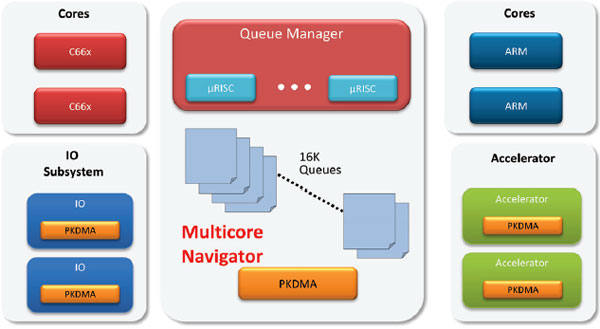
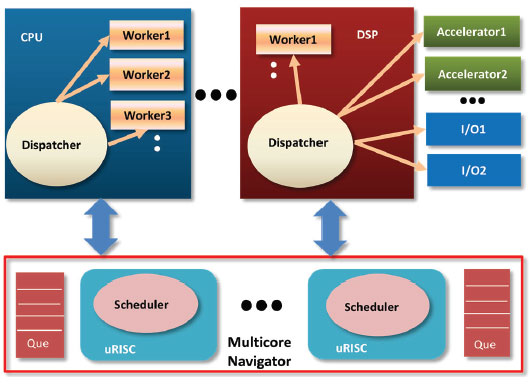
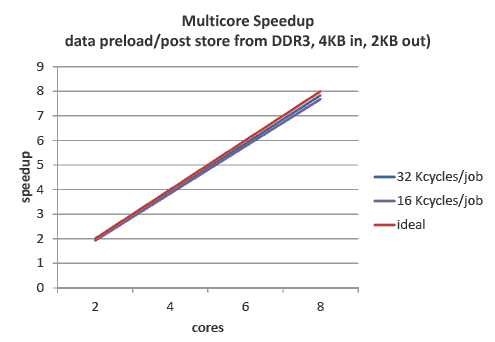
TI Navigator Runtime 帮助提升多核处理器效率
|
论坛元老
|
 TI Navigator Runtime 帮助提升多核处理器效率
|
|
|
论坛元老
|
TI Navigator Runtime 帮助提升多核处理器效率
|
|
中电网 ( 粤ICP备17063136号-2)|联系我们 |论坛统计|Archiver|WAP|
GMT+8, 2025-6-22 07:38, Processed in 0.063891 second(s), 7 queries, Gzip enabled.
Powered by Eccn! 7.0.0
© 2001-2014 ChinaECnet Inc.