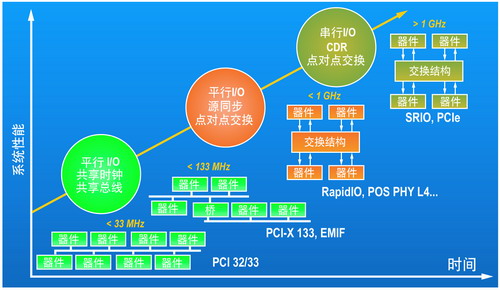
台式电脑和网络工业已采用了 PCI Express (PCIe) 和千兆位以太网/XAUI 等标准。不过,无线架构中数据处理系统的互连要求略有不同,其特点是:低引脚数;背板芯片对芯片连接;带宽和速度可扩展;DMA 和信息传输;支持复杂的可扩展拓扑;多点传输;高可靠性;绝对时刻同步;服务质量 (QoS)。
图2 SRIO网络构建模块
SRIO 网络围绕两个基本模块构建而成:端点和交换机(见图2)。端点对包进行源端(source)和宿端 (sink) 处理,而交换机在端口间传送包,对其不加解析。SRIO以一个三层架构层级指定(见图3):
.物理层规范说明器件级接口的细节,如包传输机制、流量控制、电气参数及低级错误管理。
.传输层规范为包在端点间移动提供必需布线信息。交换机通过使用基于器件的布线在传输层中运行。
.逻辑层规范定义总体协议和包格式。所有包的有效载荷字节数为 256 或更少。事务使用指向 34-/50-/66 位地址空间的加载/存储/DMA 操作。事务包括:
.NREAD-读操作(返回数据即为响应)
.NWRITE - 写操作,无响应
.NWRITE_R - 强韧型写入,响应来自目标端点
.SWRITE - 流式写入
.ATOMIC - 原子性读/改/写
.MAINTENANCE - 系统查找、探测、初始化、配置和维护操作

图3 分层SRIO架构
SRIO - 优势前景
以 3.125Gbps 运行的 4 通道 SRIO 链路可以提供 10Gbps 的流量,且保证数据完整性。由于SRIO类似于微处理器总线(存储器和器件寻址,而非 LAN 协议的软件管理),因此包处理是通过硬件实现的。这意味着可大幅削减 I/O 处理方面的额外开销,降低延迟并增加系统带宽。但与多数总线接口不同,SRIO 接口的引脚数较少,带宽在链路为 3.125Gbps 的基础上可继续扩展。
平台中的计算资源
如今的应用对处理资源的数量要求较高。基于硬件的应用发展迅猛。压缩/解压缩算法、反病毒和入侵监测等防火墙应用以及要求 AES、三倍 DES 和 Skipjack 等加密引擎的安全应用起初都是通过软件实现的,但目前都已转为硬件实现。这就需要带宽和处理能力能够实现共享的大型并行生态系统。系统需要使用 CPU、NPU、FPGA 或 ASIC,从而实现共享或分布式处理。
在构建能够适应未来发展变化的系统时,需考虑所有这些针对具体应用的要求,对计算资源的要求包括:
.多个主机 - 分布式处理
.直接点对点通信
.多个异构操作系统
.复杂拓扑结构:发现机制;多余通路(故障恢复)
.可支持高可靠性:无损协议;自动重新培训和器件同步;系统级错误管理
.能够支持通信数据平面:多点传输;流量管理(有损)操作;链路、级别和基于流的流量控制;协议互通;较高事务并发度
.模块化、可扩展
.支持广泛生态系统
由无线架构中计算器件所派生出的各种各样的要求,SRIO 协议都可支持。
SRIO 规范(见图4)对基于包的分层架构进行了定义,可支持多个域或市场区间,从而有利于系统架构设计师设计新一代计算平台。通过将 SRIO 用作计算互连,可轻松实现以下功能:使架构独立;部署可靠性为运营商级的可扩展系统;实现高级流量管理;提供高性能、高流量。此外,由大批供应商构成的生态群使得 OTS 部件与组件的选择十分容易。
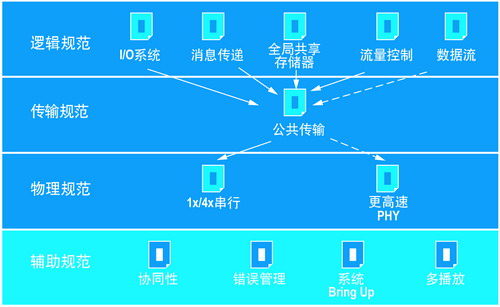
图4 SRIO规范
SRIO 为基于包的协议,该协议支持:通过基于包的操作(读、写、消息)移动数据;I/O 非连贯功能和缓存连贯功能;通过支持数据流、数据分区和重组功能而实现高效互通和协议封装;通过启用数百万个流而实现流量管理框架,支持 256 流量级别和有损操作;流控制,支持多个事务请求流,提供 QoS;支持优先级别,从而可缓解带宽分配和事务顺序等问题,并避免死锁;支持拓扑,通过系统发现、配置和维护支持标准(树状和网格)与任意硬件(菊花链)拓扑,包括支持多个主机;错误管理和分类(可恢复、提醒和致命性)。
Xilinx针对SRIO的IP解决方案
用于 SRIO 的 Xilinx 端点 IP 解决方案针对 RapidIO 规范 (v1.3) 而设计。用于 SRIO 的完整 Xilinx 端点 IP 解决方案包括以下部分(见图5):
.用于 SRIO 的 Xilinx 端点 IP 为软性LogiCORE解决方案。对于通过逻辑 (I/O) 和传输层上的目标和发起接口源出和接收用户数据,都支持完全兼容的最大有效载荷操作。
.缓冲层参考设计作为源代码提供,可自动重新划分包的优先级别并调整队列。
.SRIO 物理层 IP 可实现链路培训和初始化、发现和管理以及错误和重试恢复机制。另外,高速收发器在物理层 IP 中例化,可支持线速率为1.25Gbps、2.5Gbps和3.125Gbps的1通路和 4 通路 SRIO 总线链路。
.寄存器管理器参考设计允许 SRIO 主机器件设定并维护端点器件配置、链路状态、控制和超时机制。另外,寄存器管理器上提供的端口可供用户设计探测端点器件的状态。

图5 用于SRIO的Xilinx端点IP构架
用于 SRIO 的整个 Xilinx 端点 IP LogiCORE 解决方案已全面经过测试,硬件验证也已进行,目前正在就与主要 SRIO 器件供应商之间的协同工作能力接受测试。LogiCORE IP 通过 Xilinx CORE Generator软件 GUI 工具提供,该工具允许用户定制波特率和端点配置,并支持流量控制、重发送压缩、门铃和消息接发等扩展功能。这样,用户便可创建一个灵活、可扩展的定制 SRIO 端点 IP,对自己的应用进行优化。
Virtex-5 FPGA计算资源
用于 SRIO 的 Xilinx 端点 IP 可确保在使用 SRIO 协议的链路双方间建立高速连接。在最小的 Virtex-5 器件中,IP 仅占用不到 20% 的可用逻辑资源,因此可确保用户设计使用大多数逻辑/存储器/I/O,集中实现系统应用。
逻辑模块
Virtex-5 逻辑架构带有基于 65nm 工艺的六输入查找表 (LUT),可提供最高的 FPGA 容量。进位逻辑经过改进后,该器件的性能比之前的器件高出 30%。由于所需 LUT 减少,该器件的功耗明显降低,且具备高度优化的对称布线架构。
存储器
Virtex-5 存储器解决方案包括 LUT RAM、Block RAM 及与大型存储器进行接口的存储器控制器。Block RAM 结构包括预制 FIFO 逻辑,即可用于外部存储器的嵌入式检错和纠错 (ECC) 逻辑。另外,Xilinx 可通过存储器接口生成器 (MIG) 工具向系统设计中的例化存储器控制器模块提供综合设计资源。这样,用户便可利用经过硬件验证的解决方案,并将精力集中于设计中的其他关键部位。
并行和串行 I/O
SelectIO技术几乎可在设计中实现客户所需的任何并行源同步接口。使用 SelectIO 接口,可方便地针对 40 多种不同的电气标准创建符合行业标准的各类接口,也可创建专用接口。SelectIO 接口提供的最大速率为700Mbps(单端)和1.25Gbps(差分)。
所有Virtex-5 LXT FPGA都集成有一个 GTP 收发器,运行速度介于 100 Mbps 到 3.2Gbps 之间。另外,GTP 收发器在业界属于最低功率 MGT 之一,每个收发器的功率小于 100mW。引入用来简化设计的成熟设计技术和方法后,高速串行设计的流程变得简单快捷。
另外,通过新设计工具(RocketIO收发器向导与 IBERT)和新硅片性能(TX 和 RX 均衡与内置伪随机位序列 (PRBS) 生成器和检查器),可以开发移植架构的各种功能和优势,从并行 I/O 标准到 30 多种串行标准及新兴的串行技术。
DSP 模块
每个 DSP48E Slice 可提供 550MHz 的性能水平,允许用户创建要求单精度浮点性能的各类应用,如多媒体、视频和图像应用以及数字通信。这扩展了器件的功能,使其优于之前的器件,同时还提供了功率优势,动态功耗的降低幅度超过了 40%。Virtex-5 FPGA 中还增加了 DSP48E Slice 的数量,这些模块相对于可用逻辑资源及存储器的比率从而得到了优化。
集成 I/O 模块
所有 Virtex-5 LXT FPGA 器件都具备一个端点模块,用来实现 PCIe 功能。通过这种硬 IP 端点模块,只需简单地重新进行配置即可轻松地从 x1 扩展至 x2 和 x4 或 x8。该模块(x1、x4 和 x8 链路)已通过严格的 PCI-SIG 兼容性和协同工作能力测试,用户可放心用于 PCIe。
另外,所有 Virtex-5 LXT FPGA 器件均装有三态以太网媒体访问控制器 (TEMAC),速度可达 10/100/1000Mbps。该模块可提供专用以太网功能,再结合 Virtex-5 LXT RocketIO 收发器和 SelectIO 技术,可方便与许多网络器件进行连接。
利用针对 PCIe 和以太网的这两种模块,可以创建一系列定制包处理和网络产品,这些产品可大幅降低资源利用率和功耗。通过使用 Xilinx FPGA 中提供的这些各式资源,可以轻松创建并部署智能解决方案。
SRIO 嵌入式系统应用
可以考虑围绕基于 x86 架构的 CPU 构建一个嵌入式系统。CPU 架构已高度优化,可轻易满足要求玩弄数字于股掌的各类应用。用户可以轻松地在使用 CPU 资源的硬件和软件中实现各类算法,以执行不需要进行大量乘法运算的电子邮件、数据库管理以及文字处理等功能。性能以每秒钟所产生的指令/运算为数百万还是数十亿来衡量,而效率通过完成特定运算所需的时间/周期来衡量。
需进行大量定点和浮点运算的高性能应用在处理数据时需花费较长时间。这方面的示例包括信号过滤、快速傅里叶变换、矢量乘法和搜索、图像/视频分析和格式转换以及简单的数字处理算法。在 DSP 中实现的高端信号处理架构可轻松执行这些任务,并可优化此类运算。这些 DSP 的性能以每秒钟进行多少次乘法和累加运算来衡量。
用户可以方便地设计使用 CPU 和 DSP 的嵌入式系统,以充分利用两种处理技术。图 6表示使用 FPGA、CPU 和 DSP 架构的系统示例。
高端 DSP 中的主要数据互连为 SRIO。x86 CPU 中的主要数据互连为 PCIe。如图 6 所示,用户可轻松部署 FPGA 以扩展 DSP 应用或对离散数据互连标准(如 PCIe 和 SRIO)进行桥接。
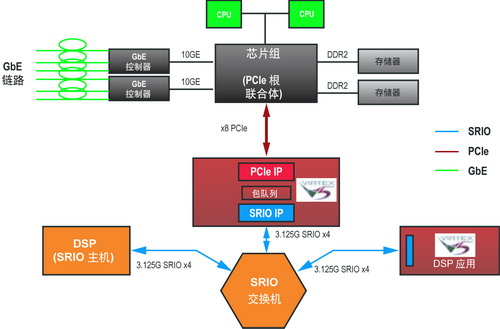
图6 基于CPU的可扩展、高性能、嵌入式系统
在图 6 所示系统中,PCIe 系统由根联合体(Root Complex)芯片组托管。SRIO 系统由 DSP 托管。32/64 位 PCIe 地址空间(基址)可智能化地被映射至 34/66 位 SRIO 地址空间(基址)。PCIe 应用可通过存储器或 I/O 读写与根联合体进行通信。这些事务会通过 NRead/NWrite/SWrite 轻松映射至 SRIO 空间。
在 Xilinx FPGA 中设计此类桥接功能很简单,因为这些 Xilinx 端点功能模块、PCIe 和 SRIO 的后端接口都很相似。这样,“包队列”模块便可执行从 PCIe 到 SRIO 或反方向的交叉任务,从而建立可穿越两个协议域的包流。
SRIO DSP 系统应用
在 DSP 处理为主要架构要求的应用中,系统架构可按图 7 进行设计。
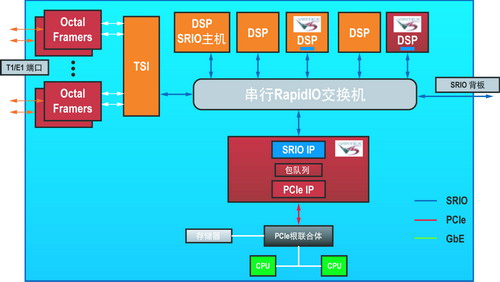
图7 DSP密集型阵列
基于 Virtex-5 FPGA 的 DSP 处理与系统中的其他 DSP 器件结合即可构成智能协处理解决方案。如果使用 SRIO 作为数据互连,整个 DSP 系统解决方案就可以方便地进行扩展。此类解决方案能够适应未来的发展变化,提供了延伸性,而且受多种形状因子的支持。在 DSP 密集型应用中,通过将相应处理任务卸载至 x86 架构中可实现快速数字分析或数据处理。使用 Virtex-5 FPGA 可轻易地连接 PCIe 子系统和 SRIO 架构,从而实现高效功能卸载。
SRIO 基带系统应用
现有 3G 网络正在以较快的步伐迈向成熟,OEM 也在为缓解特定容量和覆盖率问题而部署新的形状系数。要解决此类特殊问题,对市场趋势做出评估,基于 FPGA 的 DSP 架构是理想选择,该架构将 SRIO 用作数据层面标准。另外,早期 DSP 系统可快速升级,变为快速、低功耗 FPGA DSP 架构,从而获得可扩展性优势。
如图 8 中的系统所示,您可以对 Virtex-5 FPGA 进行设计,以满足现有对天线流量的线速率处理需求,还可通过 SRIO 提供与其他系统资源间的连接。现有早期 DSP 应用的固有并行连接速度较慢,因可应用于 Virtex-5 FPGA 的 SRIO 端点功能的存在,移植这些应用极为方便。
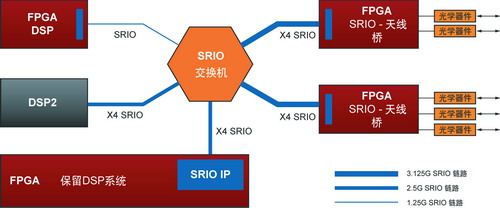
图8 可扩展基带上行链路/下行链路卡