首页
|
新闻
|
新品
|
文库
|
方案
|
视频
|
下载
|
商城
|
开发板
|
数据中心
|
座谈新版
|
培训
|
工具
|
博客
|
论坛
|
百科
|
GEC
|
活动
|
主题月
|
电子展
注册
登录
分栏模式
论坛
博客
搜索
帮助
导航
默认风格
uchome
discuz6
GreenM
»
工业控制
» TMS320C6678处理器的VLFFT演示
返回列表
回复
发帖
发新话题
发布投票
发布悬赏
发布辩论
发布活动
发布视频
发布商品
TMS320C6678处理器的VLFFT演示
发短消息
加为好友
porereading
当前离线
UID
863084
帖子
7183
精华
0
积分
3592
阅读权限
90
在线时间
209 小时
注册时间
2011-11-30
最后登录
2019-8-28
论坛元老
UID
863084
1
#
打印
字体大小:
t
T
porereading
发表于 2015-9-16 20:55
|
只看该作者
TMS320C6678处理器的VLFFT演示
处理器
,
白皮书
,
电子战
,
检测
,
军事
简介
本白皮书探讨了TMS320C6678
处理器
的VLFFT演示。通过内置8个固定和浮点DSP内核的TMS320C6678处理器来执行16K-1024K的一维单精度浮点FFT算法样本,
检测
其分别在采用1,2,4或8核时各自的运行时间。演示的结果证明了C66X DSP内核的优异性能,以及TMS320C6678处理器跨多核平行化执行性能与内核数量成正比的特性。本文的演示采用FFT算法,该算法在诸如医学成像、
通信
、军事和商业雷达以及
电子
战(干扰器、抗干扰器)等
领域
中被频繁
应用
。本文演示结果显示,在运行速率为1 GHz,DSP内核为8个时,用TMS320C6678处理器执行1024K的FFT算法样本只需要6.4毫秒。
TMS320C6678 SoC
TMS320C6678处理器具有8个DSP内核,是基于TI的C66x 固定和浮点DSP内核以及 TI享有多核权利的创新型KeyStone构架创建的。它运行速度最高可达1.25GHz,在这个速度下它可以进行每秒160千兆次浮点运算,
而且
通常情况下消耗的电能不到10w。TMS320C6678处理器的特色是它每一个DSP内核都有512KB的 L2内存;此外,8MB的
芯片
内存中有4MB的共享内存,并且这两个内存都有纠错码。它的DDR3界面是64位的,有8位纠错码,运行速度可以高达每秒1600兆比特,同时支持高达8GB的外部
存储器
数据存取。此外,TMS320C6678的配套外设包括PCle、Serial RapidIO® 、Gigabit Ethernet以及TI的HyperLink界面,这个界面在连接到TI的其他DSP,ARM, ARM+DSP处理器以及第三方的FPGA时可以提供高达50Gbps的连接速度。
在本文的VLFFT演示中,TMS320C6678处理器运行速度为1GHz,DDR3界面传输速度为1333MHz。
图一:TMS320C6678框图
VLFFT演示
由于VLFFT算法要求将输入的数据存放在处理器的外部存储器当中,在本演示过程中,数据通过DSP内核存取、分配和处理,最后将结果输出到外部存储器中。同时,在整个过程中始终保持循环计数和时间
测量
。演示时,为TMS320C6678处理器配置不同数量的内核(1,2,4或8个)来计算当FFT大小不同时的结果,这些FFT规格包括:
• 16K
• 32K
• 64K
• 128K
• 156K
• 512K
• 1024K
在演示过程中,通过将计算负载分布到多个核和完全充分利用C66X DSP内核高性能计算
能力
的方法来确保执行FFT达到最大性能。同时运用基础时间抽取算法将一维VLFFT算法用类似的二维FFT算法来表达。这种方法是在遇到非常大的数据N时,分解成N=N1*N2的形式。在本演示过程中,如果一维输入数组非常大,就采用N1行*N2列的二维数组来表示,然后通过以下步骤来计算FFT:
1. 计算N2列数组在N1行数组中不同大小时的FFT;
2. 乘以旋转因子;
3. 存储N2 列在N1行不同大小时FFT算法的结果,形成一个N2*N1的二维数组;
4. 计算N1行数组在N2列数组中不同大小时的FFT;
5. 存储列方向上的数据形成N2*N1二维数组。
这个算法被Takahashi称为Hitachi SR8000的高性能平行FFT算法。
在执行多核算法时,第一步是计算N2列(核的数量)在N1行规格下的FFT算法,第四步是计算N1行(核的数量)在N2列规格下的FFT算法。0核是主核,负责与所有剩下的附属核同步。根据N1数组和N2数组的大小,每一个内核计算出来的FFT总数都被分成几个较小的模块以适应每个核L2 SRAM内存的
空间
。每一组数据都通过外部存储器中的DMA 预取到L2 SRAM内存中,然后通过DDR将数据返回到外部存储器中。每个核都运用2个DMA
通道
在外部存储器(DDR3)和内部存储器(L2 SRAM)中转化输入和输出的数据。
结果
下页图表1展示了TMS320C6678评估版(TMDSEVM6678LE)分别在一个DSP周期和一个毫秒单位时间内运行FFT代码的结果。在理想状态下,当用于计算的内核数量增加一倍,循环计数就会减少一半。但在现实中,由于存在
信息
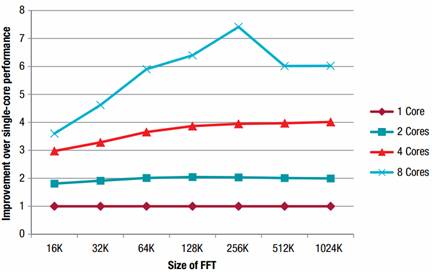
运行的天花板,同时受限于内存大小和信息宽度(内部存储器),这种情况很难实现。在这种情况下,当用双核取代单核时,运行FFT的时间平均减少了49.3 %,基本达到了理想的周期数的一半。当用四核替代一核时,运行FFT的时间平均减少了72.5%,而采用八核时平均运行时间则减少了81.6%。
表格一:FFT分别在1/2/4/8DSP核时周期及毫秒的结果
由此我们可以看出,无论是双核还是四核,随着FFT的大小从16k增加到256k,运行时间减少的幅度也越来越大,而采用八核时运行时间减少的幅度更加剧烈。这是因为对于较小的FFT,核数越多,并行代码相对于额外增加核数来提高性能的代价要小很多。以前256KB的FFT,在提高性能方面的效果并不太理想,在双核时只能提高2倍,四核时也只有4倍,而在八核时反而会降低其性能。这是由于八核处理数据的速度远高于外部存储器传输数据的速度,从而使其存储空间到达上限导致的。在本演示中,计算一个大小为1024k的FFT,即一百万点的FFT,在采用8个DSP内核,运行速率为1GHz时,运行时间仅6.4毫秒。
图二:单核与多核在性能上的提升
结论
综上所述,用TI的TMS320C6678处理器来执行一个百万点的FFT,在1GHz的工作频率下,8核同时运行所需时间仅需6.4毫秒。如此高速的DSP内核完全足以用来执行某些应用的实时运算,比如雷达、电子战争和医学绘图等。如果用最大速度1.25GHz来运行TMS320C6678处理器,同时采用更高带宽的DDR3和1600MTPS的话,执行运算所需时间会更短。
收藏
分享
评分
回复
引用
订阅
TOP
返回列表
3G
MCU 单片机技术
在线座谈交流区
电商论坛
Pine A64
资料下载
方案分享
FAQ
行业应用
消费电子
便携式设备
医疗电子
汽车电子
工业控制
热门技术
智能可穿戴
3D打印
智能家居
综合设计
示波器技术
存储器
电子制造
计算机和外设
软件开发
分立器件
传感器技术
无源元件
资料共享
PCB综合技术
综合技术交流
EDA
MCU 单片机技术
ST MCU
Freescale MCU
NXP MCU
新唐 MCU
MIPS
X86
ARM
PowerPC
DSP技术
嵌入式技术
FPGA/CPLD可编程逻辑
模拟电路
数字电路
富士通半导体FRAM 铁电存储器“免费样片”使用心得
电源与功率管理
LED技术
测试测量
通信技术
3G
无线技术
微波在线
综合交流区
职场驿站
活动专区
在线座谈交流区
紧缺人才培训课程交流区
意见和建议