大热的麦克风阵列语音识别系统的设计和轻松实现,提供软硬件解决方案
|

- UID
- 863084
|
大热的麦克风阵列语音识别系统的设计和轻松实现,提供软硬件解决方案
摘要:
在非近距离语音识别中,由于衰减、干扰、混响等因素的影响,使语音识别率显著降低。使用麦克风阵进行语音识别的好处是通过提高信噪比来提高语音识别率。而本项目与传统的麦克风阵进行语音识别的方法又有不同,它将语音接收端与语音识别部分组成一个反馈系统,通过优化接收端滤波器的系数,使跟语音识别密切相关的倒谱域似然比最大,来提高语音识别准确率。在进行Matlab仿真之后,将算法应用到FPGA中。FPGA开发板暂定为Xilinx公司的Nexys 3 Spartan-6 FPGA Board。
1、研究方案
1.1 总统研究方案
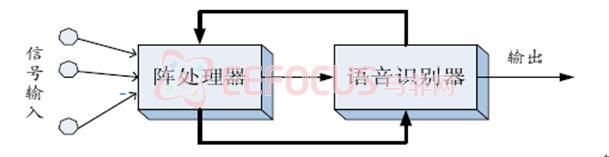
当前基于隐马尔可夫模型(HMM)的麦克风阵语音识别系统,主要包括阵列信号处理和特征识别两个阶段,原理图如图1.1所示:
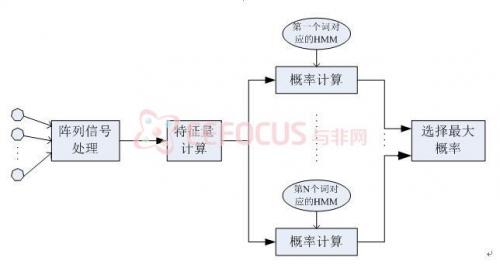
图1.1 基于HMM的麦克风阵语音识别系统结构
其中前端的阵处理主要是为了进行语音增强,目的是在提取语音参数之前,尽量减小信号波形的失真。这一做法基于的假设是,对波形质量得到改善的信号进行特征识别能够提高识别性能,即先后单独进行阵处理和特征识别操作,如图1.2所示:
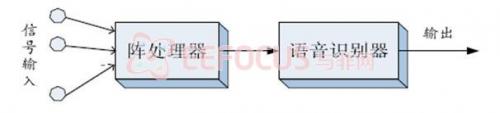
图1.2 常规的麦克风阵语音识别系统框架
本项目采用的处理方法,对阵元接收的信号进行滤波求和,其目的并不是为了改善信号波形质量,而是在于直接提高识别过程中正确假设的似然概率,进而提高识别率。这一方案需要将阵处理和识别过程联合起来考虑,框架如图1.3所示:
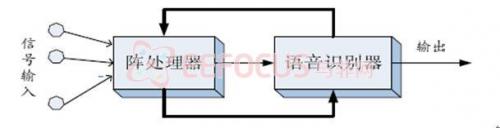
图1.3 结合识别过程进行阵处理的语音识别系统框架 |
|
|
|
|
|