插入操作
如果理解了上面的查找操作,插入操作其实也很好理解,我们首先要找到我们新插入结点的位置,其思想和查找操作一样。找到插入的位置后我们就将新结点插入二叉树。只是这里还要加一个步骤:更新结点的size,因为我们刚刚新插入了结点,该结点的父节点,父节点的父节点的size都要加一。
[url=]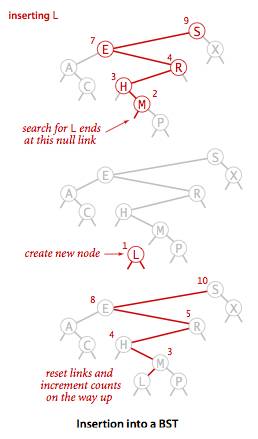 [/url] [/url]
二叉树插入流程图
插入操作的实现同样有多种实现方法,但是递归的实现应该是最为清晰的。下面的代码的思想和get基本类似,只是多了x.N = size(x.left) + size(x.right) + 1;这一步骤用来更新结点的size大小。
/**
* Inserts the specified key-value pair into the symbol table, overwriting the old
* value with the new value if the symbol table already contains the specified key.
* Deletes the specified key (and its associated value) from this symbol table
* if the specified value is null.
*
* @param key the key
* @param val the value
* @throws IllegalArgumentException if key is null
*/
public void put(Key key, Value val) {
if(key == null) {
throw new IllegalArgumentException("first argument to put() is null");
}
if(val == null) {
delete(key);
return;
}
root = put(root, key, val);
// assert check(); // Check integrity of BST data structure.
}
private Node put(Node x, Key key, Value val) {
if(x == null) {
return new Node(key, val, 1);
} else {
int cmp = key.compareTo(x.key);
if(cmp < 0) {
x.left = put(x.left, key, val)
} else if(cmp > 0) {
x.right = put(x.right, key, val);
} else {
x.val = val;
}
// reset links and increment counts on the way up
x.size = size(x.left) + size(x.right) + 1;
return x;
}
}
|




