最近在看 UNIX 网络编程并研究了一下 Redis 的实现,感觉 Redis 的源代码十分适合阅读和分析,其中 I/O 多路复用(mutiplexing)部分的实现非常干净和优雅,在这里想对这部分的内容进行简单的整理。
几种 I/O 模型为什么 Redis 中要使用 I/O 多路复用这种技术呢?
首先,Redis 是跑在单线程中的,所有的操作都是按照顺序线性执行的,但是由于读写操作等待用户输入或输出都是阻塞的,所以 I/O 操作在一般情况下往往不能直接返回,这会导致某一文件的 I/O 阻塞导致整个进程无法对其它客户提供服务,而 I/O 多路复用就是为了解决这个问题而出现的。
Blocking I/O先来看一下传统的阻塞 I/O 模型到底是如何工作的:当使用 read 或者 write 对某一个文件描述符(File Descriptor 以下简称 FD)进行读写时,如果当前 FD 不可读或不可写,整个 Redis 服务就不会对其它的操作作出响应,导致整个服务不可用。
这也就是传统意义上的,也就是我们在编程中使用最多的阻塞模型:
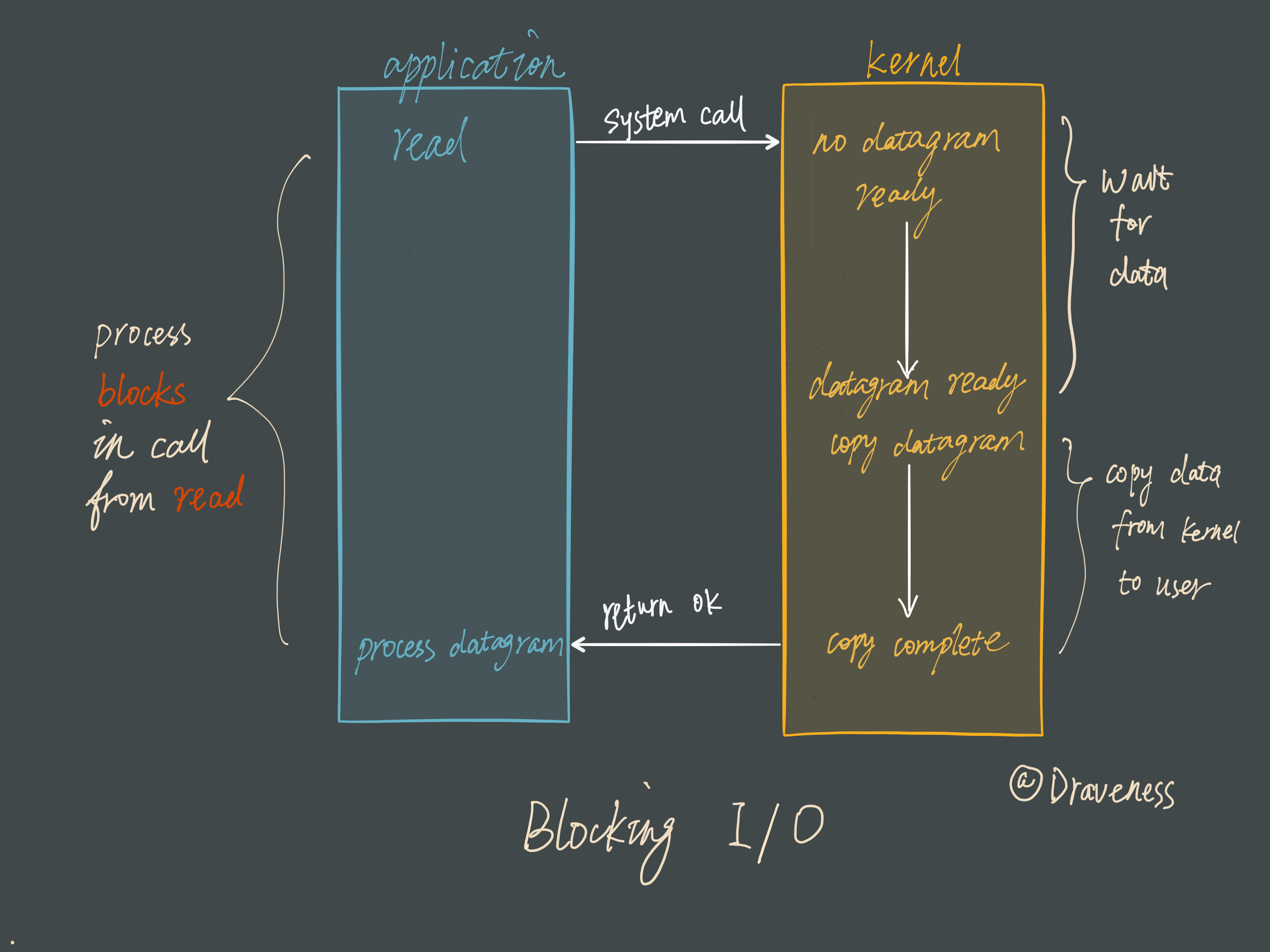
阻塞模型虽然开发中非常常见也非常易于理解,但是由于它会影响其他 FD 对应的服务,所以在需要处理多个客户端任务的时候,往往都不会使用阻塞模型。
I/O 多路复用虽然还有很多其它的 I/O 模型,但是在这里都不会具体介绍。
阻塞式的 I/O 模型并不能满足这里的需求,我们需要一种效率更高的 I/O 模型来支撑 Redis 的多个客户(redis-cli),这里涉及的就是 I/O 多路复用模型了:
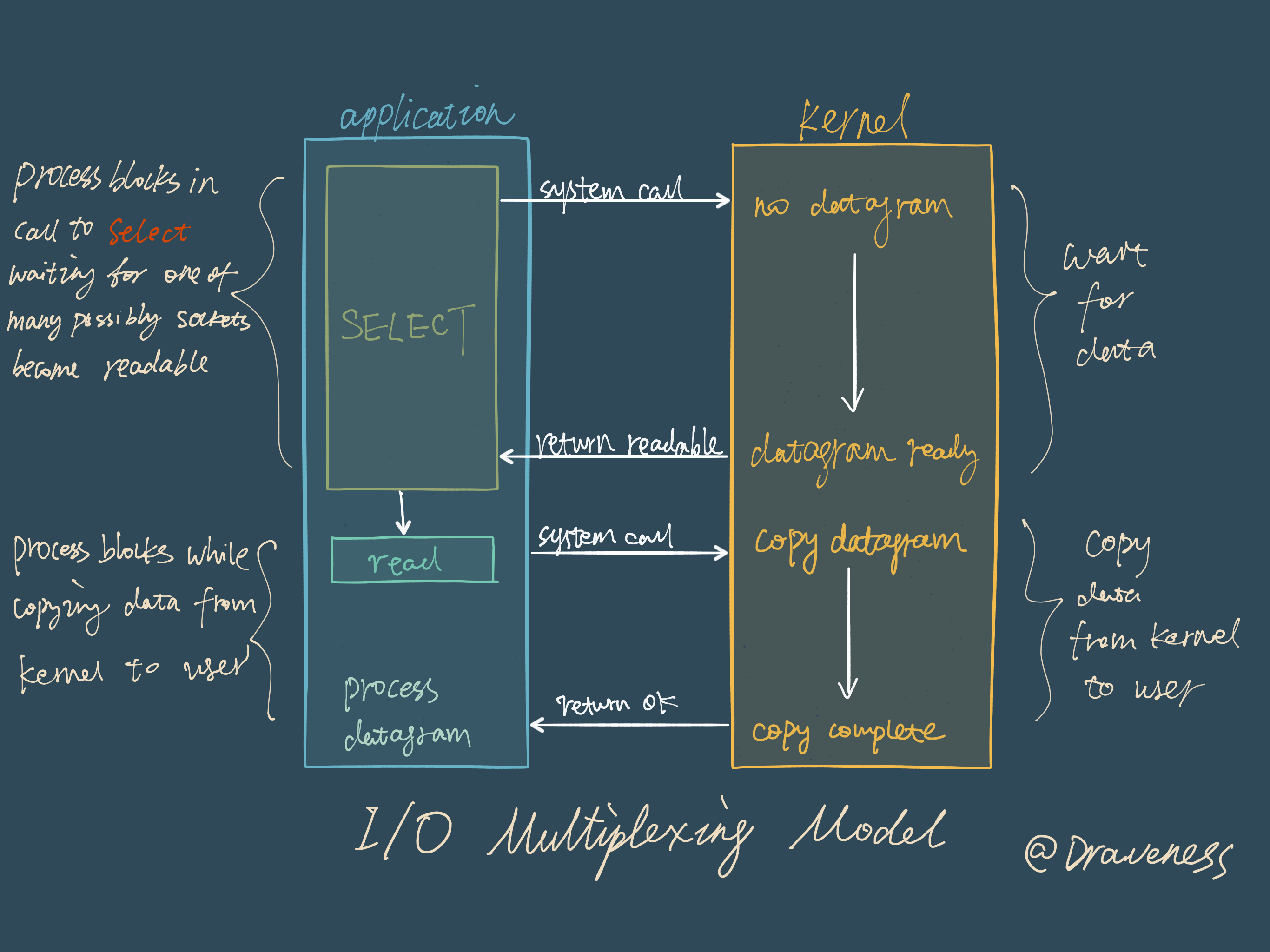
在 I/O 多路复用模型中,最重要的函数调用就是 select,该方法的能够同时监控多个文件描述符的可读可写情况,当其中的某些文件描述符可读或者可写时,select 方法就会返回可读以及可写的文件描述符个数。
关于 select 的具体使用方法,在网络上资料很多,这里就不过多展开介绍了;
与此同时也有其它的 I/O 多路复用函数 epoll/kqueue/evport,它们相比 select 性能更优秀,同时也能支撑更多的服务。
|




