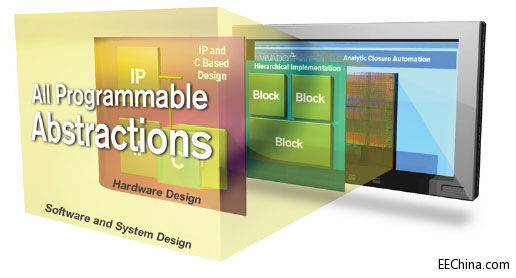
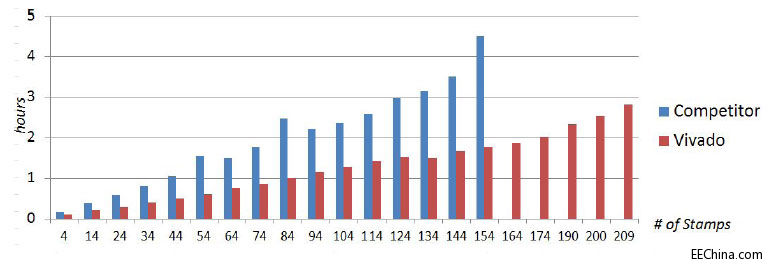
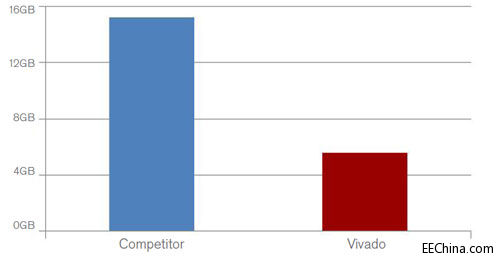
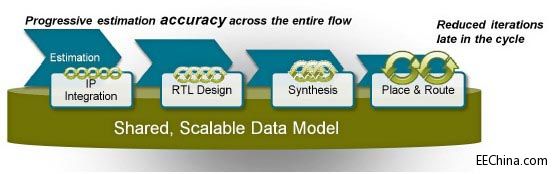
Vivado设计套件提供了业界一流的系统功耗分析与优化工具。从架构或器件选择阶段开始,设计人员就可以运用准确且易用性无与伦比的Xilinx Power Estimator(XPE,赛灵思功耗评估器)电子数据表来确定系统功耗。设计人员不仅能够通过XPE的快速 评估(Quick Estimate)和IP向导轻松入门,而且还能够简单并排比较多种实现方案,帮助设计团队微调设置,以便地为各种场景精确建模。
发挥整套Vivado设计套件的功能,将生成的IP硬核轻松嵌入基于RTL的设计流程中;发挥Vivado System Generator for DSP的功能,将生成的IP硬核轻松嵌入基于模型的设计;发挥Vivado IP集成器(Vivado IP Integrator)的功能,将生成的IP硬核轻松集成到基于模块的设计。
如上文所述,Vivado设计套件系统版本提供System Generator for DSP,这是一款行业领先的将DSP算法转换为高性能生产质量级硬件的高级设计工具,转换所需时间仅为传统RTL设计方法的几分之一。Vivado System Generator for DSP可让开发人员运用业界最先进的All Programmable系统建模工具(MathWorks®提供的Simulink™和MATLAB™),无缝集成那些可用Vivado HLS综合到硬件中的算术函数、SmartCORE™与LogiCORE™ IP、定制RTL以及基于C语言的模块,从而加速高度并行系统的开发。图7所示的是使用Vivado HLS和Vivado System Generator for DSP将基于C语言的模块集成到Simulink中的设计流程。
图7:使用Vivado HLS和Vivado System Generator for DSP将基于C语言的模块集成到Simulink中
Vivado System Generator for DSP提供自动定点/浮点硬件生成功能、可将Simulink仿真速度提高1000倍的硬件协同仿真功能、用于基于RTL的Vivdo设计流程的系统集成功能,以及用Vivado IP集成器实现的基于模块的设计功能,可进一步加快系统实现。
工作在接口层面的设计团队可以快速组装采用Vivado HLS与Vivado System Generator for DSP创建的IP、赛灵思SmarteCORE与LogiCORE IP、联盟成员IP和专有IP的复杂系统。结合使用Vivado IP集成器和Vivado HLS可显著降低开发成本,仅为使用RTL方法的1/15。
图8显示的是系统级设计在Vivado IP集成器中的视图,这个系统采用了一个赛灵思Zynq-7000处理系统、Vivado HLS生成的图像滤波器加速器和一个用Vivado System Generator for DSP生成的增益控制加速器。
Zynq-7000处理系统 Vivado HLS生成的图像滤波器加速器
System Generator生成的增益控制加速器
图8:用Vivado HLS和System Generator加速器完成的Zynq设计