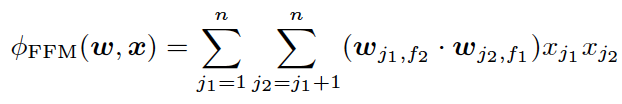标题:
从LR到FFM\n(4)
[打印本页]
作者:
look_w
时间:
2019-4-12 16:28
标题:
从LR到FFM\n(4)
FM——隐向量特征交叉
为了解决POLY2模型的缺陷,2010年Rendle提出了FM(Factorization Machine)。
从FM的目标函数的二阶部分中我们可以看到,相比POLY2,主要区别是用两个向量的内积(wj1 · wj2)取代了单一的权重wh(j1, j2)。具体来说,FM为每个特征学习了一个隐权重向量(latent vector),在特征交叉时,使用两个特征隐向量的内积作为交叉特征的权重。
通过引入特征隐向量的方式,直接把原先n2级别的权重参数数量减低到了nk(k为隐向量维度,n\u0026gt;\u0026gt;k)。在训练过程中,又可以通过转换目标函数形式的方法,使FM的训练复杂度减低到nk级别。相比POLY2极大降低训练开销。
隐向量的引入还使得FM比POLY2能够更好的解决数据稀疏性的问题。举例来说,我们有两个特征,分别是channel和brand,一个训练样本的feature组合是(ESPN, Adidas),在POLY2中,只有当ESPN和Adidas同时出现在一个训练样本中时,模型才能学到这个组合特征对应的权重。而在FM中,ESPN的隐向量也可以通过(ESPN, Gucci)这个样本学到,Adidas的隐向量也可以通过(NBC, Adidas)学到,这大大降低了模型对于数据稀疏性的要求。甚至对于一个从未出现过的特征组合(NBC, Gucci),由于模型之前已经分别学习过NBC和Gucci的隐向量,FM也具备了计算该特征组合权重的能力,这是POLY2无法实现的。也许FM相比POLY2丢失了某些信息的记忆能力,但是泛化能力大大提高,这对于互联网的数据特点是非常重要的。
工程方面,FM同样可以用梯度下降进行学习的特点使其不失实时性和灵活性。相比之后深度学习模型复杂的网络结构导致难以线上serving的问题,FM比较容易实现的inference过程也使其没有serving的难题。因此FM在2012-2014年前后逐渐成为业界CTR模型的主流。
欢迎光临 电子技术论坛_中国专业的电子工程师学习交流社区-中电网技术论坛 (http://bbs.eccn.com/)
Powered by Discuz! 7.0.0