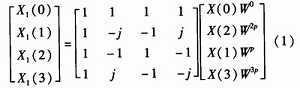FFT(快速傅里叶变换)是一种非常重要的算法,在信号处理、图像处理、生物信息学、计算物理、应用数学等方面都有着广泛的应用。在高速数字信号处理中,FFT的处理速度往往是整个系统设计性能的关键所在。FPGA(现场可编程门阵列)是一种具有大规模可编程门阵列的器件,不仅具有ASIC(专用集成电路)快速的特点,更具有很好的系统实现的灵活性。基于FPGA的设计可以满足实时数字信号处理的要求,在市场竞争中具有很大的优势。因此,FPGA为高速FFT算法的实现提供了一个很好的平台。
1 FFT算法的硬件实现
1.1系统框图
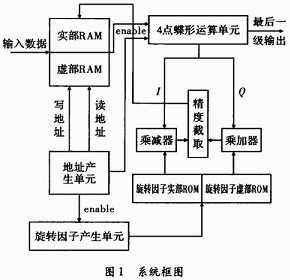
本设计利用流水线技术来提高系统的性能,系统框图,如图1所示。其中,地址产生单元生成RAM读写地址,写使能信号以及相关模块的启动、控制信号,是系统的控制核心;4点蝶形运算单元的最后一级输出不是顺序的;旋转因子产生单元生成复乘运算中的旋转因子的角度数据;旋转因子ROM中预置了每一级运算中所需的旋转因子。

在FPGA设计中,为提高系统的运行速度,而将指令分为几个子操作,每个子操作由不同的单元完成,这样,每一级的电路结构得到简化,从而减少输入到输出间的电路延时,在较小的时钟周期内就能够完成这一级的电路功能。在下一个时钟周期到来时,将前一级的结果锁存为该级电路的输入,这样逐级锁存,由最后一级完成最终结果的输出。也就是说,流水线技术是将待处理的任务分解为相互有关而又相互独立、可以顺序执行的子任务来逐步实现。本设计中,4点蝶形运算单元、旋转因子复乘模块以及最后的精度截取模块采用流水线技术来处理。
1.2基4蝶形运算算法原理

式(1)为基4蝶形运算单元的一般表达式,其中 ,,N为FFT运算的点数,本设计中为1 024,p为旋转因子W的相位角,其规律将在1.4节讨论。X(0)、X(1)、X(2)、X(3)为原始数据,顺序输入RAM后蝶形倒序输出,与旋转因子复乘再进行4点蝶形运算,而X1(0)、X1(1)、X1(2)、X1(3)即为第1级蝶形运算的结果。此时RAM存储的原始数据已经清空,将第1级蝶形运算结果再存回RAM中,按照一定的地址输出后,与第2级的旋转因子复乘、4点蝶形运算,得到第2级蝶形运算结果,依此类推。由于蝶形运算为同址操作,所以第2级的RAM写地址即为第一级的RAM读地址,每一级的RAM读地址规律将在1.3节中讨论。 ,,N为FFT运算的点数,本设计中为1 024,p为旋转因子W的相位角,其规律将在1.4节讨论。X(0)、X(1)、X(2)、X(3)为原始数据,顺序输入RAM后蝶形倒序输出,与旋转因子复乘再进行4点蝶形运算,而X1(0)、X1(1)、X1(2)、X1(3)即为第1级蝶形运算的结果。此时RAM存储的原始数据已经清空,将第1级蝶形运算结果再存回RAM中,按照一定的地址输出后,与第2级的旋转因子复乘、4点蝶形运算,得到第2级蝶形运算结果,依此类推。由于蝶形运算为同址操作,所以第2级的RAM写地址即为第一级的RAM读地址,每一级的RAM读地址规律将在1.3节中讨论。
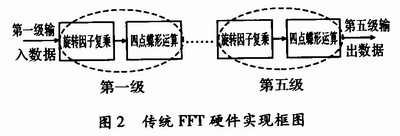
1024点的基4-FFT共需要5级蝶形运算,每级需要计算256个蝶形,其传统实现框图如图2所示。

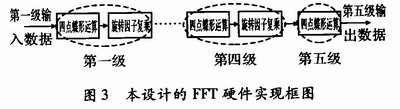
考虑到第一级蝶形运算不需要旋转因子,所以第一级的旋转因子复乘模块可以省略,但本设计的硬件结构需要循环利用,一般情况下,可以对第一级数据进行×1运算,再进行4点蝶形运算。不过,考虑到我们并不关心每一级蝶形运算后的结果,本文提出了一种蝶形运算的新结构:即先进行前一级的4点蝶形运算,再进行本级的与旋转因子复乘运算,如图3所示。

可以看出,图3减少了一个旋转因子复乘模块,不但节约了一次乘法运算时间,也省略了第一级旋转因子,更好地利用了硬件结构。
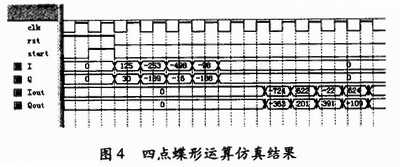
首先,在QuartusⅡ环境中对4点蝶形运算时序仿真,采用流水线设计,连续输入连续输出,仿真结果如图4所示。

由图4可以看出,输出比输入延时6个时钟,这在系统的控制核心地址产生单元的设计中需要考虑到。
1.3地址产生与时序控制
对于1 024.点基4 FFT运算,需要5级蝶形运算,每一级运算都要有写地址和读地址,根据FFT同址运算的特点可知,当前的写地址即是上一级蝶形运算的读地址。因此完成FFT运算需要设计6级RAM地址。其中第1级的写地址即是数据输入的顺序地址,不予讨论。最后一级读地址为数据正序输出所需的地址。其余4级为1 024点数据对应的FFT蝶形运算。
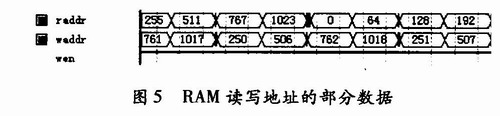
第一级读取节点地址的顺序应该是:(0,256,512.768),(1,257,513,769),……,(255,511.767,1 023)。易观察其读地址的规律如下:设读取次序的二进制编码为bit[9:0];则读地址的二进制编码为{bit[1:O],bit[9:2]},并且依次可以推出第2、3、4级的读地址二进制编码分别为{bit[9:8],bit[1:0],bit[7:2]},{bit[9:6],bit[1:0],bit[5:2]}、{bit[9:4],bit[1:0],bit[3:2]},而最后一级输出数据的地址二进制编码则为:{bit[1:0],bit[3:2],bit[5:4],bit[7:6],bit[9:8]}.图5给出了第1级读地址和第2级读地址的部分数据,也可以看出第2级的写地址即是第1级的读地址。
 |