一种应用于OFDM系统中的符号精确定时算法的FPGA实现
|

- UID
- 871057
- 性别
- 男
|

一种应用于OFDM系统中的符号精确定时算法的FPGA实现
摘要:OFDM技术是下一代移动通信的主流技术,在信息量大,功率受限的多媒体传感网的OFDM系统中,以突发模式传输数据,要求快速精确地完成定时同步。这里分析了一种应用于OFDM系统中基于长训练序列与本地序列互相关的精同步算法原理,同时给出了算法的FPGA设计方案,并在ISE中和FPGA测试板上进行验证。在实现的过程中,对传统实现方法进行了改进,对本地序列的位数进行截取符号位处理,并且对判决函数进行了近似处理。实现结果表明,该方法在不降低性能的前提下优化了系统资源损耗和运算速度,具有较好的工程实践价值。
关键词:OFDM;精确定时;同步算法;FPGA
0 引言
目前,正交频分复用(OFDM)技术成为多媒体传感器网络信息传输的主流研究方向,并越来越受到人们的关注。OFDM对于符号定时非常敏感,定时误差会造成符号间干扰(ICI),所以符号定时算法的研究在OFDM技术中是至关重要的。
定时同步算法通常分为基于非辅助数据的同步算法和基于辅助数据的同步算法。目前应用最广泛的基于导频的定时和频偏估计算法是由Schmidl提出的。这种算法采用相同的两段训练序列进行定时,该方法采用递推公式进行计算,实现复杂度很低,在OFDM系统中被广泛采用,然而这种方法的定时判决函数存在一个误差平台,会引起很大的定时偏差。为了减小定时判决函数的误差平台造成的影响,Minn对Schmidl的方法做出了一定的改进。Minn的定时判决函数是一个尖峰,在一定程度上消除了误差平台的影响;Park提出了一种定时判决函数更加尖锐的波形。但是由于循环前缀的存在,这种方法的判决函数有很大的旁瓣,在循环前缀较长时,几乎与主瓣的高度相同,在信噪比较低的情况下,很难得到正确的定时结果。采用训练序列与本地PN码互相关有明显的单峰值,但在频偏较大的情况下,定时判决函数会严重变形,引起较大的定时误差。
本文针对一种长短序列相结合的符号定时算法,给出了精确定时的FPGA设汁方案,并对该方法进行了FPGA实现。在实现的过程中,采用状态机、流水线等设计方法,优化了系统的资源和运算速度,增强了本设计的应用价值。
本文首先介绍了OFDM系统的帧结构,然后介绍了精同步的FPGA实现结构,并对实现结构进行了分析,最后对相关Matlab仿真结果进行了分析,并给出精同步FPGA的实现资源损耗报表。
1 OFDM数据帧结构
本文中OFDM系统参照目前广泛应用于无线局域网中的IEEE 802.11a标准,以突发模式传输数据,其数据帧前端的前导码用作同步,AGC,频偏估计。它的前导码结构如图1所示。前导码包括长训练序列和短训练序列两个部分。短训练序列分为10段,每段长度为32个抽样点;长训练序列分为2段,每段长度为128个抽样点,加上保护前缀,总长度为640个抽样点。前导码之后是数据部分。
2 精同步FPGA设计及分析
2.1 精同步FPGA设计
精同步用于信号的精确定时。本文假设系统已经完成粗频偏估计,系统的频偏在精同步能够容忍的范围内。该设计采用本地序列地与长训练序列相关的方法,由于本地序列不受噪声的影响,相关运算后,判决函数存在明显的单峰值,可进行精确定时。系统后续数据帧还有循环保护前缀和信道估计的处理,精同步的已经可以达到系统性能的要求。
本文从资源消耗角度出发,对传统方法进行了改进,在不降低系统性能的前提下优化了系统资源消耗。
精同步主要由本地相关器、累加器和阈值判决器三个模块组成,设计采用流水线的方式,实现结构如图2所示。
式中:r(n)表示输入数据;C(n)是与本地序列相关的相关值;P(n)表示信号的功率,用作信号能量的归一化。
本地相关器的实现是精同步的关键部分,本地相关器的实现中需要用到复数乘法器,本文采用的复数乘法算法如式(5)所示:

由于精同步是与本地序列相关,不存在递推公式,为了降低资源损耗,在选取本地序列时,仅截取实部和虚部的符号位,即每个本地序列的实部和虚部仅用-1,0,1表示,这样每个复数乘法可以转换成加法。
本文对判决函数的计算方法进行了改进,式(3)是对|C(n)|进行一阶泰勒展开,只取0次项与1次项作为|C(n)|的近似结果。
在峰值检测时,本文采用乘法代替除法进行门限判定,门限判决函数如式(6)所示:
|C(n)|>gate*P(n) (6)
达到门限判定条件时,精捕获成功,并通过计数的方式找到FFT窗的位置,完成定时同步。
2.2 FPGA设计方案资源消耗分析
与传统方法相比,本文提出的方案在资源消耗上大大降低,主要体现在以下几个方面:
(1)在本地相关器的实现上。式(5)表明,每次复数乘法运算只需要进行3个乘法运算,节省了1个乘法资源。在进行相关运算时,传统方法在计算每个相关值时需进行384个乘法运算,在本文中,由于实部和虚部都只用符号位表示,乘法器可以用数据选择器与加法器实现,大大节省了乘法器资源。
(2)在判决函数的计算上。传统方法每计算一个判决函数的值,需要进行4个乘法,2个加法计算。本文提出的近似方法中,每次判决函数的计算只需要2次乘法,2次加法,1次比较与1次移位操作,节省了乘法器资源。
(3)在硬件实现时。除法器对资源消耗非常大,本文用比较容易实现的乘法代替传统方法中的除法运算,节省了系统资源。
当然,本文对资源的优化是因为采取了一定的近似处理和截位处理,会带来一定的量化误差,在一定程度上会降低系统的性能,但仿真结果表明,这种性能的损失在可接受范围内。
3 仿真及实现
3.1 仿真结果
利用本地序列截取符号和判决函数的近似对改进方案进行了仿真。该系统中,给定子载波数为N=128,码速率定为Rb=5 Mb/s,子载波间隔为19.2 kHz,数字调制采用QPSK,信道模型选用AWGN模型,设定信噪比为5 dB。
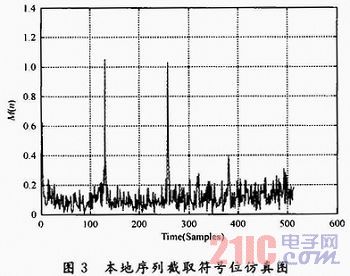
图3是采用本地序列截取2 b的判决函数M(n)的Matlah仿真图;图4是采用本地序列截取4 b的Matlab仿真图。检测峰值时,第一个峰值是由于循环前缀存在的影响,峰值检测时检测第二个峰值。
从图3,图4中可以看出,截位虽然会损耗算法的性能,但是判决函数存在明显峰值,选择适当的阈值时,仍然可以精确定时同步,可见减少本地序列的精度对性能并未造成很大的影响。
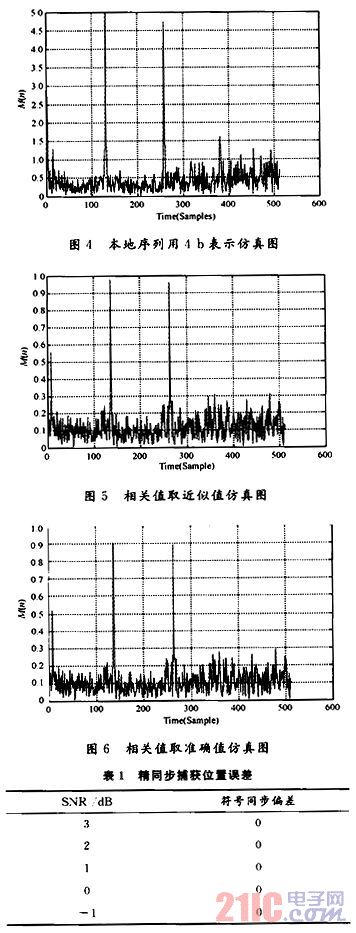
图5是采用判决函数取近似值的Matlab仿真图,图6是判决函数取确定值的Matlab仿真图。检测峰值时,第一个峰值是由于循环前缀存在的影响,峰值检测时检测第二个峰值。从图5,图6中可以看出,在判决函数近似处理虽然会损耗算法的性能,但是判决函数仍然存在明显峰值,选择适当的阈值时,仍然可以精确定时同步,可见减少对判决函数的近似对性能并未造成很大的影响。
表1是在AWGN环境下精同步位置的仿真结果,每个信噪比下经过5 000帧的仿真。符号同步偏差表示每个信噪比下的精同步平均错误长度,可见在系统的性能并未明显降低。
3.2 精同步模块实际实现
硬件设计是基于XLINX公司的SPRTAN6系列中的XC6SLX150-2FGG484芯片,采用Verilog HDL语言,仿真软件是ISE自带的ISIM,开发环境是ISE。
整个OFDM系统同步的ISIM仿真波形如图7所示。其中:clk_i表示时钟信号;reset_i表示同步复位信号;clk5M_en_i表示5 MHz时钟使能信号;nrst_j表示异步复位信号;acq_val_o表示粗捕获指示信号;dataI_o,dataQ_o表示经过粗捕获和粗频偏估计的输出信号;
sync_val_o表示精同步指示信号。

经过ISE综合后,改进前和改进后精同步占用资源分布如表2所示。

由表2可见本文对系统资源优化的效果十分明显。
4 结语
本文分析了一种OFDM系统精同步算法的原理,给出了FPGA硬件实现方案和结果分析,该方案在采用经典算法的同时,对算法进行了改进,在不降低精同步性能的前提下大大降低了计算复杂度,并且设计结构简单,易于实现,具有较好的工程实用价值。a |
|
|
|
|
|


