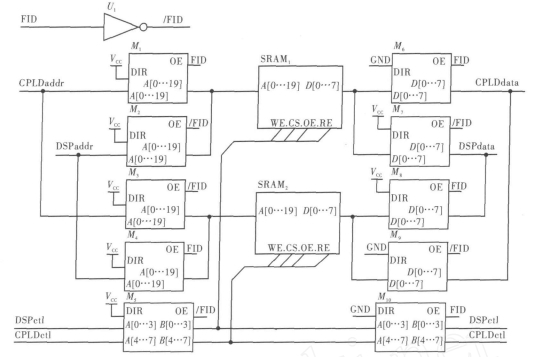
图7 SRAM切换电路图
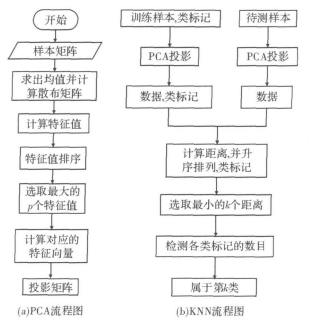
图8 PCA 与KNN流程图
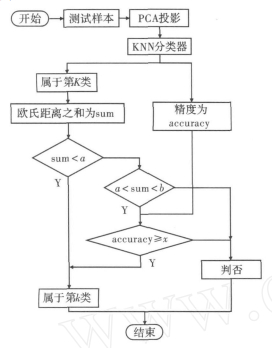
图9 人脸分类流程图