Linux 网络文件系统的数据备份及恢复机制实现(3)
|

- UID
- 1029342
- 性别
- 男
|

Linux 网络文件系统的数据备份及恢复机制实现(3)
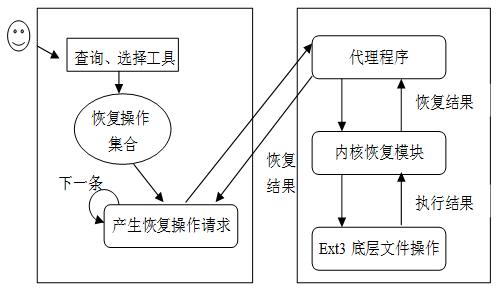
图 7 恢复流程示意图
数据快速同步技术
在系统中,各文件服务器之间的数据需要及时同步更新,这样才能保证服务迁移后到新的环境后相关数据环境的一致性,从而保证服务迁移在语义上的正确性。在本方案中,每个文件服务器均采用 NFSv3 协议向外提供文件服务,当系统开始工作时,管理员会指定一台主服务器,由该服务器负责向外提供服务,其他文件服务器为备份服务器,接收同步数据,进行数据的同步更新,并不对外提供服务,只有当系统决定迁移后,选定的迁移目标对应的文件服务器才成为主文件服务器。
由于主文件服务器负责对外的文件服务,因此,数据同步的发起者应该是主文件服务器,而所有的备份服务器均为被动的同步数据接收者。因此,数据的快速同步包含两方面的工作:主文件服务器产生同步数据和备份文件服务器接收同步数据完成同步。具体的数据流向如图 8 所示:
图 8 同步数据的产生与流动示意图
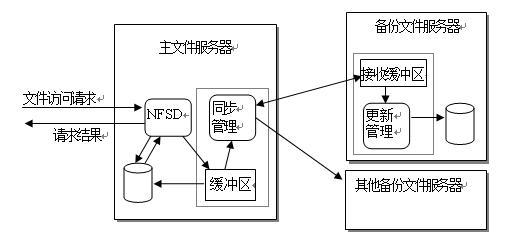
为了达到数据快速同步的目的,我们采用了记录文件写操作(包括创建、修改、删除、改名、属性修改等所有的改变文件或目录属性、内容的操作)的具体参数的方法来生成同步数据,这样每次生成的数据量比较少,而且可以满足及时更新的目的。同步数据的格式及相关代码段如下:
struct Log { - int length; //整个数据包的长度 int ops; //操作的类型
- char* data; //与操作相关数据 };
- //下面代码段从内核将同步数据包发往其他文件服务器 long send(struct socket* sock, void * buff,size_t len)
- { int err;
- mm_segment_t oldfs; struct msghdr msg;
- struct iovec iov; static int total = 0;
- down(&log_sem); iov.iov_base=buff;
- iov.iov_len=len; msg.msg_name=NULL;
- msg.msg_iov=&iov; msg.msg_iovlen=1;
- msg.msg_control=NULL; msg.msg_controllen=0;
- msg.msg_namelen=0; total += len;
- msg.msg_flags = MSG_SYN;//DONTWAIT; oldfs=get_fs();
- set_fs(KERNEL_DS); err = sock_sendmsg(sock, &msg, len);
- set_fs(oldfs); if(err<0){
- dprintk("send err(errNo=%d len = %d)\n",err,len); netbroken = 1;
- } ……
- up(&log_sem); return(err);
- }
[table][/table]
同步数据产生后,先放入一个缓冲区中,而不是立即发送到备份文件服务器,这样可以较大程度改善系统的总体性能。缓冲区中的数据由同步管理进程管理,当达到一定数据量时,同步管理程序负责把缓冲区中的数据发送到备份文件服务器上,并根据返回的应答结果决定是否需要把重发数据,当确认某个服务器无法响应后,自动把同步数据定期写入一个仅可追加的文件,以便于随后可能需要的恢复阶段同步的需要,当这个写入的文件数据量超出一定限制时,并且系统确认已经至少有一个新的版本生成,可以把该文件清空。
当数据到达备份文件服务器时,由独立的接收进程负责把数据放入接收缓冲区,经核对数据无误后给主服务器发送确认信号,另一个独立进程即更新管理进程把接收缓冲区作为输入,从中解析出一个个的顺序的操作日志,从每个日志中得到操作类型,然后在剩余的数据中按照特定的操作类型提取所需的参数,利用文件系统调用完成相应操作。
总结
Linux 网络文件系统已经为企业在数据备份和共享领域得到了广泛应用。如何保证其多版本备份、实时恢复是一个非常关键的问题,本文将详细介绍针对该网络文件系统的数据备份、恢复及同步机制在内核的具体实现,给广大系统管理员和研发人员提供技术参考。 |
|
|
|
|
|


