首页
|
新闻
|
新品
|
文库
|
方案
|
视频
|
下载
|
商城
|
开发板
|
数据中心
|
座谈新版
|
培训
|
工具
|
博客
|
论坛
|
百科
|
GEC
|
活动
|
主题月
|
电子展
注册
登录
论坛
博客
搜索
帮助
导航
默认风格
uchome
discuz6
GreenM
»
MCU 单片机技术
» 使用TI的Vision AccelerationPac,实现汽车可视探测
返回列表
回复
发帖
发新话题
发布投票
发布悬赏
发布辩论
发布活动
发布视频
发布商品
使用TI的Vision AccelerationPac,实现汽车可视探测
发短消息
加为好友
我是MT
当前离线
UID
1023166
帖子
6651
精华
0
积分
3328
阅读权限
90
来自
燕山大学
在线时间
230 小时
注册时间
2013-12-19
最后登录
2016-1-5
论坛元老
UID
1023166
性别
男
来自
燕山大学
1
#
打印
字体大小:
t
T
我是MT
发表于 2014-9-21 11:59
|
只看该作者
使用TI的Vision AccelerationPac,实现汽车可视探测
Vision
,
汽车
作者:
德州仪器
(
TI
) 战略营销经理Zhihong Lin、
嵌入式
视觉引擎首席架构师Jagadeesh Sankaran博士和技术战略主任Tom Flanagan
引言
到2013年9月,谷歌的自主驾驶汽车已在计算机控制下成功行驶了500000多英里,并且没有发生过一起交通事故[1]。谷歌具有革命性的无人驾驶汽车项目旨在利用摄像头、雷达
传感器
和激光测距仪(以及谷歌的地图数据库)监测和引导汽车行驶,从而提高汽车驾驶的安全性和效率。谷歌的无人驾驶汽车原型车使用了价值150,000美元的
机器人
组件,包括价值70,000美元的激光雷达系统,因此距离商用还有很长的路要走。2013年8月,尼桑汽车公司宣布计划于2020年前推出无人驾驶汽车,以实现零交通事故死亡率。自主驾驶汽车商用化进展的重点工作是,如何让自主驾驶汽车价格更低、可靠性和安全性更高。实现自主驾驶汽车的关键技术之一是计算机视觉,其使用基于摄像头的视觉分析,目的是提供高可靠、低成本的视觉解决方案。尽管基于摄像头的传感器成本低于其它技术,但其处理要求会急剧增加。今天的系统要求我们处理30帧每秒、1,280x800分辨率的图像,通常会同时要求运行5种以上的算法。德州仪器最新的应用处理器TDA2x基于OMAP5技术,拥有顶级的Vision AccelerationPac,可以高效率、低成本、可编程和灵活地实现高级驾驶辅助系统(ADAS),以支持自主驾驶汽车的20/20视觉功能。Vision AccelerationPac是一种可编程加速器,拥有专用硬件单元和定制过程,可使用高级语言实现完全编程。它允许视觉开发人员使用标准处理器架构所不具备的一些高级性能。使用高级语言实现的Vision AccelerationPac可编程支持,允许终端汽车制造厂商在算法调整方面进行探索,做出一些具有创新性的解决方案。当这些算法远未成熟时,这种功能特别重要,并且对于缩短产品上市时间也至关重要。
长眼睛的汽车
美国人口普查局的统计数据表明,在美国,平均每年发生600万起机动车交通事故。16-24岁年青人的交通事故死亡率最高。该统计数据还表明,大多数交通事故的原因均为人为操作失误。人们相信,给机动车加装视觉和智能装置可以减少人为操作失误,降低交通事故发生率,从而挽救生命。另外,人们还认为,汽车视觉系统可以帮助缓解交通拥堵,提高公路通行能力,提高汽车燃油效率,并提高驾驶者的行车舒适性。
高级驾驶辅助系统(ADAS)是朝着完全自主驾驶汽车的目标迈出的关键性一步。ADAS系统包括但不限于自适应巡航控制、车道保持辅助、盲点探测、车道偏离警告、碰撞警告系统、智能速度自适应、交通标志识别、行人保护与物体探测、自适应灯光控制和自动泊车辅助系统。
摄像头是一种低成本方法,涵盖许多交通应用环境,可用于智能分析。立体前置摄像头可用于自适应巡航控制,监控实时交通状况,帮助保持与前车的最佳距离。前置摄像头还可用于车道保持辅助,让汽车保持在车道中间,也可用于交通标志识别和物体探测。侧摄像头可用于并道监控、盲点探测和行人感知。
摄像头后台数据分析功能,让汽车拥有类似人类视觉的能力。实时视觉分析引擎需要对每一个视频摄像帧进行分析,提取正确的信息来做出智能决策。它不仅仅需要超强的计算能力,在瞬间对数据进行处理,以让快速运动的汽车做出正确的机动,还需要宽I/O来提供多个摄像头的视觉分析引擎输入,从而实现同步关联。低功耗、低延迟和可靠性也是汽车视觉系统的几个关键方面。
TI技术实现者—Vision AccelerationPac
TI的Vision AccelerationPac是一种可编程加速器,专门用于满足汽车、
机器视觉
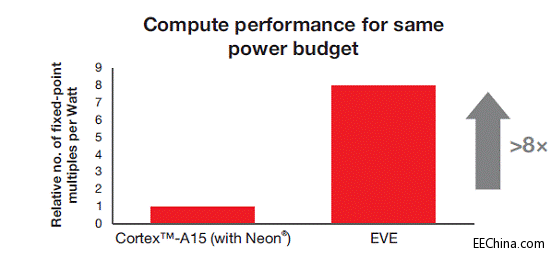
和机器人市场计算机视觉应用的处理、功耗、延迟和可靠性需要。Vision AccelerationPac包含一个或者多个嵌入式视觉引擎(EVE),用于实现嵌入式视觉系统的可编程性、灵活性、低延迟处理和功率效率以及小硅片面积,因此可实现性能与价格的优异结合。相同功率级别下,相比现有ADAS系统,每个EVE拥有8倍以上的高级视觉分析计算性能改善。详情,请参看图1。
图1
Cortex
-A15相同功率预算时计算性能为原来的8倍以上
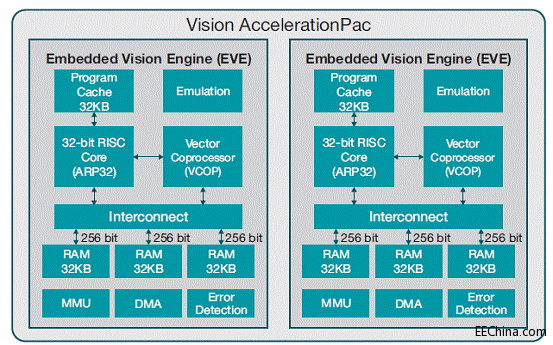
下一页中的图2显示了Vision AccelerationPac架构。
Vision AccelerationPac内有一个或者多个EVE,它是一种视觉优化处理引擎,包括一个32位自适应专用RISC处理器(ARP32)和一个512位矢量协处理器(VCOP),并使用内置机制和独特的视觉专用指令,用于同时、低开销处理。ARP32包括32KB的程序缓存,用于实现高效程序执行。它还拥有一个旨在简化调试的内置
仿真
模块,并与TI的Code Composer Studio™集成开发环境(IDE)兼容。共有3个并行平面内存接口,每个接口均有256比特加载与存储带宽,共提供768比特宽内存带宽(是大多数处理器内部内存带宽的6倍),并拥有共计96KB L1数据内存,可实现极低处理延迟的同步数据传送。每个EVE还具有一个本地专用直接内存访问(DMA),用于主处理器内存的数据进出传输,以实现快速数据传送,同时还有一个内存管理单元(MMU),用于地址翻译和内存保护。为了实现可靠运行,每个EVE还在所有数据内存上使用单比特误差检测,对程序内存使用双比特误差检测。一个关键的架构级功能是DMA引擎、控制引擎(RISC CPU)和处理引擎(VCOP)的完全并发。例如,它让ARP32 RISC CPU可以在处理一个中断命令或者执行顺序代码的同时,VCOP执行一个循环并在底层对另一条语句解码,并在没有任何架构或者内存子系统停止工作的情况下传送数据。另外,它还通过硬件邮箱方法,对处理器间通信提供嵌入式支持。大多数高功效视觉处理中,EVE仅使用400mW的最大总功耗,便实现了8GMAC处理性能和384Gbps数据带宽。
图2 Vision AccelerationPac架构
VCOP矢量协处理器是一种带嵌入式环路控制和地址生成的单指令多数据(SIMD)引擎。它提供每周期16个16位倍增器的双8路SIMD,以及500MHz频率持续数据流量下8GMACS每秒的速度,其由舍入和饱和相关加载/存储与内置的零循环开销维持。它可以三源运行,让两个矢量单元提高两倍,每个周期多计算32个32位。VCOP还具有8个地址生成单元,每个均拥有4维地址功能,能够存储4个嵌套循环和3个内存接口的地址,从而实现4级嵌套循环零开销。它大大减少了迭代像素操作所需的计算周期。矢量协处理器拥有许多专用通道,用于加速柱状图、加权直方图和查询表,并支持一般计算机视觉处理级,例如:梯度、方向、排序、位交错/去交错/置换、全景图像和局部二进制模式。另外,矢量协处理器还具有一些实现灵活性和并发加载存储运行的专用指令,旨在加速重要解码和分散/集合运行区,从而实现非邻近内存数据的高效处理。它最小化了传统图像处理程序所需的常见数据传输和拷贝,实现超快处理性能。同标准处理器架构相关的各种功能处理速度提高4到12倍是正常的。VCOP本身就支持分散/集合和重要处理区功能。排序是一种常见的计算机视觉功能,其发生在一些多用情况下,例如:追踪目标特性识别和密集光流搜索匹配等。EVE极大加快了自定义指令支持排序,从而使EVE能够在15.2μ秒内对2048个32位数据点进行排序。
利用标准TI代码生成工具套件可对Vision AccelerationPac进行完全编程,允许直接编译软件,并在PC上运行来模拟。通过TI的实时操作系统BIOS(RTOS),ARP32 RISC内核可以完全运行C/C++程序。通过TI的VCOP内核C构建的C/C++专用子集,对VCOP矢量协处理器编程。VCOP内核C是一种模板化的C++矢量库,其通过一种高级语言显示相关硬件的各种功能。利用一些标准编译器(例如:GNU GCC或者Microsoft® MSVC等),可以在一台标准的PC或者工作站上评估和验证写入VCOP内核C的算法。它允许开发人员在算法开发过程初期融入矢量化和验证位精确度,并对大量数据集进行测试,从而确保算法的稳健性。只需使用TI的代码生成工具对源代码进行重新编译,这些算法便可直接运行在Vision AccelerationPac上。写入VCOP内核C的程序有许多优点;它们经过优化后可使用Vision AccelerationPac架构和指令集,拥有特殊的循环结构,可对矢量数据进行操作,并且在C声明和汇编语言之间有一个几乎是一对一的映射,从而得到非常高效的代码,代码体积和内存占用较小。
共有超过100个Vision AccelerationPac编程举例。相比VCOP内核C,使用
ARM
® NEON® SIMD的阵列添加简单例子表明,在6个周期中,ARM可以增加4个32位值,从而获得1.5周期每输出的内循环性能,同时,VCOP充分使用其768位加载存储带宽,在一个周期内获得8个输出。该结果相当于1/8周期每输出的吞吐量,其实现了12倍于ARM的总体周期到周期速度。
Vision AccelerationPac内部EVE的ARP32 RISC内核针对控制代码和顺序处理进行了优化。它支持运行SYS/BIOS、TI的实时操作系统,因此提供了对线程、信号和其它RTOS特性的支持。
EVE受到全套代码生成工具的支持,包括TI的Code Composer Studio IDE中集成的优化编译器即模拟器。EVE通过硬件计数器对非侵入式性能监控提供嵌入式支持。它允许用户对多个性能信号进行监控,与此同时,在无需进行任何代码修改的情况下,应用程序运行并允许深度监控应用程序的运行时间表现。
使用Vision AccelerationPac的圆形交通标志识别举例
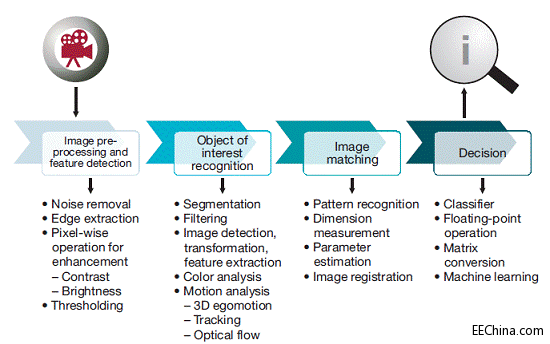
典型的视觉分析处理涉及几个阶段(如图3所示),包括图像预处理与特性检测、相关物体识别、图像与模式匹配,最后才是决策判断。TI的Vision AccelerationPac最适合于减轻视觉分析处理前三个阶段的密集计算。决策判断通常包括分类器、浮点运算和矩阵转换,C66x
DSP
内核对它们的处理最为有效。正因如此,Vision AccelerationPac在
SoC
中与一个或者多个DSP配对使用。结果是,把视觉分析工作量合理是划分开来。
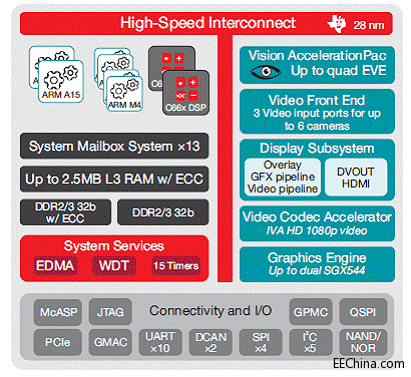
TI的TDA2x可实现低功耗、高性能的视觉处理系统。它拥有两颗C66x DSP内核和一个Vision AccelerationPac,以及两个嵌入式视觉引擎(EVE)。另外,它还包括一个视频前端和汽车汽车联网接口。下一页的图4显示了TDA2xx SoC结构图。
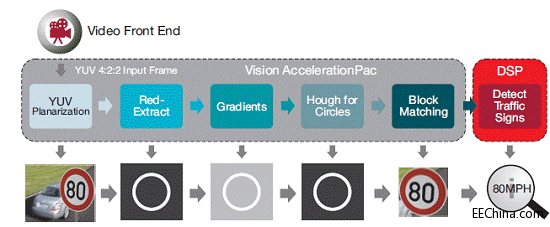
下面,我们来探讨Vision AccelerationPac如何能够加速ADAS圆形交通标志识别。
一些世界圆形交通标志使用红色圆圈作为分界线,因此第一步便是从YUV422输入数据只提取红色像素。第二步是,计算水平和垂直梯度,使用亮度和对比度来确证红色边界线。然后,使用霍夫变换算法找出圆形。现在,使用数据库中存储的模式使圆形内被识别相关区域图像关联起来,以解释交通标志(80 MPH),最终做出决策判断。在这种情况下,结论是限速80英里/小时。
图3视觉分析处理流程图
如下面图5所示,Vision AccelerationPac可以高效地分担圆形交通标志识别处理的大多数工作量,包括基于互关联的块匹配模板加速器。DSP内核用于提高最终决策的稳健性。使用霍夫变换算法来查找圆形是一项高计算密集型工作,但使用Vision AccelerationPac时,霍夫变换算法查找圆形仅需140字节个代码空间,约(1.88*NUM_R
ADI
US) +1.81 cyc/pix个处理时间周期,其中,NUM_RADIUS为我们在霍夫空间内选择搜索的半径数,因此它的视觉识别时间非常短,功耗非常低,并且硅片面积的性价比很高。以每秒30帧对一幅720 × 480图像进行完全交通标志识别约需50 MHz,即小于10% EVE周期。保持了丰富的处理功能,表明一个EVE可以同时运行多个视觉算法。
图4 TDA2x结构图
图5 使用Vision AccelerationPac实现圆形交通标志识别
机器视觉Vision AccelerationPac—汽车或者摄像头处理以外的应用
Vision AccelerationPac可以使用的其它领域还有很多。除视频摄像头分析处理以外,Vision AccelerationPac的固点倍增器和硬件通道是雷达分析处理的理想选择,因为它可以高效地处理快速傅里叶变换(FFT)和波束形成算法。利用Vision AccelerationPac来处理1024点FFT所花费的时间小于3.5μ秒。因此,雷达可用作汽车摄像头系统的补充,以探测许多不同的交通和气象状况。
汽车视觉所使用的相同机制,也适用于许多其它机器视觉行业;工业
自动化
、视频安全监控和警告系统、交通监控和车牌识别便是例子。Vision AccelerationPac可用于扩展DSP应用,以一种更加自主和高功效的方式来解决今天的许多视觉分析问题。
结论
Vision AccelerationPac是德州仪器创新型视觉分析解决方案。利用一种针对高效嵌入式视觉处理进行高度优化的灵活SIMD架构,Vision AccelerationPac拥有非常低的功耗和优异的硅片面积效率。Vision AccelerationPac与C66x DSP内核结合使用,可实现浮点和矩阵计算,从而极大地加速完整嵌入式视觉应用处理链。除是一种高效、可靠的架构以外,Vision AccelerationPac还使用一种简单的基于C/C++的编程模型,输出非常紧凑的代码。它意味着,Vision AccelerationPac实现的系统具有非常低的内存占用,从而进一步降低了视觉系统成本和功耗。TDA2x SoC及其Vision AccelerationPac,是实现智能汽车系统、工业机器和“可视”机器人视觉分析的一个理想平台,它们共同提高了我们的生活品质。
TDAx SoC更多详情,请访问
www.ti.com/TDA2x
。
参考文献
(1) 谷歌在Va. Tech测试无人驾驶汽车
(2) 尼桑宣布史无前例的无人驾驶汽车发展计划
鸣谢
感谢Stephanie Pearson、Debbie Greenstreet、Gaurav Agarwal、Frank Forster、Brooke Williams、 Dennis Rauschmayer、Jason Jones、Andre Schnarrenberger、Peter Labaziewicz、Dipan Mandal、 Roman Staszewski和Curt Moore给本文提供的支持。
收藏
分享
评分
回复
引用
订阅
TOP
返回列表
电商论坛
Pine A64
资料下载
方案分享
FAQ
行业应用
消费电子
便携式设备
医疗电子
汽车电子
工业控制
热门技术
智能可穿戴
3D打印
智能家居
综合设计
示波器技术
存储器
电子制造
计算机和外设
软件开发
分立器件
传感器技术
无源元件
资料共享
PCB综合技术
综合技术交流
EDA
MCU 单片机技术
ST MCU
Freescale MCU
NXP MCU
新唐 MCU
MIPS
X86
ARM
PowerPC
DSP技术
嵌入式技术
FPGA/CPLD可编程逻辑
模拟电路
数字电路
富士通半导体FRAM 铁电存储器“免费样片”使用心得
电源与功率管理
LED技术
测试测量
通信技术
3G
无线技术
微波在线
综合交流区
职场驿站
活动专区
在线座谈交流区
紧缺人才培训课程交流区
意见和建议