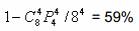1.3.3 地址偏移的考虑
地址偏移会显著地影响EDMA 的吞吐量。
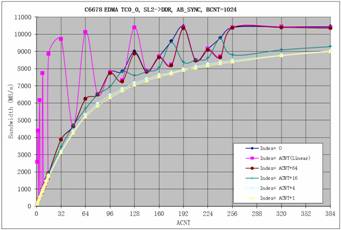
图 9说明了地址偏移对EDMA 吞吐量的影响,它是在1GHz C6678 EVM(64-bit 1333MTS DDR)上从 SL2 到 DDR 传输1024 行(BCNT= 1024) 2D 数据时测得的。
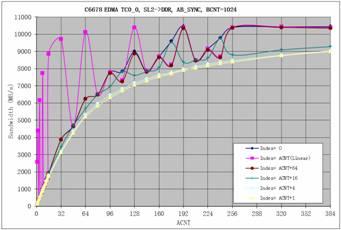
图9 偏移量对EDMA 带宽的影响
从测试结果可以看出,线性传输 (Index= ACNT)能充分利用带宽;其它Index 设置会降低EDMA性能。最坏的情况是地址偏移为奇数时。如果地址偏移大于8 并且是2 的幂次方,性能的下降则比较小。
请注意,Index= ACNT,并且ACNT 是2 的幂次方时,2D 传输被优化为1D 传输,因此性能比其它情况好很多。
除非特殊说明,本文列出的所有性能数据都是在Index= ACNT 的情况下测得的。
1.3.4 地址对齐
地址对齐对EDMA 效率稍有影响。EDMA3 缺省突发数据块大小是64 bytes 或128 bytes,如果传输跨越64 或128 bytes 边界,EDMA3 TC 会把大小为ACNT 数据块分割成64 或128 bytes 的突发数据块。这对1~256 bytes 的数据传输影响会比较明显,而对更大块数据的传输的影响则不明显。
除非特殊说明,本文所有性能数据都是在地址对齐的情况下测得的。
2. 多个主模块共享存储器的性能
由于C6678 有8 个核和很多DMA 主模块,它们可能会同时访问存储器。本节讨论多个主模块共享存储器的性能。
2.1 多个主模块共享SL2 的性能
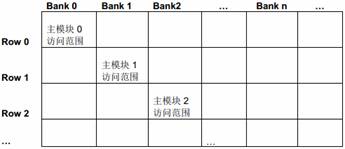
图10 列出了数据在SL2 中的组织结构。

图10 SL2 bank 组织结构
所有主模块都可以通过MSMC (Multicore Shared Memory Controller)独立地访问4 个SL2 bank中的任一个。多个主模块可以并行地访问不同的bank;如果多个主模块要同时访问相同的bank,那就需要根据优先级仲裁。
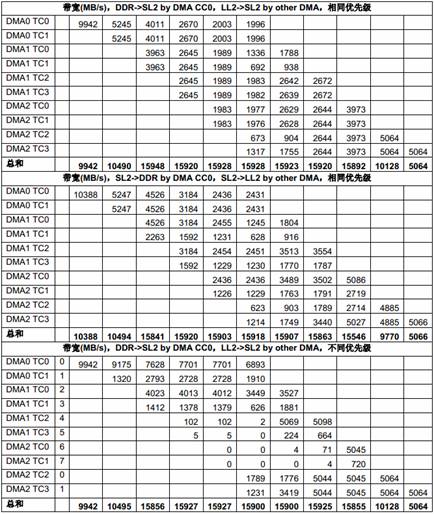
表8 列出了在1GHz C6678 上测得的多个主模块同时访问SL2 的性能数据。每个主模块反复访问自己在SL2 中的数据buffer,在相同的时间内(大概2 秒),每个主模块传输的数据量被统计;而每个主模块获得的带宽则由数据量除以时间计算出来。
在这个测试中,每个核的L1D cache 大小是32KB,没有使用L2 cached,prefetch buffer 被使能。
在下面的表中,每列是一个测试场景的结果,不同测试场景的主要区别是同时访问存储器的主模块的个数,格子中的数据代表相应的主模块在这个测试场景下获得的带宽,一列中的空格代表对应的主模块在这个测试场景下未被使用。最后一行中的数据是在这个测试场景下所有主模块获得的带宽的总和。
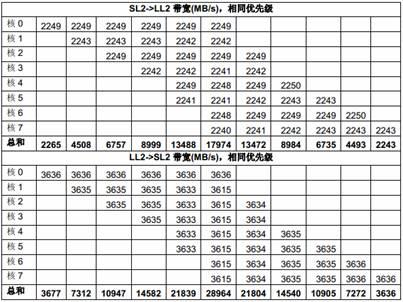
表8 多个DSP 核共享SL2 的性能
以上测试结果证明SL2 不会成为多个DSP 核同时访问的瓶颈。SL2 有足够的带宽 (500M x 32 x 4 = 64000MB/s)来支持所有DSP 核的同时访问。每个DSP 核的吞吐量受限于它自己。
由于SL2 的带宽足够支持所有核同时访问,所以核的优先级在这种情况下基本不起作用。
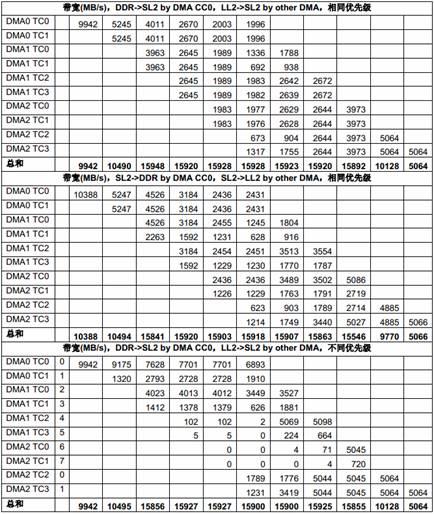
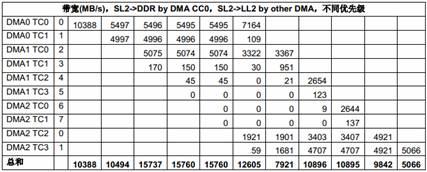
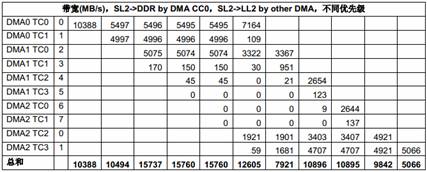
表9 多个EDMA 共享SL2 的性能
由于总共有10 个EDMA TC,而只有8 个DSP 核,在这些测试里,8 个TC 在SL2 和8 个核的LL2 之间传输数据,另两个TC 则在SL2 和DDR 之间传输数据。
尽管SL2 本身的带宽非常高,但所有EDMA 访问SL2 时都需要经过内部总线交换网络的一个相同的端口,这个端口就成了这种情况下的瓶颈。这个端口的理论带宽是500MHz x 32 bytes = 16000MB/s。如果所有EDMA 传输的优先级相同,带宽会在这些传输之间平均分配。而当优先级不同时(上表中第二列是每个主模块的优先级),优先级低的EDMA 传输得到的带宽比较小。对负载很高的情况下,一些低优先级的传输可能会被“饿死”,也就是说,得到的带宽为0。
根据Table 6中列出的不同EDMA TC 的区别,EDMACC1 TC1 和TC3,EDMACC2 TC1 和TC2在某些情况下获得的带宽会比其它TC 小,即使优先级相同。
2.2 多个主模块共享DDR 的性能
多个主模块同时访问DDR 时,DDR 控制器会根据主模块的优先级进行仲裁。
C6678 的DDR 控制器支持包含1,2,4,或8 个banks 的DDR 存储器。现在大多数DDR3 存储器都包含8 个bank,以C6678 EVM 上的DDR 存储器为例,它的组织结构如图11 所示。请注意,对不同的DDR 存储器,每一行的大小可能会不同。

图11 DDR bank 数据组织结构
尽管DDR 存储器有多个bank,但与SL2 的bank 不同的是,它们并没有独立的总线与控制器相连,而是共享相同的总线接口。所以,DDR 存储器bank 的个数并不直接的影响带宽,但它却显著的影响多个主模块共享DDR 的效率。
DDR SDRAM 的访问以行或页为基础。一个主模块在访问某个页中的数据之前,这一页必须首先被“打开”,然后这一页中的内容才可以被随意访问。如果主模块想访问同一个bank 中另一页中的数据,必须先关闭原先的页,然后打开新的一页。而页切换(关闭/打开)操作需要消耗额外的时钟周期。
每个bank 只可以有一页被打开,DDR 存储器的bank 数越多,页切换的概率就越小。例如,一个主模块在访问了bank0 的0 页后,它可以访问bank1 的1 页而不用关闭之前访问的bank0 的0页,然后这个主模块可以自由的在这两页之间访问而不会产生页切换。包含8 个bank 的DDR 存储器可以有8 页同时被打开。
为了测试页切换的影响,我们定义了两种测试的数据结构。
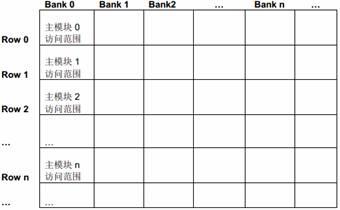
图12 多个主模块访问相同DDR bank 的不同页
上面的情况是最坏的情况,页切换的额外开销被最大化。每换一个主模块访问就会导致一次页切换。
下面的情况则是最佳情况,每个主模块始终访问打开的页,而不会有任何页切换发生。
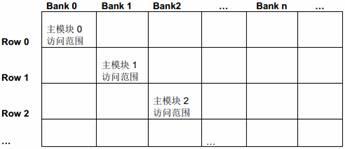
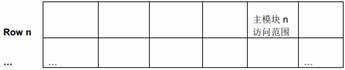
图13 多个主模块访问不同DDR bank 的不同页
2.2.1 多个DSP 核共享DDR 的性能
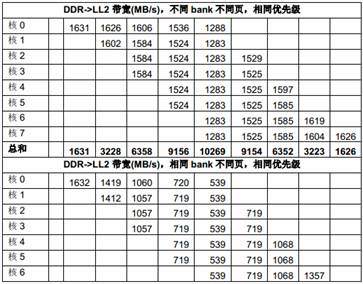
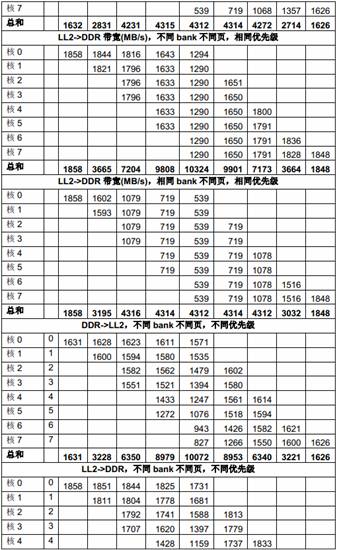
下面的表格列出了不同场景下多个DSP 核共享1GHz C6678 EVM 上64-bit 1333MTS DDR 的性能。每个主模块反复访问自己在DDR 中的数据buffer,在相同的时间内(大概2 秒),每个主模块传输的数据量被统计;而每个主模块获得的带宽则由数据量除以时间计算出来。
在这些测试中,DDR 是cacheable 且prefetchable 的,L1D cache 是32KB,L2 cache 是256KB,prefetch buffer 被使能。我们没有测试Non-cacheable 的情况是因为Non-cacheable 情况下每个核需要的带宽比cacheable 的情况下要少很多。
在下面的表中,每列是一个测试场景的结果,不同测试场景的主要区别是同时访问存储器的主模块的个数,格子中的数据代表相应的主模块在这个测试场景下获得的带宽,一列中的空格代表对应的主模块在这个测试场景下未被使用。最后一行中的数据是在这个测试场景下所有主模块获得的带宽的总和。
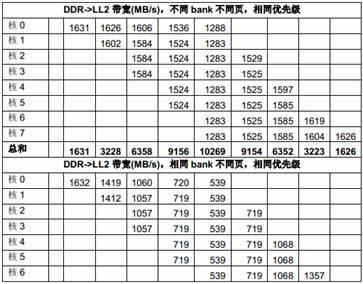
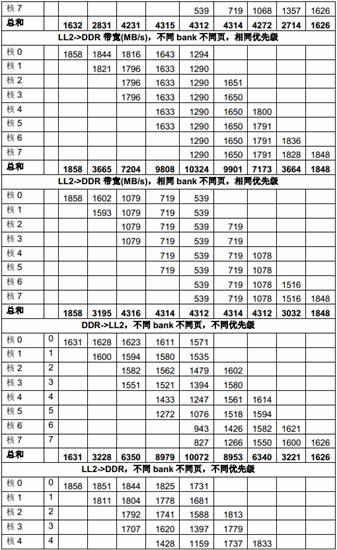

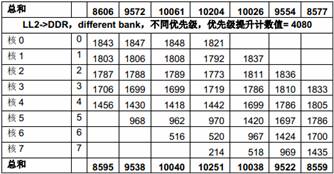
表10 多个DSP 核共享DDR 的性能
从上面的测试结果可以看出,多核同时访问相同DDR bank 中不同页的性能比多核同时访问不同DDR bank 中不同页的性能差很多,原因就是页切换的额外开销。
从上面的测试结果还可以看出,DDR 的带宽 (1333 x 8 = 10666MB/s)对所有DSP 核同时访问来说是不够的,DSP 核的优先级对它获得的带宽有明显影响。当优先级相同时,带宽在多个核之间平均分配;而当优先级不同时(上表中第二列是每个主模块的优先级),优先级低的核得到的带宽比较小。
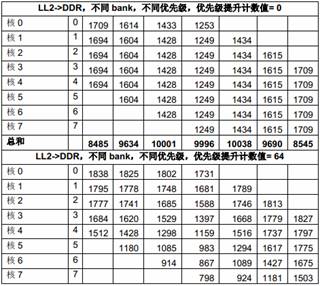
为了防止低优先级的主模块被“饿死”,DDR 控制器提供了老请求优先级临时提高的功能。我们可以通过配置一个计数器,当一个老的请求的等待时间超过这个计数值时,它的优先级会被临时提高。如果没有特殊说明,本文所有测试中这个计数周期都被配置成4x16=64 个DDR3CLKOUT 时钟周期。在64 个DDR3CLKOUT 时钟周期内,可以传输64x2x8=1024 bytes。
表11 是在1GHz C6678 EVM(64-bit 1333MTS DDR)上用不同的优先级提升计数值测得的数据。表中第二列是每个主模块的预设优先级。
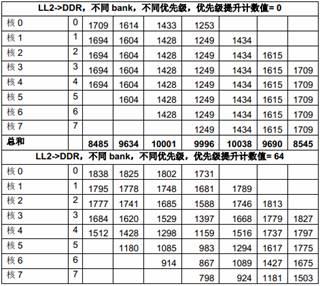
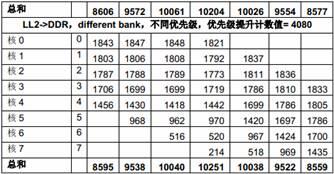
表11 DDR 优先级提升计数值的影响
从上面的测试结果可以看出,优先级提升计数值=0 实际上使得预设的优先级不起作用。当这个计数值越大是,预设的优先级起的作用越大。所以,在实际应用中,设计者需要根据应用的需求来选择一个合适的值。
2.2.2 多个EDMA 共享DDR 的性能
下面的表格列出了不同场景下多个EDMA TC 共享1GHz C6678 EVM 上64-bit 1333MTS DDR 的性能。

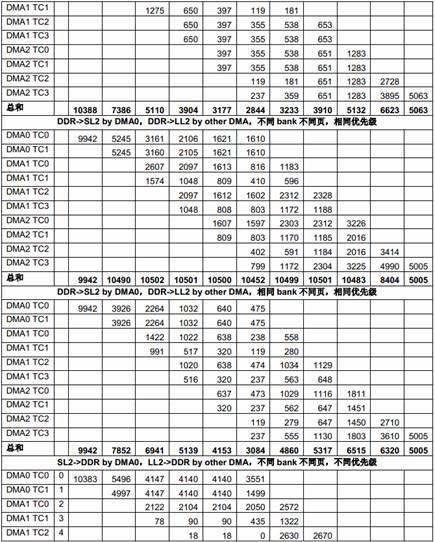
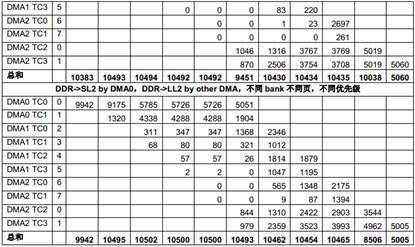
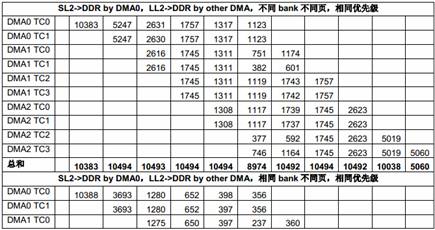
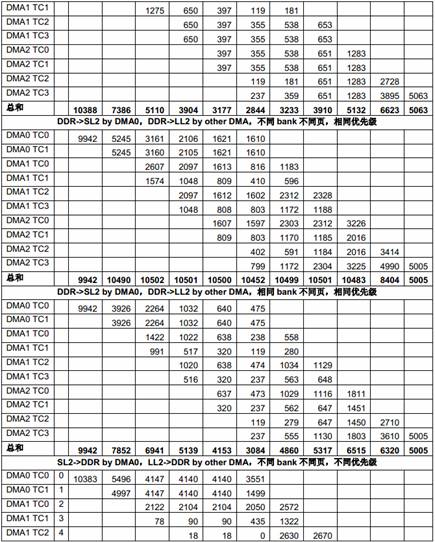
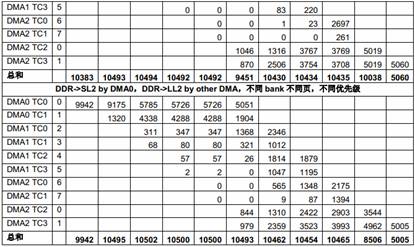
表12 多个EDMA 共享DDR 的性能
由于总共有10 个EDMA TC,而只有8 个DSP 核,在这些测试里,8 个TC 在DDR 和8 个核的LL2 之间传输数据,另两个TC 则在DDR 和SL2 之间传输数据。
从上面的测试结果可以看出,DDR 的带宽 (1333 x 8 = 10666MB/s)对所有EDMA 同时访问来说是不够的,EDMA TC 的优先级对它获得的带宽有明显影响。优先级低的EDMA 传输得到的带宽比较小。对负载很高的情况下,一些低优先级的传输可能会被“饿死”,也就是说,得到的带宽为0。
根据Table 6中列出的不同EDMA TC 的区别,EDMACC1 TC1 和TC3,EDMACC2 TC1 和TC2在某些情况下获得的带宽会比其它TC 小,即使优先级相同。
从上面的测试结果还可以看出,多个DMA 同时访问相同DDR bank 中不同页的性能比多个DMA同时访问不同DDR bank 中不同页的性能差很多,原因就是页切换的额外开销。当DDR 负载加重时结果变得更差。最坏的情况下,页切换的额外开销会占用整体传输时间的绝大部分,从而使总吞吐量急剧下降。
页切换的概率,也就是,多个主模块访问相同DDR bank 的概率取决于同时访问的主模块的个数和DDR bank 个数。例如,4 个DMA 随机访问8 个bank 的DDR 存储器,至少两个TC 访问相同的bank 的概率是:
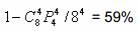
表13 列出了理论上,多个主模块访问相同bank 的概率:

表13 多个主模块访问相同bank 的概率
为了减少DDR 页切换次数,如果有多个传输,有的要访问已经打开的页,有的要访问没有打开的页,C6678 的DDR 控制器一般情况下会让对已经打开的页的访问先执行。
3. 总结
总的来说,DSP 核可以高效地访问内部存储器,而用DSP 核访问外部数据则不是有效利用资源的方式;IDMA 非常适用于DSP 核本地存储器(L1D,L1P,LL2)内连续数据块的传输,但它不能访问共享存储器(SL2, DDR);而外部存储器的访问则应尽量使用EDMA。 为了充分利用cache,DSP 核应尽量连续访问。
EDMA 的ACNT 越大,效率越高。
SL2 有足够的带宽来支持所有核的同时访问。DDR 的带宽对所有核同时访问来说是不够的,DSP核的优先级对它获得的带宽有明显影响。
DDR 性能受页切换的影响很大,为了减少DDR 页切换应该尽量每次访问大块数据。 |