FFM——引入特征域概念
2015年,基于FM提出的FFM(Field-aware Factorization Machine ,简称FFM)在多项CTR预估大赛中一举夺魁,并随后被Criteo、美团等公司深度应用在CTR预估,推荐系统领域。相比FM模型,FFM模型主要引入了Field-aware这一概念,使模型的表达能力更强。
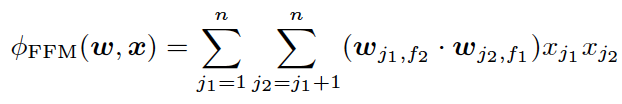
上式是FFM的目标函数的二阶部分。其与FM目标函数的区别就在于隐向量由原来的wj1变成了wj1,f2,这就意味着每个特征对应的不是一个隐向量,而是对应着不同域的一组隐向量,当xj1特征与xj2特征进行交叉时,xj1特征会从xj1的一组隐向量中挑出与特征xj2的域f2对应的隐向量wj1,f2进行交叉。同理xj2也会用与xj1的域f1对应的隐向量进行交叉。
那么这里所说的“域”代表着什么呢?
简单来讲“域”代表着特征域,域内的特征一般会采用one-hot编码形成one-hot特征向量。
我们通过Criteo FFM论文的中一个例子来更具体的说明FFM的过程。假设我们在训练CTR模型过程中接收到下面这个样本。

其中,Publisher,Advertiser,Gender就是三个特征域。ESPN、NIKE、Male分别是这三个特征域的特征。那么,如果按照原FM的原理,ESPN与NIKE、以及ESPN与Male做交叉的权重应该是

大家肯定已经注意到,由于交叉特征域的改变,ESPN的隐向量由wESPN,A换成了wESPN,G 。
FFM模型学习每个特征在f个域上的k维隐向量,交叉特征的权重由特征在对方特征域上的隐向量内积得到,权重数量共nkf个。在训练方面,由于FFM的二次项并不能够像FM那样简化,因此其复杂度为kn2。
相比FM,FFM由于引入了field这一概念,为模型引入了更多有价值信息,使模型表达能力更强,但与此同时,FFM的计算复杂度上升到kn2,远远大于FM的k*n。 |




