智能手机设计的挑战与趋势使用场景的变化仅是一个方面,移动设备本身也经历大幅升级。智能手机市场最初主打旗舰机型,随着智能化程度的不断提高,很多 PC特性已经可以实现,但通讯依旧是其主要功能。然而,过去短短几年间,智能手机用途不断扩展,打电话已不再是智能手机的主要功能,图像显示成为了关注焦点。
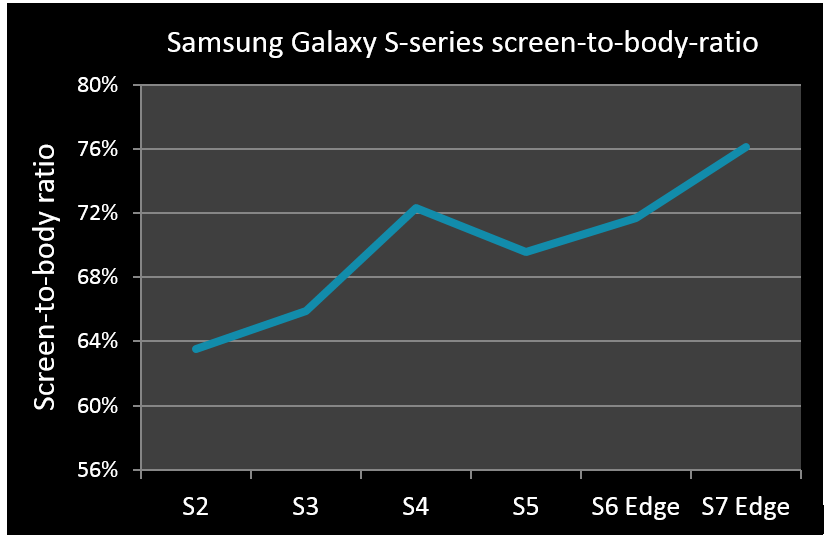
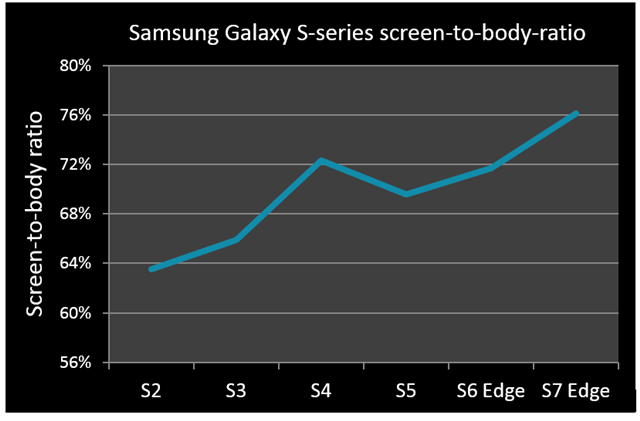
过去,手机电池寿命一般用单次充电支持的通话时长来衡量,而现在的标准则是网络浏览或高端游戏的续航时间。GPU与显示性能一起备受关注。用户希望体验更高质量的视觉效果,到目前为止,这一目标都是经由智能手机设计改善,以及显示内容的美感和流畅性来实现,一个证据就是屏幕边框变得越来越窄。市场的大致趋势是朝着屏幕包裹设备的方向发展,设计美感更多由UI而非硬件来实现。下图中,我们可以看出屏幕占整个设备的比例不断增加。这一趋势在三星Galaxy S7 Edge等机型上体现得尤为明显,已经实现屏幕对设备的全包裹。
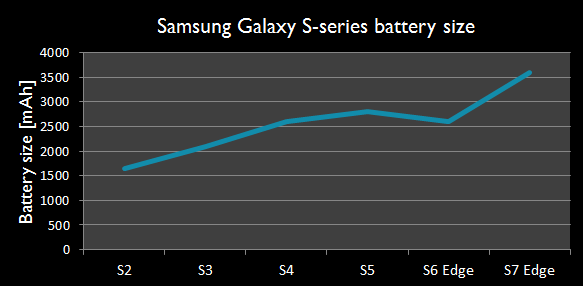
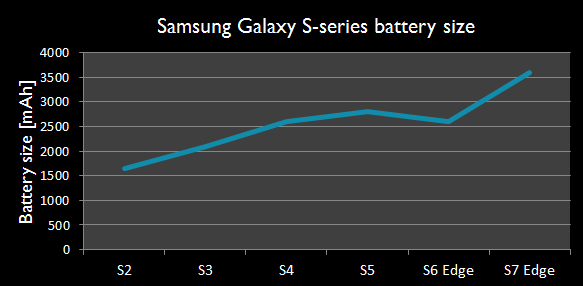
除了打电话,现代智能手机还能提供极为丰富的功能,如邮件、社交媒体、导航定位、支付、浏览网页、游戏、拍照和视频等等。用户在期待功能升级的同时,也希望电池寿命不断延长。但是,即便使用当前所有最先进的技术,智能手机的电池容量还是要不断增大,具体变化趋势见下图。
除了电池容量变大,智能手机还变得越来越薄。一些机型的厚度甚至已经达到了7毫米以下,考虑到现代智能手机的技术含量,如此纤薄实在令人惊讶。
这样的发展方向并非完全没有弊端。屏幕增大导致电池尺寸变大,机身变薄,设备散热能力下降,因为屏幕的散热效率不如金属机身。此外,机身变薄后,用以散热的表面积也会减少。现代高端智能手机的性能上限很大程度上被散热能力牵制,如何保证机身内部元器件不因为高温而受损则因此成为另一大挑战。
现代智能手机装有多种耗电发热的核心元件,如摄像头子系统、屏幕、调制解调器、Wi-Fi、非易失性存储器、DRAM和主芯片本身(包括CPU、GPU和其他处理器)。因为总功耗一致,所以其中任何一个元件功耗的减少,都可以增加其他元件可以使用的配额,这也是系统功耗配比由用例决定的原因。
现代GPU非常复杂,严重依赖CPU运行驱动程序,以实现基于软件与应用程序进行交互。多亏了Vulkan这样的现代API,驱动程序的开销下降了,但是CPU依然需要运行驱动程序,所以不能完全避免耗电。由于所有元件功耗预算共享,因此在CPU中使用的、用于GPU交互的功耗就是不能应用于GPU本身的功耗。基于上述原因,降低CPU功耗势在必行,不仅是为GPU发展扫清瓶颈,更是要为尽可能的提高GPU可用功耗铺平道路。
与之类似,在运行复杂3D游戏的现代系统中,GPU会消耗大量DRAM带宽。由于要处理大量数据(上述提及的Lofoten每帧处理600,000个三角),消耗带宽责无旁贷,但DRAM的读写本身就是耗电的过程,也需要占用系统的总功耗预算。减少DRAM带宽可以降低其功耗,并用于其他元件。
现代智能手机的设计和日益复杂的用例对GPU提出了前所未有的挑战。下一章,我们将介绍ARM新一代GPU和GPU架构是如何应对这些挑战的。
为下一代设备打造的Mali-G71Mali-G71是ARM最新推出的高性能GPU,也是首款基于全新Bifrost架构的GPU,性能和效率都获得显著提升。

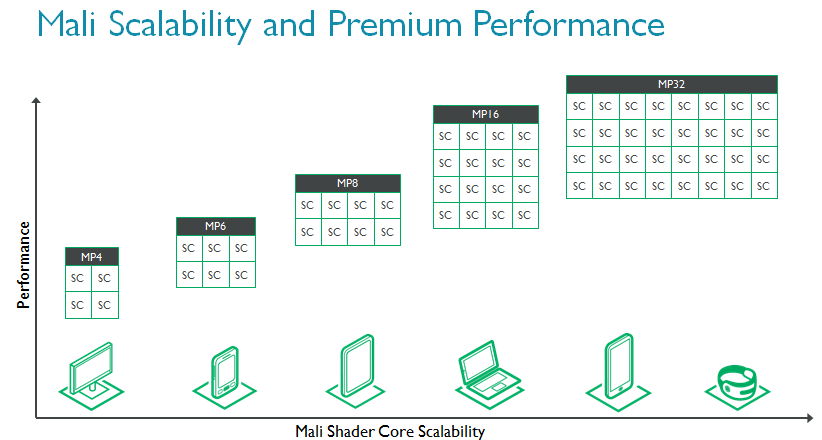
Mali-G71是迄今为止ARM性能最高的GPU。为满足现代用例所需性能,着色器核心数量从1扩展至32,帮助芯片制造商根据目标市场自主权衡性能和功耗。出于这个原因,我们认为Mali-G71将在各类应用中将大展拳脚。
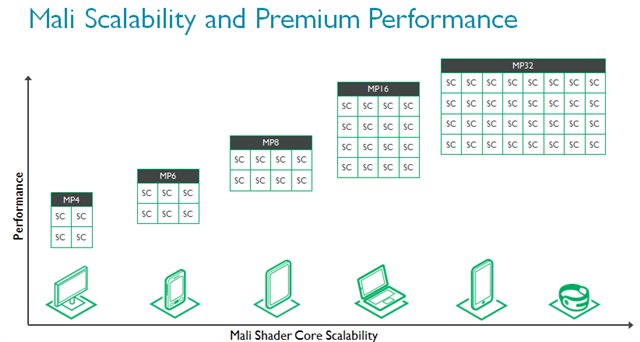
如前文所述,智能手机的很多性能都受到散热的限制,还有一些手机的限制因素则是成本,或者说是芯片尺寸。为了实现更高性,Mali-G71和Bifrost架构同时升级了能源效率(单位瓦特性能)和性能密度(单位芯片面积性能),帮助功耗与散热性能遭遇挑战的芯片制造商实现更高的GPU性能。相似条件下,Mali-G71的能源效率相较Mali-T880最多可提高20%,性能密度最多可提高40%。此外,外部存储消耗的总带宽降低20%,进一步减少整体系统功耗。

Bifrost架构发展 为了进一步说明Mali-G71为何具备远超历代ARM GPU的性能,我们首先来探讨一下GPU架构本身,以及实现这些性能的设计方法。
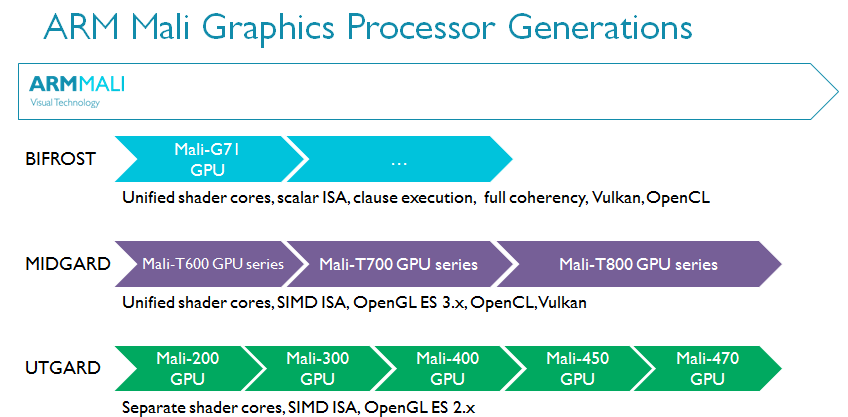
Bifrost是ARM的第三代可编程的GPU架构,其研发知识与经验传承自Utgard和Midgard GPU架构。
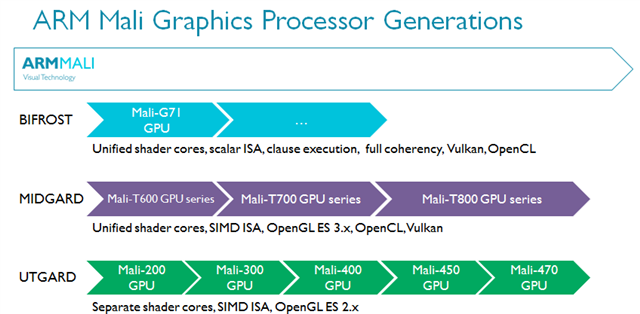
ARM的前两代GPU架构——Utgard和Midgard都取得了巨大成功。它们专为新兴的移动GPU市场打造,无论体积还是内部科技的运用都可圈可点。Utgard是ARM首款可编程GPU,支持GLES 2.x,片段着色器与顶点着色器相互独立。Midgard则引入了统一着色器,支持GLES 3.x,并可与OpenCL 1.x Full Profile协同实现GPGPU运算。Midgard是一款前瞻性的GPU架构,甚至包括了一些可以支持Vulkan的功能特性。考虑到这是5年前设计的架构,就足以成为了不起的成就。
然而,随着内容和用例的改变,架构本身也必须进行根本性的升级,以适应各类下一代用例。
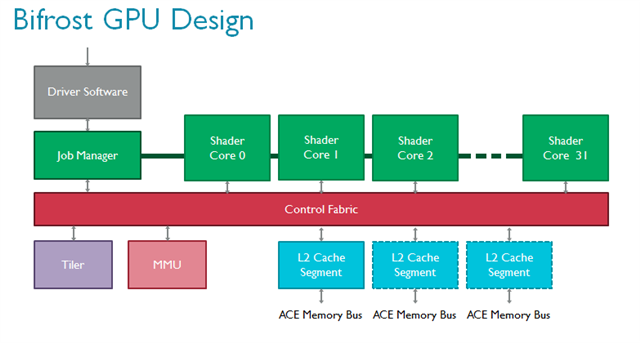
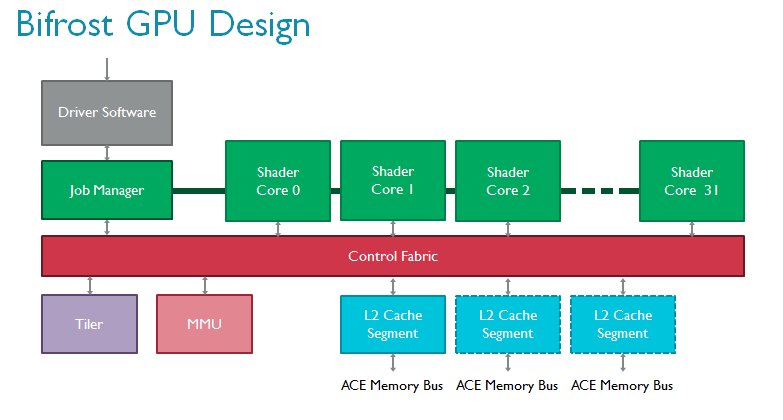
从顶层设计看,与Midgard架构相比,Bifrost的GPU内核没有明显变化。表面上依然包括多个可扩展的着色器核心、一个负责与驱动程序交互的任务管理器、一个负责处理内存页表的MMU以及一个tiler(Bifrost 仍然是一个 Tile based 渲染架构),但全部模块都获得了显著提升。
通过AMBA ACE或AXI-Lite与外界交互的L2子系统为支持AMBA 4 ACE专门设计,帮助Mali-G71彻底实现硬件一致性,并在GPU和CPU等其他单元之间实现了基于硬件的细粒数据透明共享。
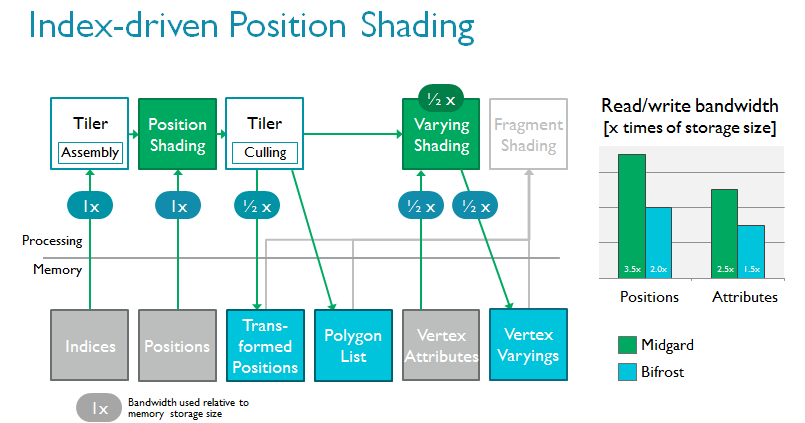
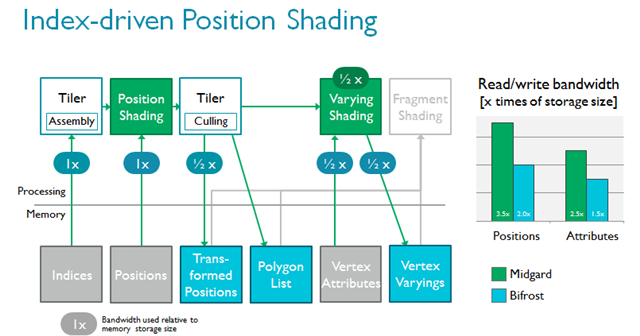
我们对tiler做了重新设计,以支持一种全新的渲染流,即索引驱动的位置渲染。该技术的理念是将顶点着色分为两部分以节省带宽,因为无需读写屏幕上看不见的变化参数(varying)1;而且由于无需写回不可见位置,带宽可以得到进一步节省。
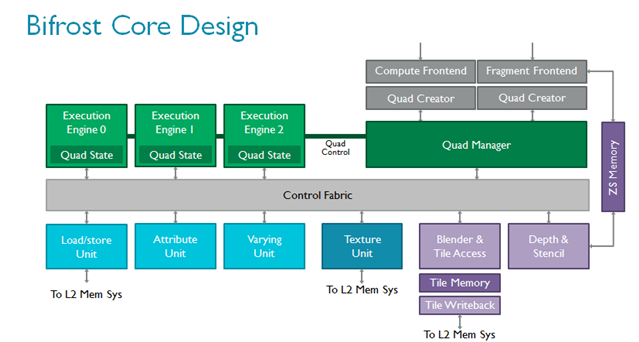
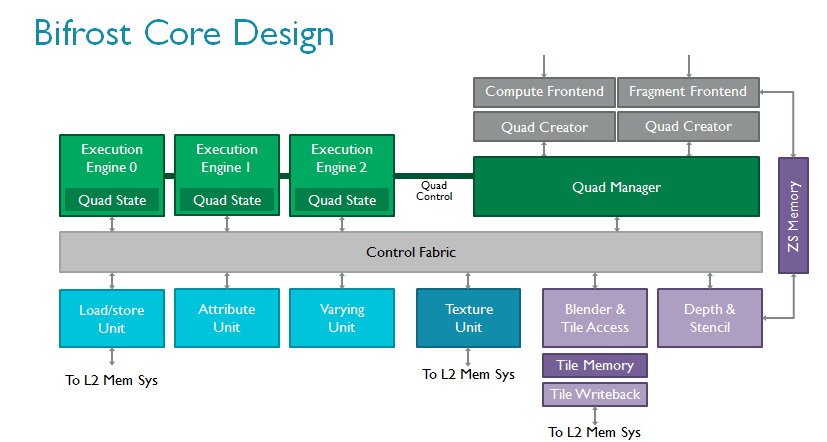
着色器核心本身的变化更为巨大。ARM在Bifrost中引入全新指令集,根据大量的内容和趋势分析以及长年的行业经验开发。现代GPU的总体趋势是执行越来越多的复杂可编程着色器,通常通过算法完成并采用大量标量代码。作为全新引擎的一部分,Bifrost采用全新的算法单元,以极高的效率执行高级着色器核心。它们更容易扩展,如果未来需求有增加,该架构也可以轻松应对。
Bifrost的属性(attribute)单元和变化参数单元相互独立,这些操作在图形处理中极为普遍,使用独立的高度优化硬件模块更为合理。全新的指令集引入高效的四线程组以节省控制逻辑,并通过四线程组管理器将线程组切换至执行引擎。我们还加入了一个控制架构以提高物理利用率。如上文所述,此特性对现代工艺节点非常重要。
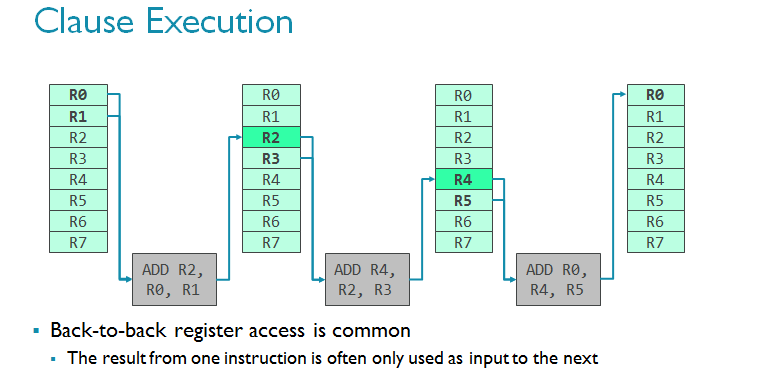
Bifrost引入了名为子句着色器的概念,专门用于处理执行引擎内部的布线密度问题。你可以将子句想象成一组连续自动执行的指令,也就是说,一个子句的执行不能被中断,无论是分支(如分支只发生在子句边界上)还是其他任何事件都无法中断。这意味着子句是可以预测的,数据路径周围的控制逻辑变得更容易。比如说,你无需在子句内部更新程序计数器,因为GPU知道它会在执行前(或执行后)根据子句内部的指令数量向前推进。
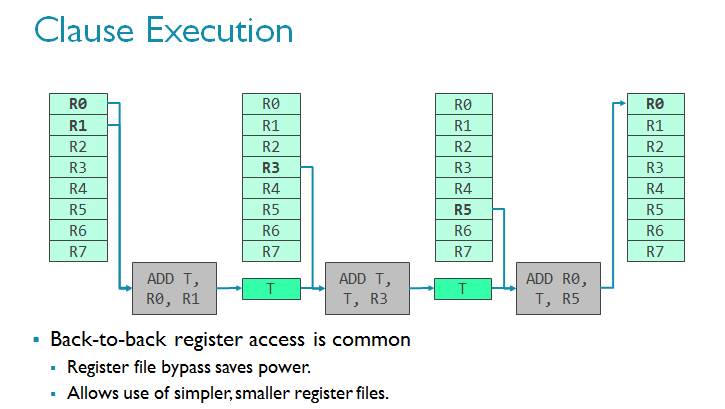
对CPU而言,这一行为并不可取,因为CPU必须迅速处理分支,而且分支的出现并不偶然。但恰恰相反,对GPU而言,该技术又可以进一步优化设计。请想象一组指令集正在经过。连续的指令经常使用上一条指令作为输入(见下方一排中的多个ADD正在积累数据)。如果你经常观察到这一现象,而且你知道访问暂存器组的代价非常高昂(因为这是一个巨大的存储模块),有一种方法来缓解这个问题,那就是巧妙地使用临时寄存器来减少寄存器组的访问量。由于寄存器是临时的,数据只会在一个时钟周期中保留,所以要想实现,子句必须确保在子句内部原子执行。
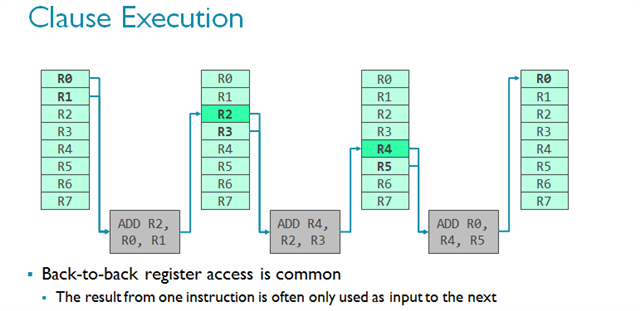
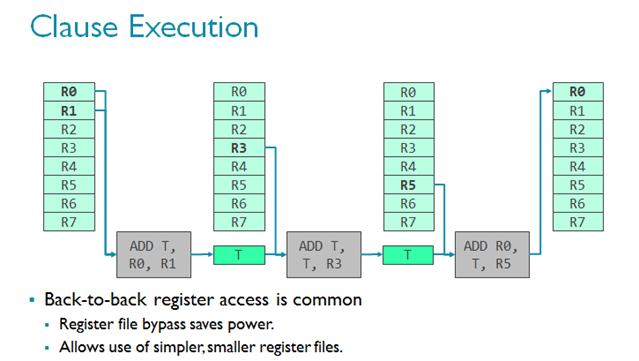
请参考下图的简单着色器程序,从指令集的角度了解子句着色器的工作原理。需要指出的是,这是开发者所看不到的,由编译器完成的。

总结 通过对Bifrost架构如何提高效率和性能的详细解读,我们可以清楚地了解Mali-G71具备哪些根本性的创新技术,以实现万众期待的GPU性能升级。通过支持全新的现代API(如Vulkan和OpenCL 2.0),Mali-G71有助于实现出色的新兴应用场景体验。ARM将继续研发Bifrost架构,满足下一代内容的需求并超越行业期待。2016年,更多新技术将现身ARM Mali 多媒体组件。 |