首页
|
新闻
|
新品
|
文库
|
方案
|
视频
|
下载
|
商城
|
开发板
|
数据中心
|
座谈新版
|
培训
|
工具
|
博客
|
论坛
|
百科
|
GEC
|
活动
|
主题月
|
电子展
注册
登录
论坛
博客
搜索
帮助
导航
默认风格
uchome
discuz6
GreenM
»
MCU 单片机技术
»
ARM
» 如何调试复杂的实时嵌入式系统?
返回列表
回复
发帖
发新话题
发布投票
发布悬赏
发布辩论
发布活动
发布视频
发布商品
如何调试复杂的实时嵌入式系统?
发短消息
加为好友
yuyang911220
当前离线
UID
1029342
帖子
9914
精华
0
积分
4959
阅读权限
90
在线时间
286 小时
注册时间
2014-5-22
最后登录
2017-7-24
论坛元老
UID
1029342
性别
男
1
#
打印
字体大小:
t
T
yuyang911220
发表于 2016-11-21 11:03
|
只看该作者
如何调试复杂的实时嵌入式系统?
嵌入式
,
开发商
,
多线程
,
如何
,
产品
随着实时嵌入式系统的复杂程度不断提高,低效率的调试方法的成本日益增加。鉴于当前嵌入式应用的复杂性还有继续上升的趋势,对这些系统的调试将成为加速产品上市和提供鲁棒性最终产品的关键因素。随着应用对多线程和中断嵌套的使用,开发商的大部分时间目前都花在调试上。应用的实时属性使得将伴随同时发生多个事件的故障问题孤立起来变得更为困难。本文将讨论常见的调试问题以及预防和检查这些故障问题的一些方法。
从历史角度上来看,嵌入式应用代码的调试流程可以分为两类。第一类调试流程是回答 “我的代码现在执行到哪里?” 的问题。当开发商依靠打印语句或者LED的闪烁来指示应用程序执行到某个节点的调试方法时,往往就属于这种情形。如果开发工具支持这种调试方法,可以沿着应用应当程序应当执行的路径插入断点。第二类调试流程是帮助回答“我看到的这一数值是从哪里来的?”这一问题。在这种情况下,人们往往依靠寄存器显示窗口观察变量信息、处理器内存的内容。人们还可以尝试单步执行,并且观察所有这些数据窗口以了解某个寄存器状态何时出现错误,内存位置何时得到错误的数据,抑或指针何时出现了误用。
当开发商写完全部代码后,如果无需了解网络基础设施,也没有操作系统的任务调度需要考虑,那么就可以利用这些调试方法使一个应用程序运行起来。然而,现在的情况并非如此。嵌入式处理器以超过600 MHz的速度运行,并且拥有可支持Ethernet和USB等协议的嵌入式外设,它们支持功能齐备的操作系统,例如uClinux,而且这些操作系统所调度的各种应用程序是由数千行代码构成。使用打印语句和利用LED来调试是不现实的,因为现在常常有如此之多的功能在执行是不可能的,或者它们会影响标准I/O口,从而造成处理器性能大幅度下降。
也可能发生这样的情况:处理器的工作速度是如此之快,以至于LED的亮灭速度会快到人眼无法察觉。另外现代的嵌入式系统通常支持断点的设定,但是伴随这些处理器所运行的代码数量,使得这种类型的断点调试难以驾驭。中断和多线程系统在代码的任何一点上设置一个断点,可能都无法指示系统的正确状态。由于断点设置在物理内存的某个地址上,索引不必了解线程的状态。如果使用寄存器显示方法,那么局部变量窗口和内存窗口都将有助于隔离出所载入的不恰当的量值,但是,由于这些是静态化的工具,不能给出有意义的运行中的调试信息,其适用性也常常很有限。
实时嵌入式系统软件最常见的调试问题可以大致划分为如下几类:
1. 同步问题
2. 内存和寄存器讹误(corruption)
3. 与中断相关的问题
4. 硬件配置问题
5. 异常情况
同步问题
在任何系统中,只要有多串序线程或者进程都在运行,而且是异步共享数据,则系统必然存在同步问题。对于共享数据的全部操作必须是原子化的,也就是说,只有在一个线程或者进程完成对数据的操作后,其它的线程才能对数据进行操作。
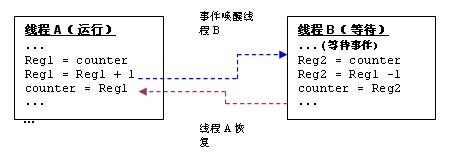
以图1为例,线程A和线程B对共享变量“counter”进行操作,A让counter 增加,而B则让counter减少。下方示出了线程A的counter++和线程B counter—的汇编代码。假设线程B的优先级要高于线程A,而线程A目前正在运行,则线程B将被阻止。
举例来说,假设初始的计数值是2,而线程A是执行线程。则线程A读入计数值,并送入一个寄存器,在使其增加一个增量后,再将其写回计数器变量上。
在可抢先的多线程系统中,高优先级的线程的执行可以抢先于低优先级的线程。例如,假定线程A执行Reg1 = Reg1+1指令后,一个事件唤醒线程B。此时,Reg1储存量值3。现在线程B被唤醒(正如蓝线所标示的那样),并读入计数器的量值2(它尚未被线程A刷新)并将其量值减小到1。正如棕色的线所显示的那样,经过一段时间,线程A恢复运行,将Reg1写入计数器中,而该计数器的储存量值为3。 在这个过程中,线程B的减量操作结果被丢弃。计数器存储的量值变为2,即线程A进行一次增量后,线程B又进行了一次减量操作。被窜改的链接表则是另一个例子。如果数据被一个线程和中断例程共享,则也会出现上面的问题,因为中断的执行与线程的执行之间是异步关系。
同步化方面的问题常常是很难进行调试的,因为它们取决于时序,是随着软件对数据的操作而随机出现的。幸运的是,这些问题可以通过恰当地保护任何共享数据来避免。大多数的
实时操作系统
可以提供同步化原语。开发商 可以使用最适当的机制来保护共享数据,而不至于影响系统的性能。如果数据在多个线程之间共享,则开发商将有如下的选择:
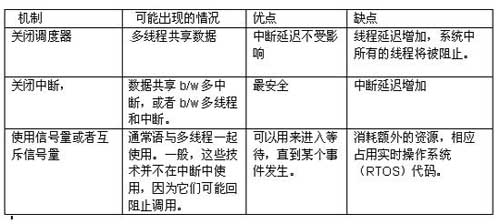
a. 关闭调度器以便当前的线程永远不会被其它线程抢先。(无调度区)
b. 使用信号两(Semaphore)或者互斥信号量(Mutex)来保护共享数据。
c. 利用关键区域来进行保护,即屏蔽所有的中断。
开发商必须从性能出发来选择恰当的技术选项。关闭调度器,将防止任何一种环境的切换,从而使得现在的线程能继续执行,直到调度器重新打开为止。这种方法有一个负面的影响:它将阻止任何准备好运行的高优先级的线程。这一现象被称为优先级倒置。将中断关闭是最安全的方法,对于执行时间短的情形来说是理想选择。于是,最差情况的中断延迟就是所有未发生中断的持续时间的总和。在硬实时系统中,一般来说,一个中断功能可以被关闭的时间存在上限。
调试的一个小窍门就是,如果共享的数据被破坏,则编程者就应当首先检查出任何一种多个线程或者中断对共享数据同时进行的操作。如果线程和中断共享了数据,那么在线程代码中必须将中断关闭。如果数据在多个中断例程之间共享的话,则中断也应当被关闭,因为高优先级的中断可以抢先于低优先级的中断。
在多线程的系统中,高优先级的线程可以抢在低优先级的线程之前执行。因此,如果数据在多个线程间共享的话,则必须采用某种恰当的机制来保护被共享的数据。
另外一个同步化问题则与线程优先级的不恰当的分配有关。应当确保系统的初始化线程在引导时间内就启动,并在生成其它的优先级更高的线程之前,完成整个系统的初始化。例如,如果一个用于配置一个器件的低优先级现场被一个使用该设备的高优先级的线程抢先后,配置可能会完成,并可能会造成设备的故障。为了避免这种情形,开发商应当使用操作系统所支持的信号量或者其它同步化的原语。
内存和寄存器的数据讹误
大多数的嵌入式系统都采用了平面化的内存模式,也并没有内存管理单元(MMU),于是没有硬件支持的内存保护机制。即使采用能提供这种功能的处理器,也需要由开发商来实现对某些内存区域的保护。进程和线程将对其它进程和线程的内存空间有完全的访问权限。这可能会造成下面所描述的、各种类型的内存讹误问题。
堆栈溢出
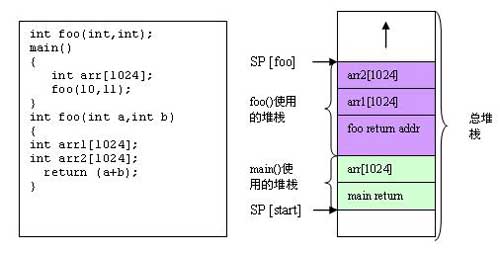
运行时堆栈是在函数调用进程中所使用的一种暂存空间,用于存储局部变量。硬件寄存器指针(SP)将跟踪堆栈指针的地址。如果你在高级的语言中编程,如C语音,则编译器所生成的代码将使用与C语言运行时间模型相一致的堆栈。运行时间模式定义了变量是如何存储在堆栈中的以及编译器将如何使用堆栈。局部的变量被放置在当前的堆栈中。下面给出的例子描述了在堆栈上采用的某些关键性的内存。
当堆栈指针超出了其所指定的边界时,就会出现堆栈溢出。这将造成内存的讹误,并最终造成系统的失效。在上述的实例中,如果总的堆栈内存区不足以容纳所有的局部变量,堆栈溢出就会发生。
调试的一个技巧就是,如果你担心溢出,一个好的做法,就是将堆栈安排在内存边界上,这样,如果在调试过程中出现了溢出,则仿真器将触发一个硬件异常提示。
开发商可以采用的一个技巧是,如果你担心堆栈的溢出,你就应当考虑把它放在有效的内存的边界上。这样,当堆栈溢出时,设备将报告硬件异常,而不是造成其它内存空间的讹误。
在独立运行的应用中,运行时间堆栈可能就已经够用。然而,在使用任何一种实时操作系统时,每个线程和过程都将有自己的堆栈。考虑到性能方面的原因,大多数嵌入式实时操作系统的堆栈尺寸都是事先确定的,无法在运行中动态扩展。这意味着,如果针对特定的线程/进程所选用的堆栈尺寸不恰当的话,堆栈溢出就会发生。
如果应用大量使用局部变量(如阵列和大的结构),则将不得不按比例为其分配堆栈的空间。人们可以利用malloc() 来分配内存,或者将其设置为静态的全局变量,具体是何种方法,则取决于实际应用。
有些实时操作系统可能会提供调试功能,例如保护位,以形成对堆栈溢出的防护。这些操作系统要么记录关于堆栈溢出的错误信息,要么提交一个异常报告,以便动态地增加堆栈。最起码当前的大多数实时操作系统都能报告堆栈以及已经被线程和进程所采用的堆栈的情况。
在任何中断驱动的系统中,堆栈的分配方式都必须考虑到中断服务例程所采用的空间。如果中断例程的设计目标是使用当前的执行对象栈,则在这种情况下,每一个线程或进程所拥有的最小的堆栈尺寸都应大于或者等于执行对象所要求的堆栈尺寸加上所有中断例程累积起来所需要的最大的堆栈尺寸。
嵌入式系统开发商必须掌握各种应用链接库。例如,第三方的库可能会认定堆栈上为其提供了空间。
收藏
分享
评分
继承事业,薪火相传
回复
引用
订阅
TOP
返回列表
FPGA/CPLD可编程逻辑
电商论坛
Pine A64
资料下载
方案分享
FAQ
行业应用
消费电子
便携式设备
医疗电子
汽车电子
工业控制
热门技术
智能可穿戴
3D打印
智能家居
综合设计
示波器技术
存储器
电子制造
计算机和外设
软件开发
分立器件
传感器技术
无源元件
资料共享
PCB综合技术
综合技术交流
EDA
MCU 单片机技术
ST MCU
Freescale MCU
NXP MCU
新唐 MCU
MIPS
X86
ARM
PowerPC
DSP技术
嵌入式技术
FPGA/CPLD可编程逻辑
模拟电路
数字电路
富士通半导体FRAM 铁电存储器“免费样片”使用心得
电源与功率管理
LED技术
测试测量
通信技术
3G
无线技术
微波在线
综合交流区
职场驿站
活动专区
在线座谈交流区
紧缺人才培训课程交流区
意见和建议