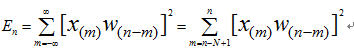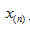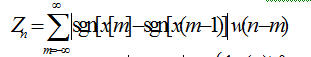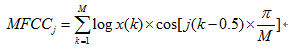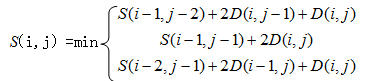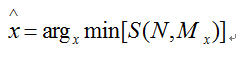设计摘要:
1、设计意图
科学技术水平的发展,使人们的生活受到潜移默化的影响,并逐渐改变人们的生活习惯,不断地提高人们的生活质量。比如由于全自动洗衣机、微波炉等智能化设备的出现,我们不必按键操控每一步过程,机器可以自动完成整个过程,用户也可以遥控他们。
智能化所带来的方便、快捷带给人们更加舒适的生活,但是随着家用电器的不断增多,需要的遥控器也不断增多,给人们造成许多的不便,因此,一种能够解放人们双手并且实时、快速、方便的语音智能操控系统的概念应运而生。语音智能操控系统可以取代多个遥控器,当需要控制某一家电时,只需说出所需调节的内容(如,空调开,温度25℃),语音智能操控系统就能通过对操控者的语音识别,完成匹配并发出遥控信息完成相应的操作。
基于FPGA实现语音智能操控系统具有:
(一)设计灵活、操作方便、快捷
(二)准确度高,工作范围大
(三)可随时用语音操控带有遥控装置的用电器
(四)可扩展性强,增强了系统的外接功能
(五)便于更新和系统升级,可随时嵌入更新系统程序
(六)设计周期短、开发费用低、功耗低等独特优点。
2、适用范围
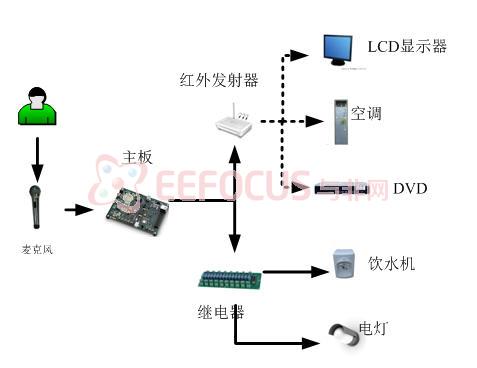
语音智能操控系统主要控制的家用电器有两类,第一类是开关型家电,包括家居照明、饮水机、电饭煲、抽风机、充电器、电风扇等;第二类是红外遥控型家电,包括空调、电视机、DVD、电动窗帘、电动闸门等。还有很多有待开发的应用领域,范围很广。
3、主板
该系统利用FPGA板块,可自主嵌入应用程序,用户可根据自己需求植入语音信息,以待匹配。如果用户不需要某项语音匹配信息,可删除,灵活性非常高。同时,由FPGA主板设计ASIC电路,具有设计周期短、开发费用低、功耗低的优点。系统控制核心都在FPGA内部实现,可以极为方便的更新和升级系统,大大的提高了系统的通用性和可提高性。
功能描述:
由FPGA实现语音智能操控系统的系统构架图如图2-1所示,它是以FPGA为主板,嵌入语音识别系统并结合红外遥控系统完成的智能操控系统。
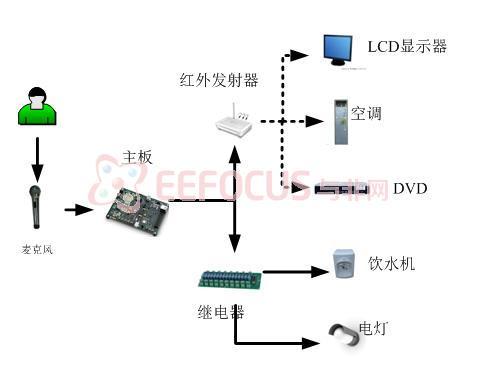
图2‑1 由FPGA实现语音智能操控系统的系统构架图
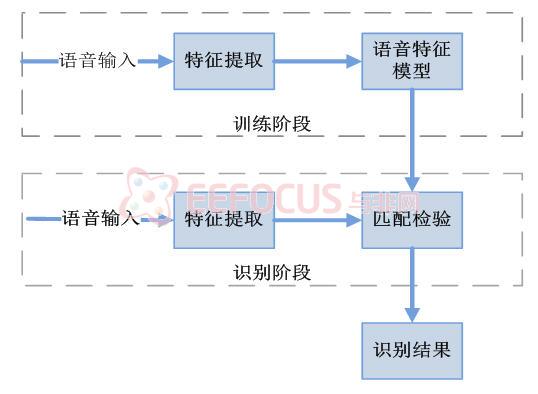
FPGA中嵌入的语音识别系统分为两种工作模式:训练模式和识别模式首先,用户在训练模式下,完成相应的语音信息的输入和特征存储工作,建立完整的语音信息特征数据库。然后,在识别模式下,由语音输入设备输入语音信息进行比对,匹配后即发出相应操作的信号,遥控设备。系统框图如图2-2所示
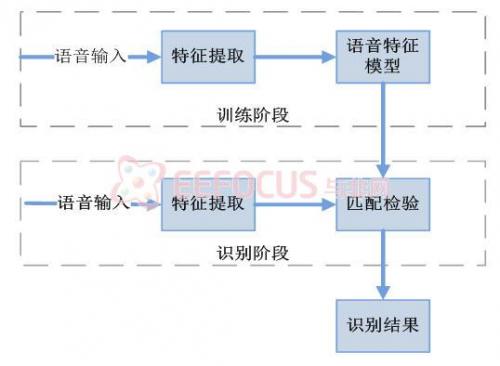
图2-2 语音识别系统的框图
该系统分为五个模块:语音信息特征提取模块、语音信息特征数据库建立模块、语音信息输入采集与预处理模块、语音信息比对模块、操控指令连接发送模块。
1、语音信息特征提取模块,即对接收到的语音信息通过语音识别算法提取相关特征匹配数据,其中用到语音信息输入采集模块。
2、语音信息特征数据库建立模块,即对特征提取模块所得匹配数据存储到存储器中,以备对比匹配使用。
3、语音信息输入采集模块,即通过麦克风输入语音信息,当满足要求时,通过信息特征提取模块对输入的语音信息的特征数据进行提取,保存到缓冲区,等待对比。
4、语音信息比对模块,即用保存到缓冲区的特征数据和数据库中的数据进行比对,是否与某一数据匹配。
5、操控指令连接发送模块,即当输入的语音信息与某一库存信息匹配时,就完成主板与红外发射装置的连接并发出相应的操作指令信息,完成操作。
整个过程由嵌入到FPGA芯片内的程序完成。另外,基于NiosII的SOPC系统帮助我们完成了上述功能。同时,我们通过开发工具SOPC Builder,在FPGA上创建软硬件开发的基础平台,可以很快的将硬件系统(包括处理器、存储器、外设接口和用户逻辑电路)与常规软件集成在单一可编程芯片中。而且,SOPC Builder 还提供了标准的接口方式以便我们将自己的外围电路做成Nios Ⅱ软核可以添加的外设模块。这种设计方式更加方便了我们对系统的调试。
设计方法:
本系统设计开发中主要使用的硬件工具和软件设备:
Spartan—6、音频编解码芯片、麦克风、ISE仿真软件。
以下分模块介绍所用算法:
5.1语音信息输入采集与预处理模块
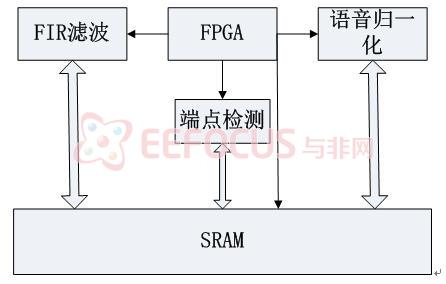
本模块要实现的功能是采集语音信号,并对其进行FIR滤波、语音数据归一化、语音的端点检测处理。语音采集部分采用外加的音频编解码器进行设计,通过VERILOG HDL编写对芯片的工作模式进行设置,是芯片在上电后对工作模式设置在系统要求的状态下。
语音预处理包含三部分,语音归一化处理单元、FIR滤波器运算单元、语音端点检测单元。图5-1.1是预处理的结构功能图:
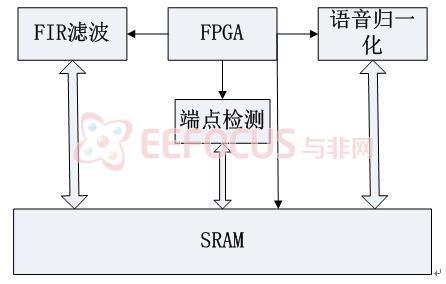
图5-1.1预处理的结构功能图
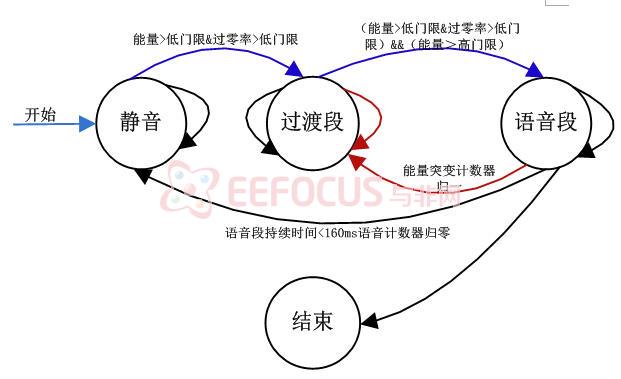
在分析处理之前必须进行端点检测过程,以确定语音信号的开始点和结束点。其中包括对语音信号短时能量和短时过零率的分析。
短时能量
其中,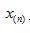 为原样本序列在窗函数所切取出的第n段短时语音,N为帧长。
为原样本序列在窗函数所切取出的第n段短时语音,N为帧长。
短时过零率
其中,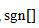 为符号函数。
为符号函数。
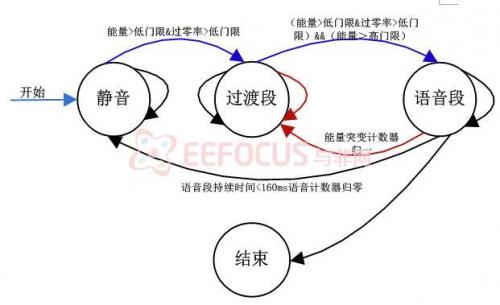
图5-1.2语音的端点检测状态图
5..2语音信息特征数据的提取模块
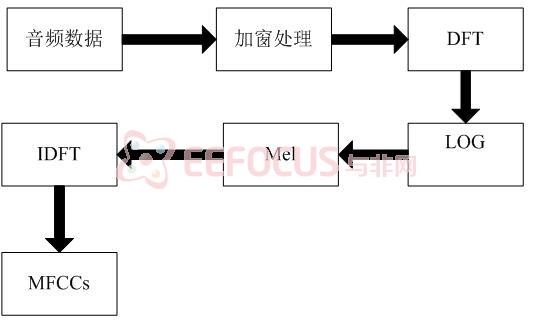
这里利用到MFCC音频特征提取算法,语音信号输入系统后,先进行加窗、滤波等预处理,再进行采样等过程,最终完成特征数据的提取。在识别模式下,语音信息的采集也是用到了这个算法,过程相同。
MFCC算法是有效的基于内容的音频特征提取算法,其处理过程如下:
(1) 对音频信号进行预处理,即预加重、分帧、加窗处理;
(2)将每帧音频信号进行傅里叶变换得到其频谱:
(3)用Mel滤波器组在频域进行带通滤波,并对每个频带的能量叠加得到频谱能量x(k);
(4)将滤波器组的能量取对数,然后做离散余弦变换,即得到MFCC特征。
图5-2为MFCC特征提取算法的流程图。
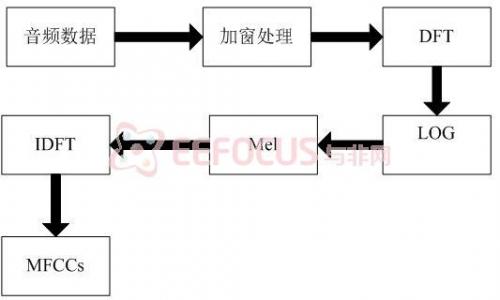
图5-2 MFCC特征提取算法的流程图
计算公式为: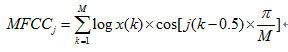
此时所提取的特征为音频信号的静态特征,该信号再经一阶差分后即得到音频的动态特征。
5.3 特征数据匹配模块
完成特征数据提取后,系统需要完成匹配的过程,这里用到了DTW算法,即在数据库里重复寻找与输入的音频特征差别最小的数据信息,完成匹配。
DTW算法是典型的DP人算法,它利用动态时间规整方法将模板特征序列和语音特征序列进行匹配,比较二者之间的失真,得出识别判决的依据。DTW算法的具体过程如下:
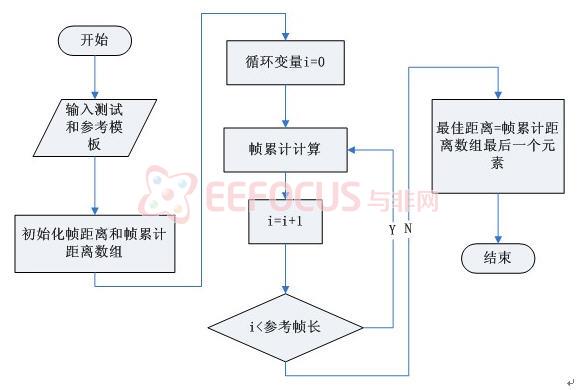
假设存储的一个词条模板包括M帧倒谱特征R={r(m);m=1,2,...,M};识别特征序列包括N帧倒谱特征T={t(n);n=1,2,...,N}。在r(i)和t(i)之间定义帧局部失真D(I,j),D(I,j)=|r(i)-t(i)|*2,通过动态搜索路径中找到的累积失真最小的路径,即最优的匹配结果。采用对称形式DTW:

其中S(i,j)是累积失真,D(i,j)是局部失真。
当动态规划过程计算到固定节点(N,M)时,可以计算出该模板动态匹配的归一化距离,识别结果即该归一化距离,最小的模板词条

计算过程中,为了减少计算量,我们采取以下方法:
全局路径约束,即只计算四条直线:y=0.5x,y=2x,y=0.5x+(M-0.5N)
,y=2x+(M-2N)所谓的平行四边形内部的点;
端点约束为固定起点、终点,即从左下角开始计算,到右上角点截止;
对进行模式匹配的两条语音命令的长度N和M进行了约束,如果两者之间相差太大则直接放弃该参数模板,不进行DTW运算。
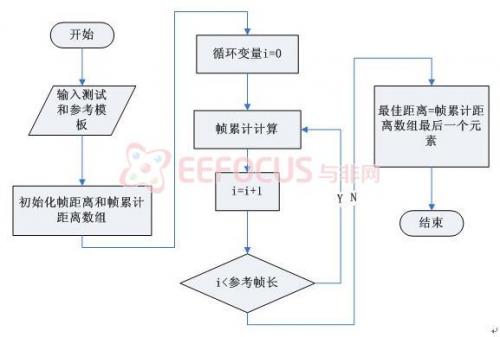
图5-3 DTW算法流程图
设计特点:
该设计的主要特点:
该设计采用MFCC音频特征提取算法和DTW特征匹配算法,对音频进行了加窗、滤波预处理,特征数据的提取和比对都比较精确,系统的稳定性和准确性都得到了提高。
系统采用Spartan-6主板,将程序编写后嵌入到芯片内部,外部只是采用简单的线,用于连接输入、输出设备,主板采用集成电路,减少了连线错误的可能性。同时,内嵌的程序可作修改,更具实用性,也节省了制作材料。
当系统出现错误时,可调出内部程序,在仿真软件上进行模拟查询错误;若问题出在外部电路,由于电路连线简单,用户便于查找和更改。相比于单纯的电路结构,该系统结构明了,无需大范围的改动,更加实用和节省材料。
系统采用红外模块操控家电设备,结构简单,控制方便。
红外操控本身就具有可遥控的特点,即芯片可固定于某一位置,连接多个红外发射端口,就可完成对多个设备的操控。