|

- UID
- 1029342
- 性别
- 男
|

三、 一些经验总结
a) 配置中心与代理程序之间的信息同步
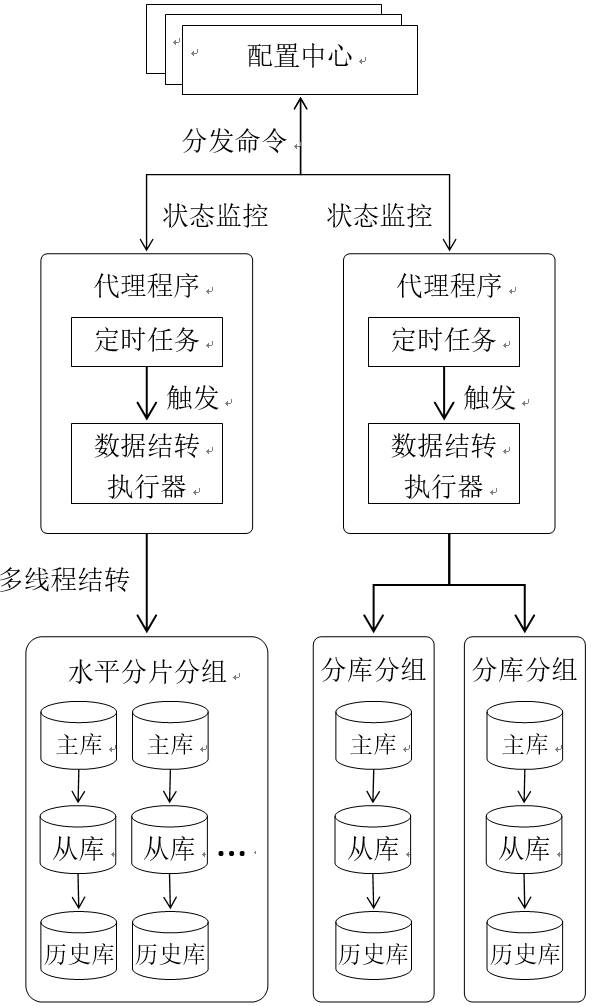
图4 数据结转总体架构图
配置中心和代理程序在我们的方案中被设计为一种松耦合结构:在系统的运行过程中,代理程序宕机不会影响配置中心的运行,同样配置中心短暂的不可用也不会影响代理程序的运行。松耦合结构可以大大增强系统的可用性,而且配置中心、代理程序升级的时候不会影响整个系统的正常运行。
为了实现松耦合的结构,配置中心与代理程序之间的信息同步我们都是采用的异步处理,比如配置中心向代理程序分发结转任务,实际处理的时候我们采用的是拉的方式,而不是推的方式,我们在配置中心和代理程序之间维持了一个心跳,心跳的内容是代理程序负载的所有结转任务的校验码(该校验码在代理程序向配置中心发送心跳信息时由配置中心计算),当代理程序发现从配置中心得到的校验码和本地校验码不同时,则说明用户对结转任务进行了修改(包括新增、修改、删除),此时代理程序主动向配置中心发起同步结转任务的请求。这样做的好处是,代理程序在发生宕机重启后,会自动进行任务的同步。
b) 进度可视化
结转任务的进度在我们的方案中是实时汇总到配置中心的,我们称为进度可视化,代理程序通过一个独立的线程来异步处理进度可视化,一方面这样可以降低对结转任务性能的干扰,另一方面可以避免由于网络问题、配置中心暂时不可用等问题导致结转任务异常。进度可视化对于用户来说非常重要,用户在第一次定义结转任务并执行该任务的时候,进度可视化信息是用户和系统互动的唯一窗口,对用户来说是莫大的心理安慰。
c) 异常可视化
代理程序在执行数据结转任务时,会遇到各种异常信息,比如数据库URL配置错误,历史库生产库表结构不一致等,对于这些异常信息,除了在本地记录日志外,我们还将它们发送到了配置中心。将这些异常可视化,而不是让用户在大量的日志中去检索,这种方式非常便于在线问题的诊断。
d) 事务一致性
将生产库数据转到历史库本身是一个分布式的事务,在我们的方案中,不能保证数据的强一致性,比如在历史数据Insert到历史库的瞬间,用户修改了生产库的数据,我们的方案不会检测这种变化,会导致用户的修改并不会反映到历史库中,造成数据不一致。虽然在生产库中删除历史数据时,可以增加强一致性的校验,以解决这种问题,但是这样会对生产库造成一定的压力,同时考虑到这种情况发生的概率极低,因此并没有进行特殊处理。
历史数据Insert到历史库后,可能由于某种异常导致生产库执行Delete操作时失败,此时会造成数据冗余(生产库和历史库存在相同数据)。对于这种问题,我们的方案是利用Redo Log(重做日志)机制,在结转任务重新执行时根据Redo Log恢复异常现场,纠正异常数据。
e) 结转数据的回滚
我们提供了一个数据回滚功能,可以将已经结转到历史库的数据逆向回滚到生产库,用户可以配置Where条件精确指定需要回滚的数据。有些特殊情况,业务上需要对已经结转的历史数据进行修改,该功能主要用于处理这种情况。同时在测试阶段,我们可以通过该功能快速恢复测试数据,方便对数据结转平台的测试。
f) 代理程序的自动升级
代理程序和配置中心本质上是一种典型的C/S(客户端/服务端)结构,客户端是多实例部署,服务器端是集群部署,为了系统能够平滑地进行升级,我们需要对客户端的版本进行统一管理,同时我们提供了代理程序的自动升级功能,系统管理员可以通过配置中心对代理程序部署实例进行升级。自动升级功能,统一了代理程序的版本,使得我们可以不用被兼容性问题羁绊,是我们能够进行快速迭代开发有力支撑。 |
|


