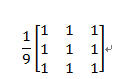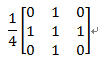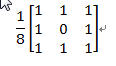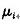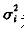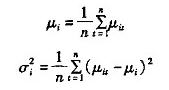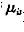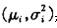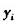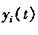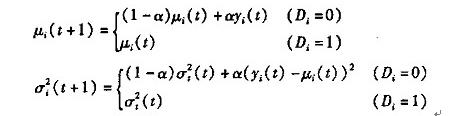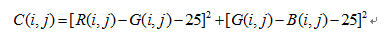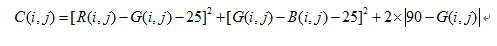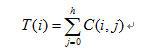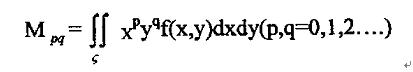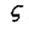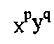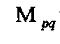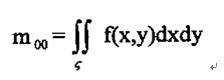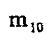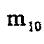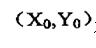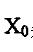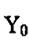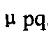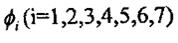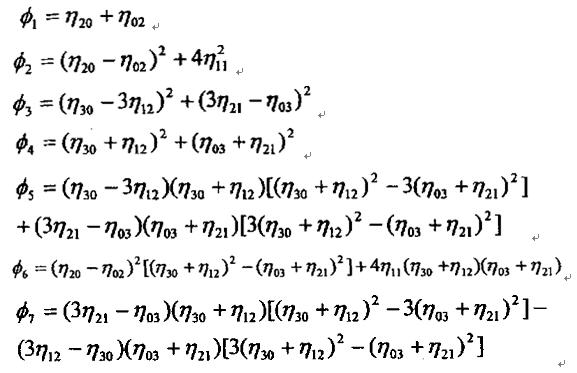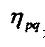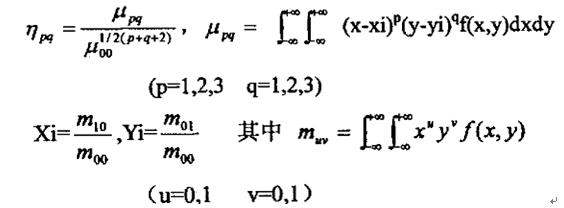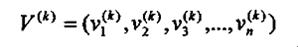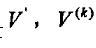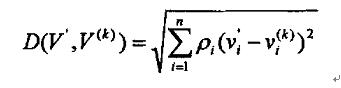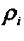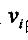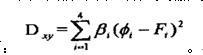|
 
- UID
- 1023230
|

摘要:
一直以来,聋哑人与健康人之间的交流就十分的困难,特别是没有学习过手语的人。我们的这个项目旨在打破这个障碍,让没学过手语的人也能听见聋哑人的心声。我们的手语语音转换器目的就是就是通过它提供一种有效的途径将聋哑人的手势识别出来,并转换成我们普通人所习惯的语音信息,从而实现聋哑人与我们的有效沟通。目前手语识别可以分为基于视觉的识别系统和基于数据手套的识别系统。基于视觉的手势识别系统采用常见的视频采集设备作为手势感知输入设备,价格便宜、便于安装。鉴于基于视觉的手势识别方法交互自然便利,适于普及应用,且更能反映机器模拟人类视觉的功能,我们这次的识别方法为基于视觉的手势识别。
1 绪论
1.1 项目背景与分析
一直以来,聋哑人与健康人之间的交流就十分的困难,特别是没有学习过手语的人。我们的这个项目旨在打破这个障碍,让没学过手语的人也能听见聋哑人的心声。我们的手语语音转换器目的就是就是通过它提供一种有效的途径将聋哑人的手势识别出来,并转换成我们普通人所习惯的语音信息,从而实现聋哑人与我们的有效沟通。
目前手语识别可以分为基于视觉的识别系统和基于数据手套的识别系统。前者需要使用者戴上数据手套,这就给使用者造成一定的不便,基于视觉的手势识别系统采用常见的视频采集设备作为手势感知输入设备,价格便宜、便于安装,提供了更加自然、直接的人机交互方式。在以后的发展中,手势识别是有着很大的前景,在人机交互中起着不可忽视的作用。
我们这次的识别方法为基于视觉的手势识别。手势识别分为动态手势识别和静态手势识别,动态手势定义为手运动的轨迹,而静态手势强调通过手型传递一定的意义。本文研究静态手势识别。静态手势识别通常是基于视觉的2D手势识别,设计一个手势语音的转换器可以说给聋哑人带来了福音,解决了聋哑人与健康人的交流困难。
本文所设计的手势语音识别器大大提高了残疾人与正常人进行交流沟通的方便性。系统的开发与利用将可以促进手势识别技术的发展,具有很强的实用性和广阔的应用前景。
手势识别还可以应用到很多其他的机器视觉领域,实现人机之间的更好的交互,在越来越注重用户体验的今天,手势识别的定会在今后的交互中大放异彩。
1.2 目前相关技术的研究及应用状况
当今社会中中传统的人机交互方式已经不能满足人们对现代生活方式的追求。传统的一些交互方式在舒适性,易用性,趣味性,个性化等方面已经越来越凸显出不足之处。自然语言是人类交流的主要手段,通过语言同计算机交谈无疑是广大计算机用户梦寐以求的愿望新型直观自然的交互方式如动作交互,语音交互越来越成为生活中必要的方式,但是由于由于其技术复杂度高、环境干扰因素较大、数据处理量大、成本高,研发速度和研发水平等受到严重的制约,但是, 现代化发展的今天,人们又迫切需要更加舒适更加自然的交互方式,现在的交互方式逐渐不能满足人们的要求。
目前,国内外相关技术研究大多还处于理论研究阶段,很多技术都不成熟,手势识别技术却很少有比较成熟的产品出现,基本上处于理论研究阶段,即便有,也只是对一些简单的动作通过加速度等传感器来实现,相对比较简单。但还没有能将手势通过图像识别出来的相关产品,我们的手势语音识别器就是在手势动作识别的基础上实现的,将该技术应用在解决聋哑人的语言交流问题,我们在这里对其进行了尝试。
2 系统功能描述及设计
2.1 功能概述

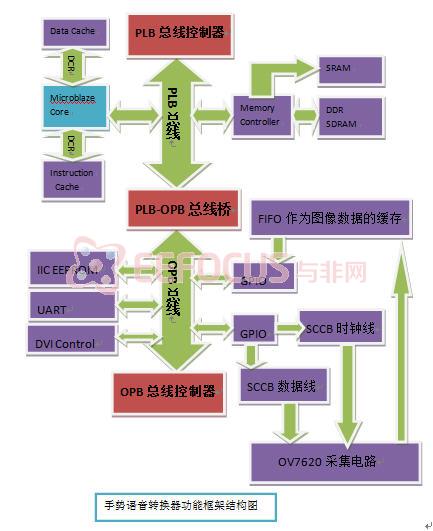
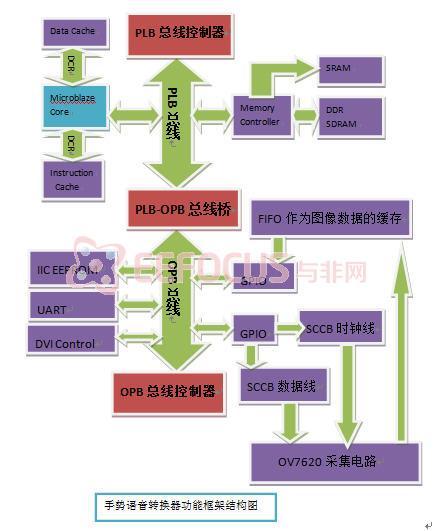
上图是手势语音转换器的系统结构框架图,在手势识别的时候需要做到准确性,实时性的要求。我们的设计利用图像传感器在外界环境中的手势图像进行实时采集,通过我们的系统平台对图像进行一系列的处理之后,转换为对应的语义,再利用语音合成芯片变为文字语音输出。将手势转换为对应的语音意义输出。其功能框架结构图如下:
2.2 具体方案选择
2.2.1 图像采集模块
两个方案 1.直接利用USB摄像头进行图像采集2.利用模拟摄像头,经过AD芯片转换
方案一
优点:直接利用电脑的USB摄像头,虽然是CMOS摄像头,但是摄像头已经内置DSP芯片,无需再对模拟数据进行AD转换,FPGA芯片可以直接利用,并且USB接口标准已经非常普及,所以此方案将会使用很普遍并且非常普及。我们也配备了USB摄像头。
缺点:USB协议非常复杂,不得不熟悉USB协议,但是USB协议学习要很长的时间,另外要增设USB的主从芯片(USB-HOST,比如SL811HS)。这也将会使我们的项目进展更加缓慢。
方案二
优点:采用美国OmniVision公司开发的CMOS彩色/黑白图像传感器芯片OV7620,此芯片的功能比较强大,外围元件的连接也很少,可以胜任。
缺点:需要自己连接硬件电路,采购CCD或CMOS模拟摄像头,并且FPGA内部必须设计驱动OV7620的电路逻辑。且转换过来的数据量可能比较大,而且需要FPGA里大量的BRAM作为数据缓存。
最终,我们选择了方案二作为我们图像采集的最终方案。
2.2.2 图像采集识别处理
图像采集处理单元主要包括图像的实时采集,平滑处理、图像区域分割、图像肤色提取、图像矩特征提取和匹配等几个部分。其目的是通过实时的图像采集,得到手势的图像信息,再进行处理得到相应的语义含义。
采集来的图像数据量大,采集来之后我们应对图像进行预处理,去除图像中的背景噪声,然后提取其特征,现在的特征提取方法有基于图像纹理的特征提取,基于图像形状的特征提取。对于采集得到的图像,其包含了大量的数据,而且采集来的图像的背景的复杂性以及含有噪声,我们要将图像进行预处理,包括对图像进行平滑,图像增强等一些预处理来消除噪声,背景等对后续处理的干扰。预处理的目的是改善图像数据,抑制不需要的变形或者增强某些对于后续处理来说比较重要的图像特征。
2.2.3 语音合成模块
一.利用语音合成芯片
芯片选择是OSYNO6188嵌入式中文语音合成芯片,通过异步串口接收待合成的文本,可直接通过PWM输出方式驱动扬声器,亦可外接单支三极管驱动扬声器,即可实现文本到声音(TTS)的转换。支持国家标准GB_2312 所有汉字。
一.自行设计语音合成系统
自行设计的语音系统首先要考虑方案的难易程度问题,目前技术上面采用时域和频域的方法进行语音合成。考虑到方案实现的问题以及现有器件情况,考虑采用较简单的波形编辑法,将较短的数字音频段(即合成基元)拼接并进行段音平滑后生成连续语流的方法。这种方法占用的存储空间大,但计算量小、计算速度快,而且合成语音自然度较高,显然比较适合于芯片性能较弱的嵌入式系统方面的应用。
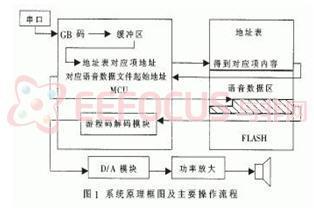
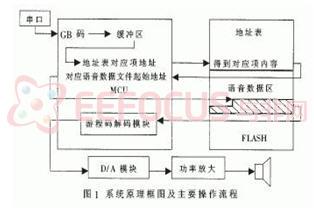
语音合成将采用串口与上位机进行连接。欲发音汉字的国标码(GB码)由串口送入MCU,MCU将其映射为Flash存储器地址表中对应项的地址,然后根据此地址取得对应项中的命令字,由MCU根据该命令字读取该汉字发音对应的语音数据,连续读出语音数据并以游程码解码算法解码后,按照语音采样时的固定速率通过D/A转换和功率放大播放。本文中语音采样速率为11025B/s。为满足应用需求,本文首先构建易于快速解码的语音库,根据特定Flash存储器的存储格式,以快速多查找表寻址及命令字预先存储的方式组织并存储在Flash存储器中,以满足语音播放的实时要求。同样,MCU的代码也要优先考虑速度而牺牲诸如模块化、可读性方面的要求。最后,出于实用性考虑,系统中需加入足够的输入缓冲区支持,以满足一次输入多个流字或整句的要求。
一.利用语音合成芯片
优点:利用现有的材料,可以加快整个课题的进度语音合成芯片已经成型,系统运行的质量和效果比自行设计的芯片效果要好系统的可靠性更高
缺点:芯片会增加整个系统的成本利用芯片无法充分利用FPGA的片上资源
二.自行设计语音合成芯片
优点:自主设计语音合成部分,增加了整个系统的技术含量和含金量,充分开发了Xilinx开发板的片上资源,降低了整个系统的成本
缺点:开发的难度加大,开发的周期加长,自主开发的系统没有现有的语音合成芯片功能强大以及稳定
综合考虑:我决定在方案的初期使用语音合成芯片,因为这样会加快系统的开发进程,让我们有更多的时间和精力放在手势识别和处理方面。
在方案的后期考虑自行开发语音合成芯片,利用FPGA的片上资源。
在这里我们分为两部分:前段文本分析部分和后端语音合成部分。
3、系统硬件设计
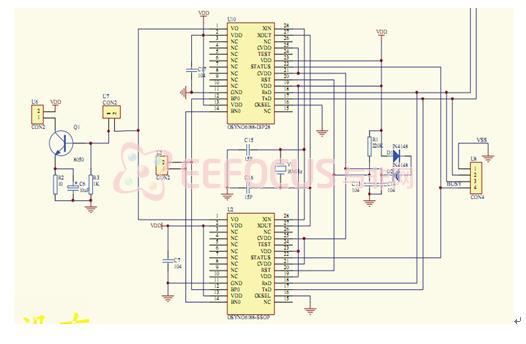
3.1 基于FPGA的片上系统设计
本文实现了一个基于FPGA的片上系统,该片上系统能够完成术中图像的实时采集、识别匹配和其他外设的控制。该系统用XILINX公司EDK(Embedded Development Kit)软件开发,是一个基于Microblaze的嵌入式系统。系统该体系架构如上图所示。
MicroBlaze软核是一种针对Xilinx FPGA器件而优化的功能强大的32位微处理器,适用于所有现产的FPGA器件MicroBlaze软内核和其它外设IP核一起,可以完成可编程系统芯片(SOPC)的设计MicroBlaze软内核采用RISC(reduced instruction system computer)架构和哈佛(Harvard)结构的32位指令和数据总线,内部有32个通用寄存器R0~R31和2个特殊寄存器程序指针(PC)和处理器状态寄存器(MSR)MicroBlaze还具有指令和数据缓存,所有的指令长度都是32位,有3个操作数和两种寻址模式,指令功能划分有逻辑运算,算术运算,分支,存储器读/写和特殊指令等,指令执行的流水线是并行流水线,它分为3级流水线:取指,译码和执行。 Microblaze软核,片上本地存储器,标准总线互连以及基于片上外设总线(OPB)的外围设备构成了MicroBlaze嵌入式系统。
3.2 视频采集模块设计
3.2.1 视频采集芯片
本项目使用的视频解码器是图像传感器采用美国OmniVision公司开发的CMOS彩色图像传感器芯片OV7620,该芯片将CMOS传感器技术与数字接口组合,是高性能的数字图像传感器,可提供彩色/黑白多种格式的输出;内置10位双通道A/D转换器,输出8位/16位图像数据;具有自动增益和自动白平衡控制,能进行亮度、对比度、饱和度等多种调节功能。可通过SCCB进行内部寄存器编程配置。只需要外接一个27MHz的晶振,就可输出数字视频流的同时还提供像素时钟PCLK、行参考信号HREF、垂直同步信号VSYNC,便于外部电路读取图像,并可编程设置HREF、VSYNC在图像局部开窗,输出窗口图像。它支持连续和隔行两种扫描方式,VGA与QVGA两种图像格式;最高像素为664492,帧速率为30fp8;数据格式包括YUV、YCrCb、RGB三种,能够满足一般图像采集系统的要求。OV7620内部可编程功能寄存器的设置有上电模式和SCCB编程模式。本系统采用SCCB编程模式,连续扫描,16位YUV数据输出。

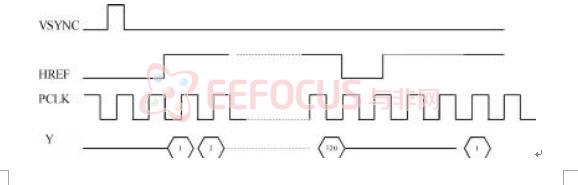
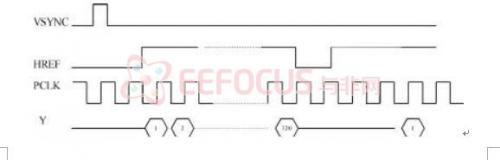
在这里我们要用到SCL和SDA对图像传感器进行配置,传感器有16位的数据输出还提供像素时钟PCLK、行参考信号HREF、垂直同步信号VSYNC。
VSYNC是垂直场同步信号,其下降沿表示一帧图像的开始;HREF是水平同步信号,其上升沿表示一行图像数据的开始 CLK表示输出数据同步信号 CLK表示输出数据同步信号
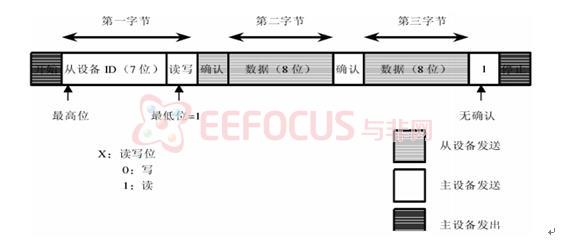
3.2.2 SCCB总线对OV7620的配置
OV7620的控制采用SCCB(SeriaI Camera ControlBus)协议。SCCB是简化的I2C协议,SIO-l是串行时钟输入线,SIO-O是串行双向数据线,分别相当于I2C协议的SCL和SDA。SCCB的总线时序与I2C基本相同,它的响应信号ACK被称为一个传输单元的第9位,分为Don’t care和NA。Don’t care位由从机产生;NA位由主机产生,由于SCCB不支持多字节的读写,NA位必须为高电平。另外,SCCB没有重复起始的概念,因此在SCCB的读周期中,当主机发送完片内寄存器地址后,必须发送总线停止条件。不然在发送读命令时,从机将不能产生Don’t care响应信号。由于I2C和SCCB的一些细微差别,所以采用GPIO模拟SCCB总线的方式。SCL所连接的引脚始终设为输出方式,而SDA所连接的引脚在数据传输过程中,通过设置IODIR的值,动态改变引脚的输入/输出方式。SCCB的写周期直接使用I2C总线协议的写周期时序;而SC-CB的读周期,则增加一个总线停止条件。OV7620功能寄存器的地址为0x00~0x7C(其中,不少是保留寄存器)。通过设置相应的寄存器,可以使OV7620工作于不同的模式。
SCCB的寄存器是EEPROM,由于是OV6620/OV7620的片内EEPROM,稳定性不高。虽然理论上SCCB写入一次,终生受用,但是数据容易丢失,因此,SCCB程序的写入应在读图像之前每次写入,并把IICENALBE拉高使能,使SCCB寄存器起作用。
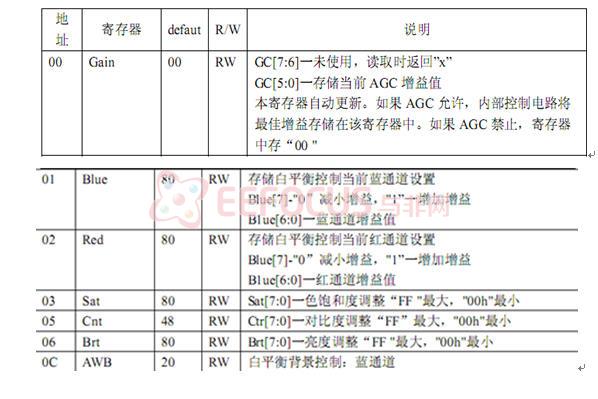
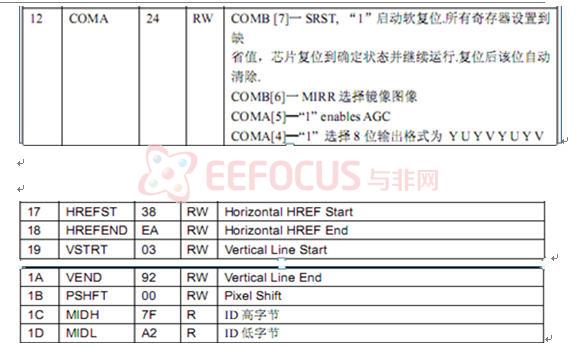
下面列出了一些常用的OV7620寄存器:
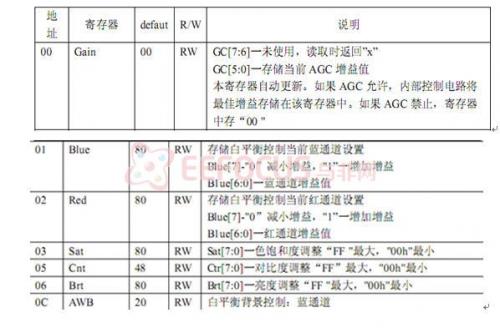
在对OV7620进行配置的时候,主设备必须做以下操作:
①产生开始/停止信号
②在 SCL上施加串行时钟
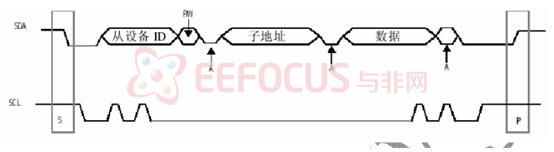
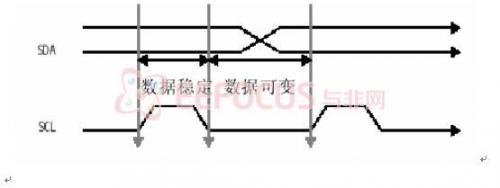
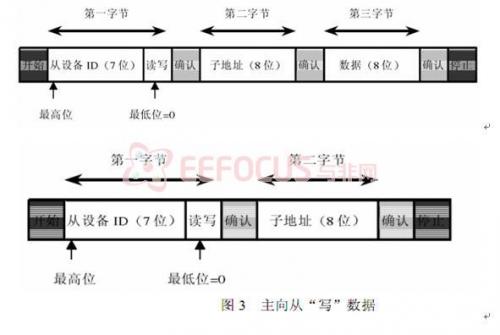
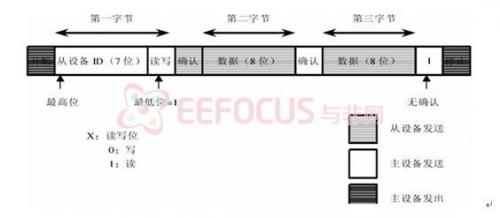
③将7位从设备地址,读写位和8位子地址串行放到 SDA 上
读的一方必须在确认位时间里拉低 SDA,返回一个确认位作为对写设备所写数据的确认。
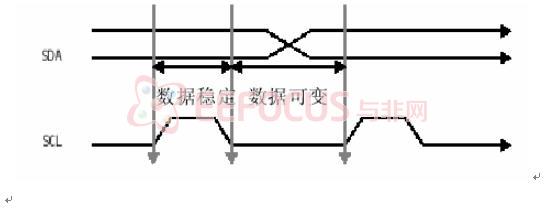
在写周期里,OV7620 返回确认位,在读周期里,主设备返回确认位,除非读的数据是最后一个字节。如果读的数据是最后一个字节,主设备并不返回确认位,通知从设备读周期可以终止。每一字节内,最高位总是先传输。读/写控制位是第一字节的最低位。标准 IIC 通信仅需两个管脚:SCL 和 SDA。 SDA 设置成开漏双向端口。SCL 为高时,SDA 上从高到低的转换表示开始。SCL 为高时,SDA 上从低到高的转换表示结束。只有主设备可以产生开始/结束信号。
除了以上两种情况外,协议要求 SDA 在时钟 SCL位高电平器件保持稳定。只有当 SCL为低时每一位才允许改变状态
OV7620 的 SCCB接口支持多字节读写操作。主设备必须在写周期而不是读周期内提供子地址。因此,OV6620/7620 读周期的子地址是前一个写周期的子地址。在多字节读写周期中,在第一个数据字节完成后,子地址自动递增,使得连续位置的存取可以在一个总线周期内完成。多字节周期改变了原来的子地址。因此,如果在一个多字节周期后有一个读周期,就必须插入一个单字节写周期来提供新的子地址。
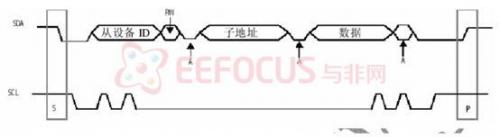
SCCB的具体实现:
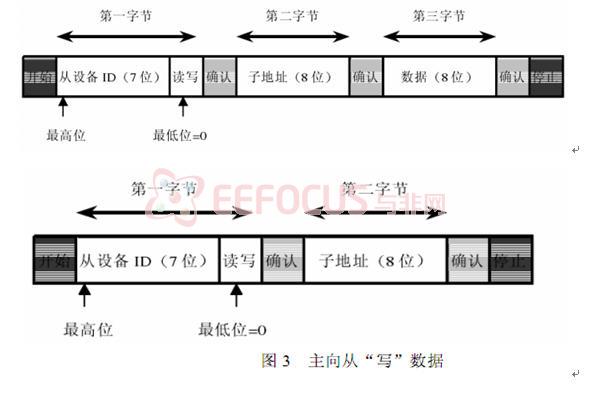
OV7620支持单个从设备.,当一只有唯一个从设备时,6620 ID须置为0XC0 (写)和0XC1 (读)。7620 ID是0X42(写)和 0X43(读)。 在写周期中,IIC 总线上的第一个字节是选择单个片内寄存器的子地址,第三个字节是读写该寄存器的数据。写一个未定义的子地址将被忽略。在读周期中,IIC 总线上的第一个字节是读写该寄存器的数据,子地址用前面的。读一个未定义的子地址,返回数据不定。
3.2.3 OV7620采集图像的流程
我们的采集是连续采集模式,用到了三个同步信号:像素时钟PCLK、行参考信号HREF、垂直同步信号VSYNC,在这三个信号中,由于我们采用的是GPIO来作为图像数据的采集端口,而经过我们的测试,GPIO端口的时钟频率在5MHz,而在我们的ov7620的三个同步信号里面,PCLK的周期最短,当ov7620采用27MHz的系统时钟频率的时候,默认的PCLK的周期为74ns,而我们的microblaze的中断响应时间远大于这个周期,在图像数据的匹配的时候,我们只能通过改变Ov7620的寄存器的值来降低ov7620的PCLK频率。通过设置时钟频率控制寄存器,可将PCLK的周期设为200ns。
3.2 语音合成模块
3.2.1语音合成芯片OSYNO6188
利用语音合成芯片OSYNO6188嵌入式中文语音合成芯片,通过异步串口接收待合成的文本,可直接通过PWM输出方式驱动扬声器,即可实现文本到声音(TTS)的转换。支持国家标准GB_2312 所有汉字。
该模块OSYNO 6188 提供一组全双工的异步串行通讯(UART)接口,实现与系统板相连接,进行数据的传输。OSYNO 6188利用TxD和 RxD 以及 GND 实现串口通信。其中GND 作为信号地。
其端口特性如下:1、 初始波特率:1200 bps ,起始位: 1 , 数据位:8 ,校验位:无,停止位:1 ,流控制:无。
信息终端以信息帧格式向 TTS 芯片发送命令码,对 TTS芯片进行系统设置。TTS芯片根据命令码及参数进行相应操作,并向信息终端返回命令操作结果。规定每个信息帧最多 56 个字节,第一个字节为开始字节 0x01,第二三四个字节为参数描述字节,后面最多跟着 50个数据字节,以 0x04为结束字节,最后一个字节为发送异或校验字节。

3.2.2语音合成芯片的数据包形式:
每次都是以数据包的形式进行传送,其形式如下:

实际输出范例:
输出数据包:0x1 0x80 0x87 0xE1 0xD5 0xE2 0xCA 0xC7 0xCE 0xD2 0xC3 0xC7 0xB5 0xC4 0xCA 0xD6 0xCA 0xC6 0xD3 0xEF 0xD2 0xF4 0xD7 0xAA 0xBB 0xBB 0xC6 0xF7 0xA3 0x8D 0xA3 0x8A 0x4 0xF1
输出数据包:0x1 0x80 0x87 0xE1 0xB8 0xC3 0xCA 0xD6 0xCA 0xC6 0xD2 0xE2 0xCB 0xBC 0xCA 0xC7 0xA3 0xC1 0xA3 0x8D 0xA3 0x8A 0x4 0xA7
输出数据包:0x1 0x80 0x87 0xE1 0xC3 0xBB 0xD3 0xD0 0xD5 0xD2 0xB5 0xBD 0xB8 0xC3 0xCA 0xD6 0xCA 0xC6 0xB5 0xC4 0xD2 0xE2 0xCB 0xBC 0xA3 0x8D 0xA3 0x8A 0x4 0xCD
4、软件设计
4.1 图像的预处理
在摄像头传入的信号受环境的影响,后期的转换,总要造成图像的某些降质。必须考虑对图像进行改善处理。对于手势识别系统,我们主要用到一些图像增强技术。
图像增强技术通常有两类方法:空间域法和频率域法。
空间域法主要是空间域中对图像像素灰度值直接进行运算处理。
频率域法只要是将图像变换到其他域中,对图像变换值进行一些操作后,再变换会原来的空间域。通常采用傅立叶变换对图像操作。
在本系统设计中,软件采用了图像的平滑,基本已经够用。而图像的变换域处理方法没有采用,主要是软件在时间域处理的效果已经够用了。
图像的锐化处理没有采用,因为在实现中发现效果不是很好,并且引入了噪声。
4.2.1 图像的平滑处理
本系统的平滑用到了模板操作平滑,将原图中的一个像素的灰度值和它周围邻近的八个像素的灰度值相加,然后求得平均值(除以9),取平均值作为新图中的灰度值。
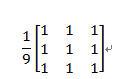
平滑模板可以滤掉一定的噪声,但是也有一定程度的模糊。这里,我们采用了不同的矩阵模板来消除不同情况下的噪声。其中用到的模板有:
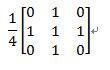
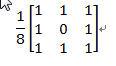
经过平滑处理后的图像接着送图像分割处理,从而分割出人体区域和背景图像区域。
4.2.1 图像的背景减法
图像背景减法在图像的分割的前期工作起到了一定的作用。
(1)初始化背景 没有前景目标进入环境之前,首先对背景连续采集n幅图像,通过这n幅图像,可以建立一个初始背景的统计模型,背景中的每个点i,定义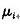
为该点的颜色期望,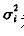 为颜色值分布的方差,有如下的公式: 为颜色值分布的方差,有如下的公式:
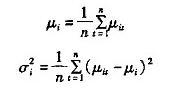
其中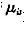 为i点在t幅图像中的颜色值。这样,所有的点 为i点在t幅图像中的颜色值。这样,所有的点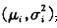 构成了初始背景模型。 构成了初始背景模型。
(2)前景区域的提取 初始背景建立以后,对于每一幅新采集的当前土地,就可以进行前景区域的提取了。设当前图像中点i的颜色值为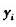 ,可以通过以下公式将图像二值化: ,可以通过以下公式将图像二值化:

其中,所有标志为1的点构成前景区域,为0的点构成背景区域,k为自行设置的常数。K值的选取对分割效果具有直接的影响,当k过小时,提取了手部区域的同时还提取了部分的背景区域;当k过大时,会使提取的手部区域不完整。通过大量的实验,选取k=4时可以取得较好的分割结果。
(3)背景模型更新 随着时间的推移,背景中不可避免的会发生一些变化。如果一直使用最初的背景模型,长时间后就会发生较大的误差。为了解决这个问题,采用了背景模型更新的方法。设平均值和方差分别为时刻t点i的颜色期望和方差, 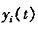 为时刻t采集到的图像中点t的颜色值,则t+1时刻,有: 为时刻t采集到的图像中点t的颜色值,则t+1时刻,有:
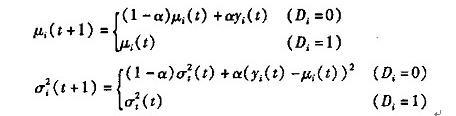
其中α为学习率,可根据实际情况进行调解。这样,背景模型在每一时刻不断的得到更新,以便和实际情况尽可能保持一致。
实现如下:
n张图片中一副背景图片:

图1-1 背景图片
前景图片混合背景图片:

图1-2 前景图片混合背景图片
背景图像减法处理之后的结果

图1-3 背景减法处理后得到的图像
观察处理结果可以得到,手部的图片大致地保存下来,背景图片绝大部分被剪掉了。
背景减法的缺点是,如果背景和前景颜色接近,前景图片的数据会丢失,如上图,手部图像里面有黑色条纹,这是背景图片部分像素值和前景(及手势图像像素)接近,而被减掉了。另外,经背景减法处理后的图像,边缘部分会出现锯齿,于是要继续进行形态学滤波、空洞填充和中值滤波处理的到最终的分割结果。
背景图像减法需要和图像肤色提取一起使用,相辅相成才能得到比较好的处理结果。
4.2 图像的肤色提取
图像处理中区别人体与外界的一个很大的特征就是肤色,通过这一特征可以将图像分割成众多分立的小块。经过这一个操作后图像面积大大减少,提高了处理效率的同时又减少了大量外界环境的干扰,是图像处理中的很重要的一环。
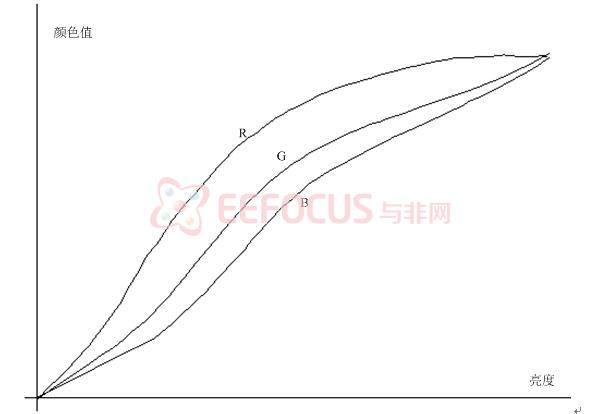
人体的皮肤肤色受很多种因素的干扰,这手部图像的提取带来了很多的困难。例如不同人种的肤色就有不同差异,不同的人也有细微的差异,就算是同一人不同身体不同部位肤色也有些差异。肤色同样受到外界环境的影响,这其中最主要的就是光照。经过分析发现,光照因素分为光照强度,是否直射和光照颜色这几个部分,其中后两者是可以人为控制的(手的正面比较光滑,在光直接照射时出现反射,导致摄像头捕获的数据是纯白色,而大多数干扰也是白色),而光照强度择优光照距离的远近,是否遮挡以及周围环境反射情况决定。如果在室内,按目前的光照环境(光照环境分为自然光环境和人工光环境,目前照明主要采用日光灯,可以忽略光照颜色的影响,照明比较充分时,距离也可以忽略),可以只考虑遮挡带来的肤色变化,而遮挡实质也就是亮度的变化,如果有某个颜色状态不受亮度影响或与亮度是简单的线性关系(也就是零阶对应关系或一阶对应关系,高于一阶则对干扰过于敏感,规律性不强)。
2.1 颜色空间的选择肤色提取常用的颜色空间除RGB外还有YUV、HSV等,在光照变化时,肤色在RGB颜色空间中的值都有较大的改变,有一定的线性度,但很容易受干扰(肤色产生较小的变化时,其值变化过于剧烈),不能直接用来做肤色提取,如果在YUV空间中,则Y值剧烈变化,线性度较差,而U、V则出现非线性变化,也不便于作为肤色提取的颜色空间,而通过对HSV空间中的分析也不太理想,主要是在这些之中S、V虽然波动相对较小,但规律性不强,H几乎捕捉不到其规律性,且其转化过程也过于繁琐,相比之下RGB略为占优。
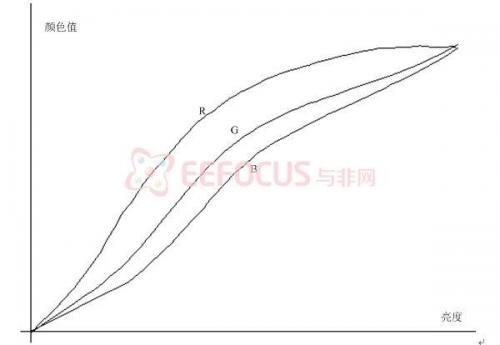
图2-4 RGB随亮度的增加的变化示意图
2.2 肤色的特征值
在观察HSV颜色空间中的H值转化时发现R、G、B相互之间差值的波动范围较小,而且观察R-G与G-B比H值更加有效,因为它们在亮度改变时只有微小的波动,例如在对某一个人进行测试时R-G仅在15-35之间波动,G-B则在18-33波动,且波动并不是由光照直接导致,其证据就是在光照比较强烈的情况下和光照很弱的情况下,其波动的范围并没有因此而改变,监狱对这个特性的研究,我们提出了一种不同于以往的肤色提取的方法,下面的公式就是将肤色提取并转化为灰度图像的一个经验方程。
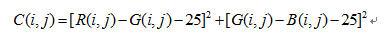
上式中:C表示表征肤色的量(肤色标量),数值越小越接近肤色;R、G、B为RGB颜色空间的三种颜色的值;i,j表示横向和纵向的坐标值。下面的修正公式各参数的含义与此处一样。
2.3 干扰抑制由于肤色亮度范围也并不是越大越好,在过亮和过暗的情况下会引入很多不必要的干扰,需要依据亮度的范围对这些干扰进行抑制。为了简化计算,在已有的基础上可以仅用G来代表亮度(C较大时修正值的比重很小,可以忽略,C较小时R,G,B相互间的差在一个很小的范围内,G与亮度的线形相关度较好,且两个差值都与G有关),肤色的亮度范围大致在10-170,抑制项选用|90-G|时效果最好,经过多次实验,最终将这一系数确定在了2,这样的补偿可以使阈值在一个范围内调整,对过亮和过暗的颜色进行抑制作用,最终得到的肤色经验公式为:
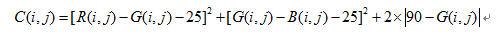
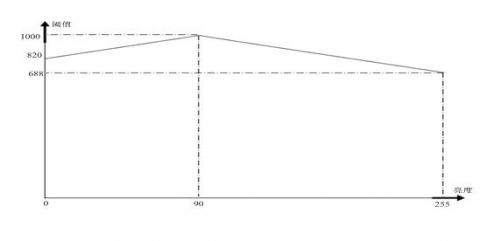
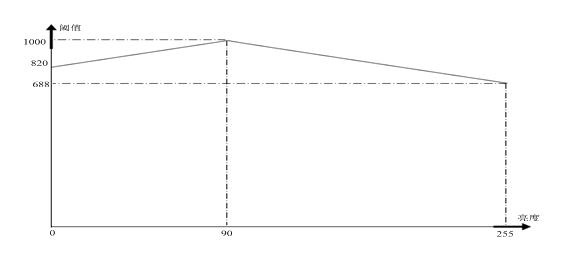
图2-5动态阈值示意图
2.4 表征肤色的二值化图像
由于公式中涉及到了二次项,而修正项为一次项,这使得灰度值与G-B,G-B在三维空间中表现为一个类似抛物面的曲面,这样,肤色转变到非肤色时,C的值变化将会很迅速(阈值为1000时,R-G或G-B变化1,阈值将变化45-65),如果要将灰度图像转化为二值化图像,阈值的范围将比较自由,经过分析发现,不考虑修正项时,阈值取在200-900间的值时,图像的改变并不大。从抑制干扰的角度出发,以及对后面的面积处理算法的综合考虑,我们将阈值定在1000。
我们在后期的处理中主要用二值化后的图像进行形态学的处理,而灰度图像则由于其数据信息量较大,用于后期的特征提取的修正。
二值化图像的取得方法是阈值的处理,其中阈值有表征肤色的RGB值求出,当算得量在阈值内时,取为1(颜色值为255),当算得量超过阈值时,取为0(颜色值为0)。
4.3 区域分割处理
肤色提取的确将图像处理成了一块块的分立区域,但系统并不知道这些区域的位置、大小等信息,在进行后续的处理前必须将这些区域分割出来。
4.3.1 垂直投影与分割
图像经过肤色提取之后形成一个个分立的肤色区域,当然也存在一些干扰,接下来的工作就是将这些区域进行分割,保证最终进行识别时每个单元都只有一块简单肤色区域,而且要求算法具有优良的抗干扰性。
图像中,能够通过肤色提取筛选的主要是人的面部,手以及手臂。从人体结构与一些平时的动作考虑,如果在水平方向上投影,则会经常出现手与手的重叠或手与脸的重叠(这里不分割手与手臂的区域),而在垂直方向则相对不太容易形成重叠。基于对此的思考,我们只进行了垂直方向的投影,用来分割垂直的区间。
垂直投影只需在肤色处理时同步将所有值向下累加即可:
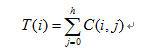
上式中:T表示投影值;C表示肤色标量;i,j分别表示横向和纵向坐标。
分析这些投影曲线,将其中投影值较大且连续分布的区域分割出来,在图像上,就将图像分割成了垂直的长条状的区间,而这些长条区间还是有可能是由多个重叠的投影叠加而成,所以必须进行进一步处理。
4.3.2 水平积分与分割
垂直投影并没有将各个区域分割开,但却为水平投影提供了可行性。如果对每个区间都再进行一次投影,工作量比较大,其实有很多简单的修改方式:在作垂直投影时,顺带做一次水平从左到右积分,那么垂直的长条图像右侧积分值减去左侧的积分值就可以得到投影值,减少循环次数。在获取水平投影后,在重复刚才的分割就可以粗略的找到肤色区域存在的区间。
4.3.3 分割后的整理
在实现后上述分割后发现,即使区间划分的阈值取得再适当也会出现将一个大的连续的区域被分割成多个小区域的情况,如果直接将相距比较近的区域进行合成,则由会出现有些较近的区域无法分割开的情况,而且小面积的干扰也有可能被和并成一个大区间,引入不必要的麻烦,针对这种情况,我们将与大区间相邻的小区间合并,而一定范围内无区间或只有小区间则将其舍弃,这样,大区间分离的一些小区间可以被合并,而聚在一起的干扰则由于没有一个大区间作为核心而被舍弃,在解决了区域分裂的情况的同时又实现了一些抗干扰的功能。
4.3.4 面积筛选算法的采用
在二值化图像经过水平和垂直方向上的积分筛选之后,总会有些肤色接近的区域遗留,但是,这些区域大小不是很大,于是,我们这里采用了面积筛选的算法。
在图像对水平和垂直方向进行投影的同时,计算水平和投影方向阈值连续部分的长度,得到矩形区域的面积。
在这些面积中,将矩形面积过小的区域予以删除,得到如下的效果。

图3-1应用面积删选算法处理图片
分析结果可以看到,因为手部矩形区域面积比较大,所以,手部矩形区域之外的接近肤色干扰小区块被去除掉了。当然,矩形面积算法也有瑕疵的地方,手指上端的图像被切掉了一小部分,而且手部矩形区域依然有干扰点的存在。
但是,综合整体效果,可以看出,手部的形态特征得到了保存,因此矩形区域面积筛选算法可行。在后面的图像矩特征的提取已经够用。
4.4 图像矩特征提取及分配
即使知道了手势存在的区域,面积状况,可如此巨量的数据对于识别来说还是过于庞大了,面对这一问题,最常见的方法就是只提取轮廓,因为图像本身是一块封闭的区域,那么轮廓和区域图像可以相互转换,也就是说:在这种情况下,轮廓和区域图像拥有同样的信息量。而轮廓数据少的多,而且具有很多一维的特性,可以很方便地转成一维数据来进行分析,这比直接分析区域的二维特征更加简单和直观。
在提取轮廓特征后进行几何矩的计算,则形态学特征转换成一维数据。
4.4.1 图形矩定义简单说明
将一幅图像看成一个二维密度分布f(x,y),函数值f(x,y)表示点(x,y)处图像像素的亮度值。
图像f(x,y)的(p+q)阶几何矩的定义为:
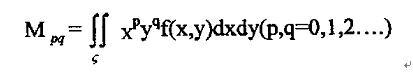
其中f(x,y)是图形函数
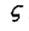 是图像亮度函数f(x,y)定义的像素空间区域 是图像亮度函数f(x,y)定义的像素空间区域
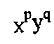 是变换核 是变换核
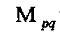 称为p+q级几何矩。 称为p+q级几何矩。
4.4.2 使用几何矩进行图像的形状描述
图像不同阶的几何矩表示了图像亮度分布的不同空间特征。因而一个几何矩集可以成为一幅图像整体形状的描述子。下面说明其中一些几何矩的物理意义。
零阶几何矩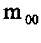 代表一副图像的总高度。对于剪影图像, 代表一副图像的总高度。对于剪影图像,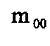 是目标区域的集合面积。 是目标区域的集合面积。
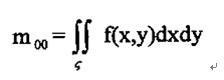
一阶几何矩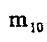 , ,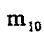 是图像关于x轴和y轴的亮度矩。其亮度的“矩心” 是图像关于x轴和y轴的亮度矩。其亮度的“矩心”
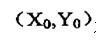 为 为
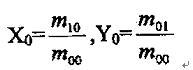
对于一副剪影图像,点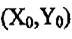 给出了图像区域的几何中心。通常,能方便计算出将参照系原点移至图像亮度矩心的几何矩,称为中心矩。这一变化使矩的计算独立于图像的参照系。 给出了图像区域的几何中心。通常,能方便计算出将参照系原点移至图像亮度矩心的几何矩,称为中心矩。这一变化使矩的计算独立于图像的参照系。
中心矩:一幅图像相对于亮度矩心所计算出来的几何矩成为中心矩。它表示为:
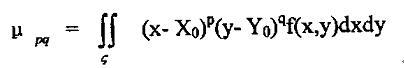
这一矩相当于将坐标原点移至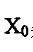 和 和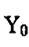 处,并计算得到了对于图像位移不变的中心矩 处,并计算得到了对于图像位移不变的中心矩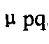 。 。
4.4.3 几何矩不变量
图像平面变换中具有不变形的几何矩函数被应用与目标鉴别和模式识别等领域中,图像的形状特征通过一系列的计算能得到一组几何矩特征不变量的集合,能够用来识别可以的不同大小和不同方向上的具有相同特征的某一类图像。
根据Hu氏理论,通过各种不同级别几何矩的数学组合,可以得到七个特征量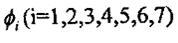 。这七个特征量具有当图像f(x,y)移动、转动与比例大小改变时保持其数值不变的特性。因此称它们为不变矩特征量。这七个分量分别是: 。这七个特征量具有当图像f(x,y)移动、转动与比例大小改变时保持其数值不变的特性。因此称它们为不变矩特征量。这七个分量分别是:
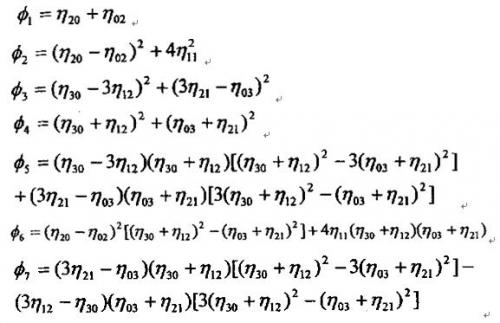
其中: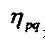 是归一化的中心矩: 是归一化的中心矩:
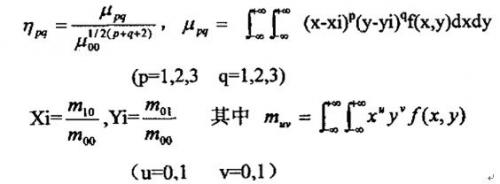
不变矩特征量的平移、移动与比例大小改变而其数值不变的性质以及其它这里就不证明了。
正是由于几何矩具有这样的不随位置、方向、大小的变化而变化的良好性质,所以才将这一方法引用到手势识别(手势图像的位置、方向、大小极易发生变化)这一系统中来。
4.4.4 本系统的特征空间
考虑到实现的效果和计算复杂度,决定使用前四个不变矩特征量,并利用这四个矩的集合组合形成特征向量,由于这每一分量都具有旋转、平移、比例等不变性,故由其组合而成的矢量也具有相应的不变性。这样可以初步形成特征空间,取七个特征向量的前四个组合成特征空间。
4.4.5 图像矩特征的匹配
一副图像或一组图像集的特征向量或特征矩阵必须与先验存储的一类特征向量或特征矩阵进行比较和匹配,以便建立给定图像和标准图像之间的一致性关系,用于模式识别、目标鉴别和图像分类中。
对于一种矩特征向量的前n个元素可组成一个有限特征向量。所以,我们用下式来表示第k个图像所对应的一个特征向量:
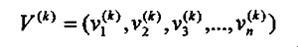
我们的样本图像取了四个特征量组合成矩特征向量。
下面的工作即是计算矩特征匹配算法的选择。
计算方法有:
加权欧几里德距离法,相关系数法,对数距离法。
本系统主要用到加权欧几里德距离法。
向量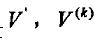 的加权欧几里德距离法定义如下: 的加权欧几里德距离法定义如下:
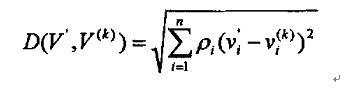
这里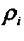 表示对分量 表示对分量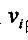 的加权系数,这样做可以在动态范围内平衡各变量。使得函数D取最小值的k所对应的图像被选作匹配图像。 的加权系数,这样做可以在动态范围内平衡各变量。使得函数D取最小值的k所对应的图像被选作匹配图像。
4.5 实现结果及分析
系统在Windows XP 的VC6.0环境下工作,再移植到Virtux-5开发板上。故这里只做VC6.0处理的说明。
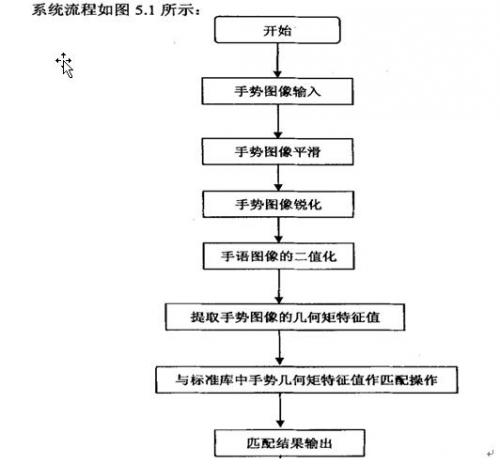
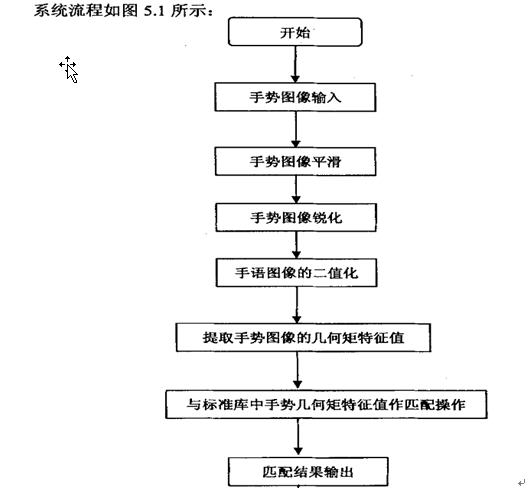
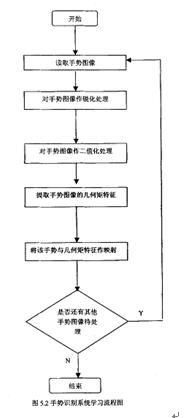
图5-1 系统流程图说明
4.5.1 手势图像几何矩的提取
下面列出几何矩计算的部分源码:
finger_charactor DIBBARYCENTERMOMENT(unsigned char *imgBufIn,int imgWidth,int imgHeight)
{
int lineByte=(imgWidth+3)/4*4;
int PixelValue;// 图象象素值
float nBarycentrMoment;//图像重心矩
float m00,m10,m01;//0次矩m00,x方向的一次矩m10,和y方向的一次矩m10
int BarycenterX,BarycenterY;//重心x y坐标
int i,j;
float temp;
finger_charactor temp_charactor;
m00=0;m01=0;m10=0;nBarycentrMoment=0;
int m02,m20,m11,m03,m30,m21,m12;
float u20,u11,u21,u30,u02,u12,u03;
float t1,t2,t3,t4,t5,t6,t7,t8,t9;
m02=0;m20=0;m11=0;
m03=0;m12=0;m21=0;
m30=0;u20=0;u11=0;
u21=0;u30=0;u02=0;
u12=0;u03=0;t1=0;
t2=0;t3=0;t4=0;
t5=0;t6=0;t7=0;
t8=0;t9=0;
//求0次矩m,x方向的一次矩m01和y方向的一次矩m10
for(j=0;j<imgHeight;j++)
{
for(i=0;i<imgWidth;i++)
{
PixelValue=*(imgBufIn+i*lineByte+j)/255;
m00=m00+PixelValue;
temp=i*PixelValue;//有问题的地方
m01=m01+temp;
temp=j*PixelValue;
m10=m10+temp;
}
}
BarycenterX=(int)(m01/m00+0.5);
BarycenterY=(int)(m10/m00+0.5);
printf("%d,%d\n",BarycenterX,BarycenterY);
*(imgBufIn+BarycenterX*lineByte+BarycenterY)=0;
*(imgBufIn+(BarycenterX+1)*lineByte+BarycenterY)=0;
*(imgBufIn+BarycenterX*lineByte+BarycenterY+1)=0;
*(imgBufIn+(BarycenterX+1)*lineByte+BarycenterY+1)=0;
int ii,jj;
ii=0;jj=0;
for(j=0;j<imgHeight;j++)
{
for(i=0;i<imgWidth;i++)
{
PixelValue=*(imgBufIn+i*lineByte+j)/255;
m00=m00+PixelValue;
temp=i*PixelValue;//有问题的地方
m01=m01+temp;
temp=j*PixelValue;
m10=m10+temp;
m02=m02+(i-BarycenterX)*(i-BarycenterX)*PixelValue;
m20=m20+(j-BarycenterY)*(j-BarycenterY)*PixelValue;
m11=m11+(i-BarycenterX)*(j-BarycenterY)*PixelValue;
m30=m30+(j-BarycenterY)*(j-BarycenterY)*(j-BarycenterY)*PixelValue;
m03=m03+(i-BarycenterX)*(i-BarycenterX)*(i-BarycenterX)*PixelValue;
m21=m21+(j-BarycenterY)*(j-BarycenterY)*(i-BarycenterX)*PixelValue;
m12=m12+(i-BarycenterX)*(i-BarycenterX)*(j-BarycenterY)*PixelValue;
}
}
u20=m20/(m00*m00);u02=m02/(m00*m00);
u11=m11/(m00*m00);u21=m21/(pow(m00,2.5));
u12=m12/(pow(m00,2.5));u30=m30/(pow(m00,2.5));u03=m03/(pow(m00,2.5));
t1=m02/(m00*m00)+m20/(m00*m00);
t2=((m20-m02)/(m00*m00))*((m20-m02)/(m00*m00))+4*(m11/(m00*m00))*(m11/(m00*m00));
t3=m20*m02/(m00*m00*m00*m00)-(m11/(m00*m00))*(m11/(m00*m00));
t4=u02+u20;
t5=(u20-u02)*(u20-u02)+4*pow(u11,2);
t6=(u30-3*u12)*(u30-3*u12)+pow((3*u21-u03),2);
t7=(u30+u12)*(u30+u12)+(u03+u21)*(u03+u21);
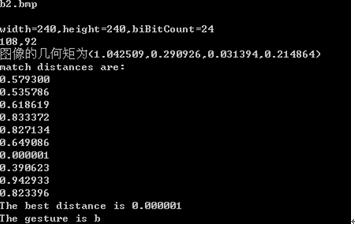
printf("图像的几何矩为(%f,%f,%f,%f)",t4,t5,t6,t7);
temp_charactor.t1=t4;
temp_charactor.t2=t5;
temp_charactor.t3=t6;
temp_charactor.t4=t7;
return temp_charactor;
}
4.5.2 手势图像的匹配在特征匹配过程中,我们选择的是改进的欧式距离。
利用欧几里德距离,我们可以这样定义输入的手势图像与手势库中的任一手势图像之间的距离: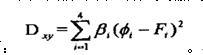 。 。
分别计算库中各手势图像与输入图像的距离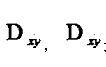 最小的那副图像即为与输入手势匹配的手势。 最小的那副图像即为与输入手势匹配的手势。
其源码如下:
void match(finger_charactor temp)
{
int i;
/* temp.t1=temp.t1*100;
temp.t2=temp.t2*100000;
temp.t3=temp.t3*1000000;
temp.t4=temp.t4*100000;*/
float distance[NUMBER];
float lib[NUMBER][4]={
{0.978988,0.033434,0.041461,0.463083},//1
{0.738859,0.200313,0.008426,0.096310},//2
{0.695933,0.140033,0.004225,0.120884},//3
{0.585566,0.082715,0.014987,0.063054},//4
{0.650015,0.069188,0.013489,0.019868},//5
{0.812733,0.103417,0.054060,0.005729},//a
{1.042509,0.290926,0.031394,0.214864},//b
{0.932284,0.033224,0.030549,0.236714},//c
{0.571468,0.042114,0.011919,0.011260},//d
{1.186403,0.272240,0.330265,0.576809},//e
{0.060099,0.001802,0.000009,0.000001},//f
{0.045080,0.000206,0.000004,0.000001},//g
{0.057199,0.000116,0.000021,0.000025},//h
{0.046879,0.000133,0.000014,0.000003},//i
{0.050615,0.000029,0.000029,0.000005},//j
{0.054486,0.000735,0.000006,0.000001},//k
{0.059298,0.001286,0.000066,0.000056},//l
{0.043326,0.000131,0.000004,0.000000},//m
{0.046381,0.000206,0.000023,0.000002},//n
{0.051253,0.000032,0.000061,0.000008},//o
{0.051904,0.000511,0.000055,0.000013},//p
{0.052215,0.000403,0.000011,0.000004},//q
{0.059072,0.001608,0.000030,0.000013},//r
{0.043743,0.000254,0.000011,0.000000},//s
{0.044977,0.000256,0.000012,0.000001},//t
{0.056229,0.001272,0.000030,0.000013},//u
{0.074957,0.001632,0.000190,0.000040},//v
{0.046419,0.000015,0.000032,0.000002},//w
{0.050211,0.000031,0.000018,0.000001},//x
{0.051339,0.000011,0.000041,0.000003},//y
{0.059218,0.000423,0.000142,0.000003}//z
};
char gesture[NUMBER][2]={"1","2","3","4","5","a","b","c","d","e",
"f","g","h","i","j","k","l","m","n","o",
"p","q","r","s","t","u","v","w","x","y","z"
};
for(i=0;i<NUMBER;i++)
{
distance=fabs(temp.t1-lib[0])+fabs(temp.t2-lib[1])+fabs(temp.t3-lib[2])+fabs(temp.t4-lib[3]);
}
printf("\n");
printf("match distances are:");
printf("\n");
for(i=0;i<NUMBER;i++)
{
printf("%f\n",distance);
}
float best_distance=distance[0];
int best_flag=0;
for(i=1;i<NUMBER;i++)
{
if(best_distance>distance)
{
best_distance=distance;
best_flag=i;
}
}
printf("The best distance is %f",best_distance);
printf("\n");
printf("The gesture is %s",gesture[best_flag]);
printf("\n");
}
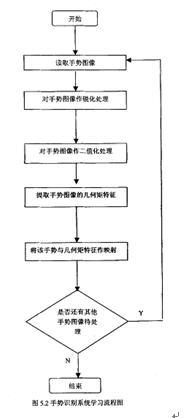
4.5.3 手势库样本的建立样本库的建立,我们采用了国际手语中的26个英文字母作样本,每个手势取三个图片,求得特征矩,从而建立样本库。其工作流程如下:
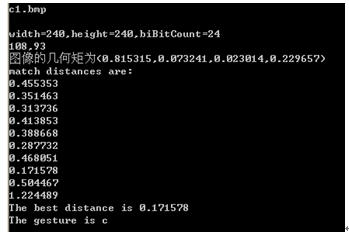
4.5.4 实际运行情况
这是将采集到的图像进行分割处理之后得到的图像:
 
 
c1.bmp(意思为C) b2(意思为b)
在PC终端运行情况如下。
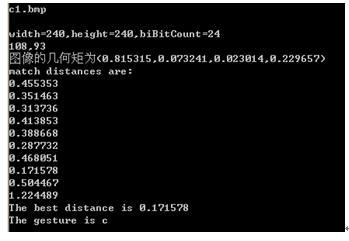
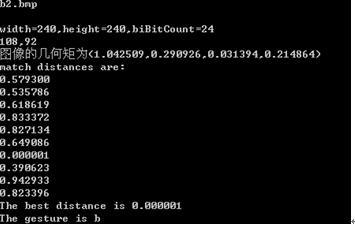
经过各个手势的测试之后,手势的识别率只有60%,不是很高,主要是手势库建立还没有完善,需要很多次的数据和测试,统计完成。 |
|