|

- UID
- 1029342
- 性别
- 男
|

本文着重介绍了京东数据结转平台的技术架构,及OLTP类系统数据结转最佳实践,探讨解决大数据背景下的数据结转问题。
一、 背景介绍
业务系统在长期运行的过程中会积累大量的数据,这些数据有些是需要长期保存的,例如一些订单数据,有些只需要短期保存,例如一些日志信息。业务数据一般都会有一个生命周期,生命周期内的我们叫生产数据,生命周期之外(即业务已经关闭)的叫历史数据,我们这里提到的数据结转,指的是将需要长期保存的历史数据从生产库迁移到历史库(转),而将需要短期保存的数据定期删除(结)。
我们已经进入了大数据时代,但在OLTP类系统中,关系型数据库依然占据主导地位,在关系型数据库中,如果不及时进行数据结转,会严重影响系统的性能。
关系型数据库单机容量有限,因此业界普遍的做法是进行垂直分库和水平分片,一些大型互联网企业由于业务量庞大,仅分片的集群规模就能达到上千节点,再加上分库的集群,规模非常巨大。传统的数据归档方法往往针对单库操作,难以处理如此大规模集群的数据归档。
同时,在大型互联网企业,每日的数据增长量非常大,数据结转的频率远大于传统行业,这些行业的IT系统往往是7*24小时不间断提供服务,而且全天24小时的并发量都很大,因此数据结转操作必须尽量减少对生产库的性能影响。
为此,我们自主研发了数据结转平台,以解决大数据背景下的数据结转问题。
二、 技术架构
2.1 设计要点
(1)尽量减少对生产库的影响
数据结转操作没有复杂的业务逻辑,因此对数据库性能的影响主要体现在IO方面,减少对生产库的影响,最主要的就是减少对生产库的IO操作。目前我们采用的方案是通过从库查询数据,将数据插入历史库,然后再从主库中删除,如图1数据结转逻辑图所示,将查询的IO操作转嫁到从库上,可以大大减轻对主库的影响。为了保障数据库的高可用,业内基本都采用了主从部署模式,因此这个方案具有很高的通用性。
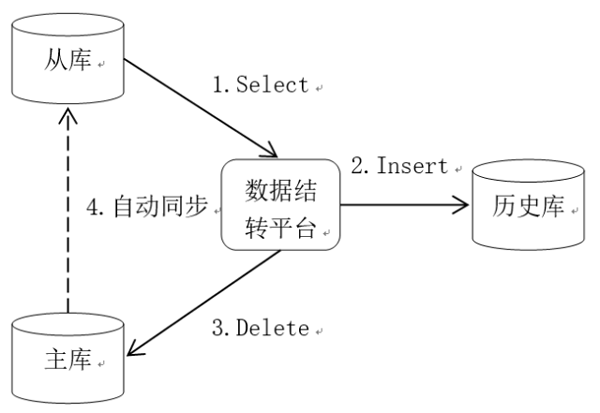
图1 数据结转逻辑图
(2)支持分库分片集群
我们希望数据结转平台的配置足够简单并且易于理解。在和用户的沟通过程中,我们发现他们最强烈的需求就是分库分片集群的数据结转。传统的单机数据结转操作可以抽象描述为:将数据库实例A中表B的历史数据结转到历史库C,用户的配置主要有4个元素:生产库实例A、结转表B、结转条件和历史库。对于大规模的分库分片集群规模,如果采用传统单机数据结转的配置方式,每一个数据库实例都要配置4个元素,配置量非常大。
在我们的方案中,按照图2所示对数据库集群进行划分,将主库、从库、历史库作为一个结转单元,对于分片的数据库集群,表结构相同,我们将其作为一个分组,对于分库的集群,表结构不同则划分为不同的分组。用户进行配置的时候不是面向一个数据库实例,而是面向一个分组,数据结转操作抽象为:结转分组X中表B的历史数据,用户的配置元素有3个:分组X、结转表B和结转条件。分组信息仅需配置一次。这样大大简化了用户的配置工作。
(3)支持水平扩展
由于数据库集群规模较大,数据结转平台应该具备水平扩展能力。我们采用的方案是将数据结转最核心的组件定时任务和数据库操作(数据结转执行器)独立出来,进行分布式部署。如下图3所示,
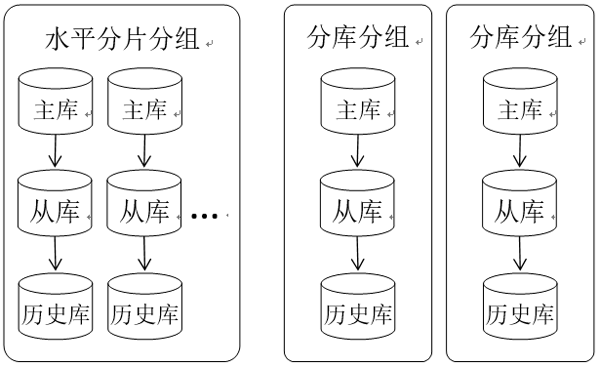
图2 数据库集群模型
配置中心为用户的入口,用户通过配置中心定义数据结转任务,任务的关键属性包括:触发条件、执行条件、目标分组等,配置中心将结转任务分发给代理程序,同时对代理程序的执行状态进行监控。结转任务的触发条件配置在代理程序中的定时任务中,而执行条件和目标分组则作为数据结转执行器的执行参数。通过水平扩展代理程序,我们对更多的数据库进行结转。
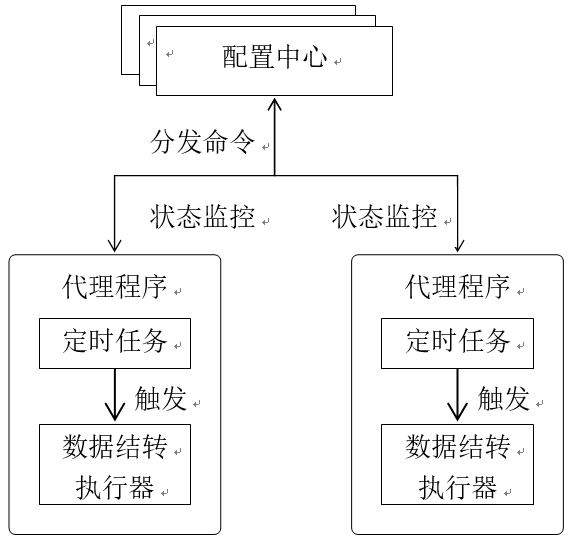
图3 数据结转组件关系图
2.2 总体架构
综合上面提到的3个设计要点,我们得到图4所示的总体架构,需要特别说明的是,对于水平分片的分组,我们采用的是多线程结转,对于不同结转单元不存在数据共享问题,所以无需考虑并发锁等问题。 |
|


