Linux 网络文件系统的数据备份及恢复机制实现(2)
|

- UID
- 1029342
- 性别
- 男
|

Linux 网络文件系统的数据备份及恢复机制实现(2)
首先,我们来分析一下系统退出后数据的情形,主要涉及到退出的服务器和正常的主服务器与备份服务器,如图 4 所示:
图 4 一个系统退出后数据状态示意图
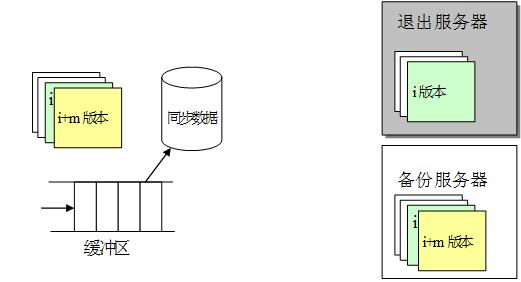
在上图中,退出服务器最后生成的版本号为 i,系统退出后,一方面主文件服务器会察觉到同步数据无法从退出服务器返回结果,这样的话它就会重发同步请求,经过 3 次重发后,如果依然没有返回信息,则认为该服务器退出服务,因此会把同步数据备份到磁盘文件中,并记录下该服务器在同步数据文件中的起始位置,这当由多个文件服务器退出时可以分别识别出来。由于退出系统无法继续保持同步,因此其状态会与工作的文件服务器不一致,具体表现在以下几个方面:
- 当退出时间很短时,数据不一致仅存在于缓冲区中,这时如果退出服务器能立即重新投入使用,则不需要进行额外的数据恢复,数据同步可以通过主服务器同步请求的重试来达到。当主服务器确认退出服务器退出后,会把未同步的数据写入特定的同步数据文件中,这时的不一致性包括了缓冲区中的数据和同步数据文件中的数据,这时的数据恢复需要做两方面的工作:
- 把同步数据文件中的正确数据一次性发送给退出服务器,退出服务器把它写入本地的同步数据文件;
- 建立本地的缓冲区,建立起同步机制,接收同步数据,同时启动数据同步进程,先同步数据文件中的数据,当缓冲区数据因没有处理而达到一定程度时,会自动把部分数据追加到同步数据文件的后面,这时,退出服务器已经恢复了正常工作,实际上也不需要过多的数据恢复工作。
由于主文件服务器一般需要处理文件的读写请求,写请求仅占一部分,需要同步而执行的操作造成的负载要小于主服务器,因此可能在较短的时间内完成同步。当需要退出服务器(此时已经进入同步阶段)成为主服务器时,则必须等所有同步数据同步完成后才能开始服务。
- 如果退出服务器是因为较严重的故障或灾难而退出的,则可能需要较长时间的处理,如更换硬件、系统重启、甚至重装系统等,这时就可能出现一些困难的情况,一种是如上图所示的,工作正常的系统已经生成了新的版本,如服务器退出时的最新版本是 i,经过一段时间后,正常系统生成了新的版本,这时主系统会清空同步数据文件,重新从版本生成后进行记录。对于这种情况,可以有两种处理办法:
- 基于本地版本的快速恢复:当退出文件服务器本地至少存在一个版本与其他正常机器上的版本相同时,可以采用这种恢复策略。具体而言,先确定一个最新的正确版本,用本地版本恢复,这一过程非常简单快捷,仅涉及到两次 inode 的修改;然后选择一台正常服务器,请求它生成一个正常系统上最新版本与恢复版本的增量升级数据,这样的数据量不会很大,而且不需要象基于操作的同步那样逐步进行,同步效率非常高,因此可以大大提高恢复速度。同步到正常系统的最新版本后,然后就按照上述第 2 条的情况进行同步数据文件的同步。
- 基于分布版本的快速恢复:当停顿时间太长而不存在一个相同的版本,或文件服务器数据出现损坏(如磁盘故障造成数据损毁)时,需要采用此种方法。具体办法如下:直接把正常服务器上的最新版本传送到退出服务器,然后按照上述的第 2 种情况进行同步数据文件的同步。
正如上面所述,全部服务器均出现问题的概率是很小的,但是,不能简单的排除这种情况的出现,特别是本方案采用数据同步机制,即多个站点的数据是保持快速同步的,这虽然能保证动态迁移的顺利完成,但是也带来较大的风险,就是会出现数据”污染”的自动传播,当主文件服务器中的文件数据因为某些原因(主要是对文件的非法访问)造成数据非法修改时,会立即传播到其他备份节点,这样的话,不管服务迁移到哪台机器均会出现错误。
针对这种情况,我们采取了以下措施:当发现非法修改造成数据污染时,系统可以自动命令各站点恢复到指定的版本,如前一版本(可以由管理员配置成前一、二、三个版本);管理员也可以干预这一过程,强制各站点恢复到同一指定的版本,从而保证全局文件系统使用同一正确版本。
NFS 文件细粒度恢复技术
在传统恢复技术中,一方面由于数据备份不是实时进行的,当出现事故需要恢复时,最新的备份数据与最新数据之间存在一个时间差,这样就造成了该时间段内数据的丢失(见图 5);同时,传统的数据备份是一定时间段后数据的增量备份,是一段时间内所有文件操作叠加后的结果,因而无法精确知道在这段时间内实际数据的变化过程,因而也无法从所有这些操作中定位非法操作,并进行选择性的恢复,以保证数据的正确性。
图 5 因非实时备份造成恢复时的数据丢失示意图
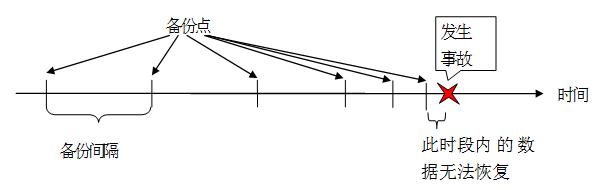
基于上述考虑,我们不但采用了增量方式的多版本备份恢复技术,同时还对文件的修改日志进行了实时的备份,这样就可以在事故发生后进行基于文件操作的精确恢复,并支持允许剔除非法操作的选择性恢复,这样既能尽量避免因事故造成的数据丢失问题,又能通过选择性恢复较好保证数据的正确性,同时,还可以通过对日志的分析,结合数据的精确恢复,达到发现犯罪线索、获得有效证据的目的,为打击网络犯罪提供有力的技术手段。在这里,精确性恢复指的是恢复某一时段的所有操作,一般是在某一版本后的所有操作,不由用户进行选择,而选择性恢复则指的是某一时间段内的所有操作构成的集合的子集,需要恢复的操作由用户通过查询、浏览等工具来进行选择。在我们的定义中,实际上可以认为精确恢复为选择性恢复的一个特例。
我们首先需要有相关的解决方法来记录下具体的操作信息,形成操作日志文件,从而作为分析的证据(参见图 6)。我们使用的策略是通过修改服务器操作系统内核调用 nfsd_write()、nfsd_create()……。从中取到调用处理对象的文件、目录的全路径名,写进文件,在内核中截获相应的文件操作请求。下面以 nfsd_rename()系统调用为例,进行扩充、修改而实现记录操作日志的功能。
int nfsd_rename(struct svc_rqst *rqstp, struct svc_fh *ffhp, char *fname, - int flen,struct svc_fh *tfhp, char *tname, int tlen) {
- struct dentry *fdentry, *tdentry, *odentry, *ndentry; struct inode *fdir, *tdir;
- int err; char *name;
- mem_segment_t oldfs; int fd;
- err = fh_verify(rqstp, ffhp, S_IFDIR, MAY_REMOVE); if (err)
- goto out; rqstp->rq_path1 = rqstp->rq_path2;
- err = fh_verify(rqstp, tfhp, S_IFDIR, MAY_CREATE); if (err)
- goto out; fdentry = ffhp->fh_dentry;
- fdir = fdentry->d_inode; tdentry = tfhp->fh_dentry;
- tdir = tdentry->d_inode; ……
- //加入的代码进行处理工作 if((!rqstp->rq_recover)&&(!S_ISDIR(odentry->d_inode->i_mode))
- &&(odentry->d_inode->i_nlink>1)){ rqstp->rq_copy->wait = 1;
- rqstp->rq_copy->done = 0; name = get_total_name(dentry,NULL);
- oldfs = get_fs(); set_fs(KERNEL_DS); //进入内核模式
- fd = sys_open("/backupserv/changfilename.c",0,31681); sys_write(fd,name,strlen(name));
- sys_close(fd); set_fs(oldfs); //从内核模式返回
- while(!rqstp->rq_copy->done){ schedule_timeout((HZ+99)/100);
- …… }
- }
[table][/table]
该文件是在 nfs 服务器端执行 nfs 客户机发送过来的修改文件或者是目录的原函数。在这里,我们可以通过添加自己的代码,来将创建的目录和文件名存入一个磁盘文件当中,以备后面的备份和恢复操作。
图 6 NFS 文件细粒度恢复日志产生示意图
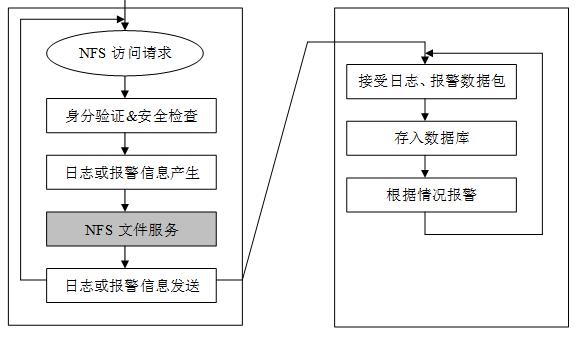
获得了操作日志信息,然后就可以进行精确恢复和选择性恢复时。首先由用户利用数据查询、浏览工具确定需要恢复的文件操作集,然后利用相应的日志数据按记录产生顺序逐条生成恢复请求,发送给文件服务器端的代理程序,由它通过 proc 文件请求 NFS 文件系统恢复模块进行恢复,恢复模块收到请求后,取出相关数据,然后通过调用底层 ext3 文件系统基本操作完成该次文件操作的”重放”,最后返回执行结果,通过 proc 文件通知代理程序,代理程序再通知管理端,管理端再发送下一条恢复请求,及到所有选中的操作全完成为止。具体实现模式请参看图 7: |
|
|
|
|
|


