|

- UID
- 1029342
- 性别
- 男
|

Linux 网络文件系统简介
网络文件系统(NFS)协议是由 Sun MicroSystem 公司在 20 世纪 80 年代为了提供对共享文件的远程访问而设计和实现的,它采用了经典的客户机/服务器模式提供服务。为了达到如同 NFS 协议通过使用 Sun 公司开发的远在本机上使用本地文件系统一样便捷的效果,NFS 通过使用远程过程调用协议(RPC Protocol)来实现运行在一台计算机上的程序来调用在另一台远程机器上运行的子程序。同时,为了解决不同平台上的数据交互问题,它提供了外部数据表示(XDR)来解决这个问题。为了灵活地提供文件共享服务,该协议可以在 TCP 协议或者是 UDP 协议上运行,典型的情况是在 UDP 协议上运行。在此基础上,NFS 在数据的传送过程中需要 RPC 命令得到确认,而且在需要的时候会要重传,这样既可以通过 UDP 协议获得较高的通信效率,也能通过 RPC 来获得较高的通信可靠性。
由于 NFS 基于 C/S 模式提供服务,所以它的核心组件主要包括客户机和服务器两部分。图 1 详细说明了 NFS 的主要组件以及主要的配置文件。在服务器端,portmap、mountd、nfsd 三个监控程序将在后台运行。portmap 监控程序用来注册基于 RPC 的服务。当一个 RPC 的监控程序启动的时候,它告诉 portmap 监控程序它在哪一个端口进行侦听,并且它在进行什么样的 RPC 服务。当一个客户机向服务器提出一个 RPC 请求,那么它就会和 portmap 监控程序取得联系以确定 RPC 消息应该发往的端口号。而 Mountd 监控程序的功能是来读取服务器端的/etc/exportfs 文件并且创建一个将服务器的本地文件系统导出的主机和网络列表,因而客户机的挂接(mount)请求都被定位到 mountd 监控程序(daemon)。当验证了服务器确实具有挂接所请求的文件系统的权限以后,mountd 为请求的挂接点返回一个文件句柄。而 nfsd 监控程序则被服务器用来处理客户机端发送过来的请求。由于服务器需要同时处理多个客户机的请求,所以在缺省情况下,操作系统将会自动启动八个 nfsd 线程。当然,如果 NFS 服务器特别忙的时候,系统有可能根据实际情况启动更多的线程。
图 1 网络文件系统简图
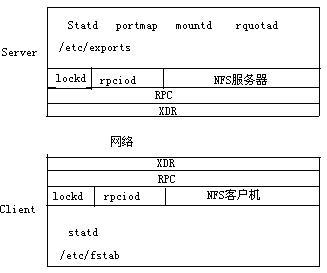
NFS 的客户机与服务器之间通过 RPC 进行通信,通信过程如下所示:
- 用户将 NFS 服务器的共享目录挂载到本地文件系统中。
- 客户访问 NFS 目录中的文件时,NFS 客户端向 NFS 服务器端发送 RPC 请求。
- NFS 服务端接收客户端发来的 RPC 请求,并将这个请求传递给本地文件访问程序,然后访问服务器主机上的一个本地的磁盘文件。NFS 服务器可以同时接收多个 NFS 客户端的请求,并对其进行并发控制。
- NFS 客户端向服务器主机发出一个 RPC 调用,然后等待服务器的应答。NFS 客户端收到服务器的应答后,把结果信息展现给用户或应用程序。
NFS 下的数据备份、恢复的主要功能
对数据进行备份与恢复是保证数据安全和业务连续性的非常成熟的做法。在 Linux 下的本地文件系统(例如 Ext2、Ext3 等)中,数据备份和恢复一般采用常规的办法来进行操作,例如使用 Tar、Archive 等。而对于 NFS 来说,其数据备份需要采用量身定制的方法来进行。
为了保证数据在灾难环境中的可用性和业务连续性,针对它的数据备份、恢复方案应具备如下重要功能:
- 通过对系统重要数据的快速备份,切实保证系统数据的安全;
- 可以根据指令完成备份系统的实时切入,保证服务不被中断,保持系统持续运行的能力;
- 通过实时记录所有文件的操作日志,系统管理员能够在发生灾难的情况下对日志进行分析和取证,从而发现入侵者的蛛丝马迹。
NFS 多版本备份技术
为了保证服务器出现故障后能迅速恢复,要求系统数据能快速恢复到一个最近的正确状态,所有这些都需要多版本技术的支持,通过同步记录文件的在某些时刻的状态,在整个系统范围内建立起类似于数据库系统的”检查点”,以保证上述目标的实现。
对于多版本系统而言,需要较好地解决两个方面的问题:性能和空间利用率。对于前者,最主要的是保证在生成版本的时候能够快速完成,同时恢复时也具有较好的性能。此外,系统引入多版本造成的整体开销也应该比较理想。对于第二点,主要考虑是节约磁盘空间,虽然随着硬件技术的不断发展,磁盘空间越来越大,性价比也越来越高,但是当版本较多而且文件数量较多、较大时,引入多版本增加的开销也可能相当可观,同时,较大的空间也意味着版本生成时可能需要更多的写操作,这样也必将影响总体性能。
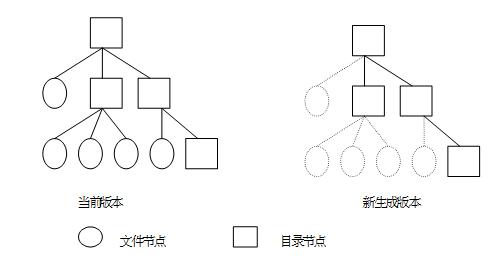
为了保证引入多版本特性后文件系统仍具有较好的性能,以及保证较高的空间利用率,我们开发了一种高效的惰性版本生成算法。主要思想是:生成版本时不进行文件的复制,仅复制目录结构,在新版本生成后到下一版本生成前,如果有文件需要修改,则第一次修改时对该文件进行复制,从而保证该文件状态与对应的版本保持一致。
在一般情况下,目录结构的数据量远远小于文件的数据量,因而这种方法可以大大降低版本生成时需要复制的数据量,因而具有较高的性能。同时,这种把单个文件版本生成的实际操作推后到非做不可的时候,并且任意文件在两次版本之间最多生成一次版本,因此这种惰性策略可以使需要实际生成版本的文件数量达到最少,同时还可以把多个文件版本生成操作分散到具体的文件操作中,从而避免了集中的一次性版本生成方法可能造成的服务暂时停顿的问题。
版本生成后的结构如图 2 所示。
图 2 多版本生成示意图
具体算法包括两个部分,即版本生成算法和文件第一次修改处理算法,版本生成算法主要完成版本生成工作,主要过程如下:
- 找到需要形成版本的最高层目录作为原目录;
- 利用文件系统提供的函数,生成新的目录节点,称为新目录;
- 把原目录中的结构复制到新目录;
- 在原目录中找到所有的子目录,重复 2、3 步;
- 把新的子目录对应的 inode 号替换上一层目录中的老 inode 号;
- 重复上述过程,及到目录树中的所有目录得到复制为止。
在上述策略中,新版本并没有复制所有的文件,只是在复制的目录结构中记录下了该文件的 inode 号(即复制了目录的结构,而不是把文件都进行复制,从而节省了存储和计算资源),因此,当有 NFS 请求需要对文件进行版本生成后的第一次修改时,需要复制该文件,生成新的版本。该实现过程参见如下流程图:
图 3 写时复制算法示意图
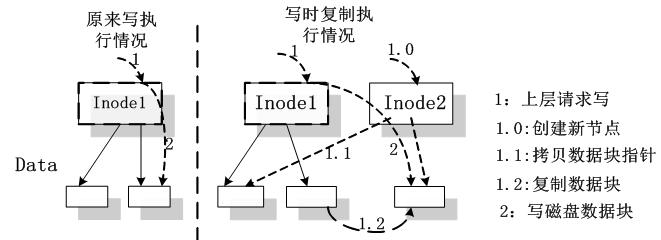
这种文件复制策略其实是一种惰性算法,也即我们常说的写时复制的方法,这个方法在 Linux 操作系统的子进程对父进程资源的继承中有所体现。这个策略一方面可以最大限度减少复制文件的数量,另一方面则可以避免瞬间过大的文件复制工作量,影响文件服务的性能。该算法的过程如下:当文件操作为写操作时,判断该文件是否版本生成后的第一次写操作;若是则利用文件系统提供的底层函数生成一个新的文件,复制源文件的数据到新生成的文件,同时把该文件当前版本的 inode 节点中的版本号置为当前版本号,这样新文件就成为该文件的最新版本。
虽然我们采用的算法可以有较好的性能,存储开销也是最优,但是,每次版本生成肯定会造成服务性能的下降和空间的占用,而这些代价在一个比较安全可靠的环境中是可以适当降低的,即当系统比较安全的时候,可以选择让系统以更低的频率进行版本生成,相反,当系统安全状况比较糟糕的时候,可以通过提高版本生成频率适当降低服务性能来获得更高的数据安全性能,当系统处于紧急状态时,甚至可以要求立即进行版本生成。
基于这些考虑,我们采用了自适应的备份策略,灾情评估系统可以动态评估系统的灾情程度,然后可以立即修改版本生成策略,以适应当时的安全要求。
NFS 数据恢复技术
企业应用 NFS 的一个重要目标就是要保证系统的高可用性,即使在出现严重灾难、故障、攻击等情况下能具有较好的生存能力。因此,当一个系统出现故障时,如何快速地恢复系统,迅速投入到服务备份中去是相当重要的,所以,对于文件系统数据的恢复而言,也需要专门的考虑和设计。
本方案被配置成多个站点互为备份的情况,即平时只有一个主站点在服务,其他站点处于同步备份状态,当某个站点出现故障或灾难时,或者是被非法入侵者攻破时,系统可以立即分配新的主站点把被破坏的站点替换下来,进入恢复状态,其他正常的站点仍可提供正常的服务。
当然,也存在所有站点均出现故障的情况,但是由于我们采用了多种措施,如动态随机迁移、灾情评估与响应策略等,再配合传统的防火墙、IDS 等安全系统,可以极大限度地减少这种几率。因此,我们的数据恢复问题主要考虑上述这种情形,即个别服务器出现故障退出服务而其他系统依然正常的情况。 |
|


