|
 
- UID
- 1023230
|

1 引言
IVR系统(Interactive Voice Response),即交互式语音应答系统,它被应用于呼叫中心(Call Center),以提高呼叫服务的质量、减轻服务员的工作强度并节省费用,是呼叫中心实现人机交互的重要门户,在传统的IVR系统中,用户与系统交互的方式是通过电话的键盘。通常,用户在进入IVR系统后,会听到相关的语音提示选单,根据自己的需要可以按下键盘上相关的按键。系统通过DTMF信号传送用户按下的键,同时也将用户的请求传送给系统,从而触发相关的语音信息。然而,传统的电话仅能通过DTMF信号,传送有限的几个数字及符号按键。这使得用户与系统的交互界面受到很大的限制,同时也就使得IVR系统的信息查询范围变得相当狭窄,用户在实际使用时会感到诸多不便。
随着计算机技术和人工智能总体技术的发展,自然语言理解不断取得进展。语音识别系统已成为一个越来越广泛的应用方向。由于电话网络的普及性,自然语言处理系统在电话信道上的应用已成为最重要的应用之一。而且随着移动通信技术的发展和人们对于信息获取的移动性的需求不断增加,市场对于电话语音识别系统的需求也不断的增加。因此在新一代呼叫中心的IVR系统中引入了语音识别技术作为用户的输入手段,用户可以直接用语音与系统进行交互,这样大大提高了工作效率。
2 系统流程及主要模块
本系统目标是支持多用户并发查询车辆违章信息和驾驶证信息。用户使用自然的语言说出需查询信息的类别和车牌号码,系统识别后将识别结果反馈给用户,经用户确认后,系统把识别结果作为后台数据库查询的关键字进行查询,并将查询结果播放给用户。其流程见图1。本系统主要包括以下几个模块:
话路处理模块:以并发的方式控制和管理各电话话路。
语音识别模块:负责查询类别和车牌号码的识别。
后台数据库查询模块:将语音识别的结果作为数据库查询的关键字进行查询。
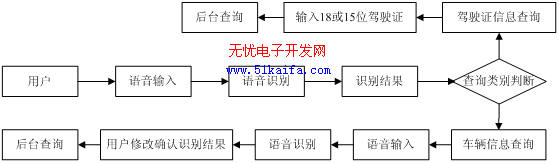
图1 车辆违章信息和驾驶证信息查询系统流程图
3 话路处理模块的实现
本系统的硬件部分是由电话语音卡和一台PC机组成,语音卡通过其提供的语音处理和信令处理能力,来实现用户的接入请求和挂机信号的检测,并负责录音和回放语音。本系统采用的是东进D161A语音卡。该语音卡可接入16条模拟电话线,提供16路以内的话路并行处理能力。其主要功能有:(1)自动增益控制及语音信号的压扩变换;(2)采集和播放各种格式的电话语音信号,实现A律PCM、μ律PCM、ADPCM等算法;(3)辨识和产生DTMF信号;(4)ITU-TSS G3传真功能。
话路处理的主要任务是电话振铃检测,播放系统提示语音信息,接受用户的按键请求和语音请求,与后台数据库模块通讯,检索结果的语音合成和播放。整个模块有点类似于一个有限状态机,在程序设计时要跟踪系统所处的状态进行相应的动作,并进入下一个状态,其程序流程如图2所示。
本系统话路处理模块的关键部分是语音数据的实时采集。东进语音卡在这方面提供了一系列接口函数,如:StartRecordFile、StartRecordFileNew、VR_StartRecord等。这几个函数都能够实现对通道的录音,所不同的是前两个函数将语音数据保存到磁盘文件,后一个函数则将语音数据保存到存储器缓冲区。由于我们要实现的是一个实时语音识别系统,因此我们采用后者来采集语音数据。在开始录音之前,我们首先调用VR_SetEcrMode函数启动回声抑制功能,然后每隔一段时间调用一次VR_GetRecordData函数取得录音数据,并将其送入语音识别引擎。当语音识别引擎有识别结果返回时,停止录音,并根据识别结果转入下一个状态。

图2 话路处理流程
4 语音识别模块的实现
语音识别系统的开发可以采用基于模板匹配的动态时间规整(DTW)、基于统计参数模型的隐马尔可夫模型(HMM),神经网络等技术,他们都是针对某些具体应用的,其模型参数的获得需要对大规模的样本进行学习,对于非特定人语音识别往往需要采集数百人的语音样本,其工作量是相当大的。随着语音研究的不断发展,已经出现了众多的语音识别开发工具:如Microsoft Speech SDK,IBM ViaVoice等。他们都提供了语音识别和语音合成的二次开发平台,并且微软的Speech SDK是完全免费的,它具有识别率高,识别速度快,可移植性好,支持多种语言等优点。因此它被广泛应用于各个领域。
4.1 Microsoft Speech SDK 5.1简介
SAPI SDK是微软公司免费提供的语音应用开发工具包,这个SDK中包含了语音应用设计接口(SAPI)、微软的连续语音识别引擎(MCSR)以及微软的语音合成(TTS)引擎等等。目前的5.1版本一共可以支持3种语言的识别 (英语,汉语和日语)以及2种语言的合成(英语和汉语)。SAPI中还包括对于低层控制和高度适应性的直接语音管理、训练向导、事件、语法编译、资源、语音识别(SR)管理以及TTS管理等强大的设计接口。
语音识别的功能主要由一系列COM接口协调完成。其中主要的接口有下面这些:
IspRecognizer接口:用于创建语音识别引擎的实例,识别引擎有两种:独占引擎(InProcRecognizer)和共享引擎(SharedRecognizer)。独占的引擎对象是在本程序的进程中创建,只能由本应用程序使用,而共享的引擎是在一个单独的进程中创建,可以供多个应用程序共同使用。
IspRecoContext接口:主要用于接受和发送与语音识别消息相关的事件消息,装载和卸载识别语法资源
IspRecoGrammar接口:通过这个接口,应用程序可以载入并激活语法规则,而语法规则里定义了待识别的单词、短语和句子。通常语法规则有两种:听写语法(DictationGrammer)和命令控制语法(CommandandControlGrammer)。听写语法用于连续语音识别,可以识别出引擎词典中大量的词汇;命令控制语法用于识别用户自定义的词汇。
IspPhrase接口:通过这个接口,应用程序可以获得识别信息,如:如识别结果、识别的规则、语义标示和属性信息等。
IspAudioPlug接口:通过这个接口,应用程序可以将内存中的语音数据送到语音识别引擎,进行识别。
4.2 识别模块的具体实现
由于命令控制语法方式可以限制识别的词汇量,并且这种识别技术不需要对说话人事先进行训练,因此在实际应用中具有较高的鲁棒性和较高的识别效率。本系统的识别词汇包括:“车辆信息查询”、“驾驶证信息查询”和26个英文字母10个数字,我们首先编写了包含这些特定词汇的语法文件。
在使用接口函数前,首先调用CoInitialize(NULL)初始化COM对象,然后创建语音识别引擎、语法规则上下文和识别语法,并调用函数LoadCmdFromFile装载文法识别规则。微软识别引擎是通过SAPI由事件触发来通知上层的应用程序。可以调用SetInterest来注册自己感兴趣的事件。系统默认的事件为SPEI_RECOGNITION,该事件表明当前已有识别结果返回,这时上层应用程序可以通过调用ISpRecoResult接口的GetText方法获得识别结果。
微软识别引擎的语音输入有多种方式,通常都是通过声卡直接输入,也可以通过其他语音输入流。本系统的语音数据是从语音卡取得的实时数据,将其存入内存,然后通过调用ISpAudioPlug的SetData方法将其送入识别引擎。
4.3 系统实现的难点和解决方案
车牌的识别词汇中包含10个数字和26个英文字母,这些词汇的发音有许多是相同或相近的,比如:E和1,R和2,T和7,D和B,M和N,X和S。这些词汇在识别时很容易产生误识,有的甚至完全不能识别。如果单从算法上来考虑,是很难解决这些问题的。因此我们考虑从系统的流程出发,当用户认为识别有误时,可以输入识别错误的位数,然后系统根据用户的输入,提供几个备选结果,供用户选择,这样极大的提高了系统识别率。
然而Microsoft Speech SDK 5.1在命令控制语法方式下是不提供多选的,只有在听写方式下才提供多选,但是听写方式下的词汇量又无法限制。对此我们的想法是这样的:当系统识别出结果以后,将有效语音段保存起来,并且把识别结果从命令控制方式下的词汇量中移除,然后将保存有效语音段再次送入识别引擎,当系统识别出结果以后,再次重复以上步骤,直到识别出给定个数的结果。
5 操作方法
用户用清晰、自然的语调说出需查询信息的类别,如:车辆信息查询、驾驶证信息查询,系统识别模块识别出结果后,转入相应的信息查询模块。当用户需要查询车辆信息时,首先要求用清晰、较缓慢的语调说出车牌号,系统识别模块识别出结果后,通过TTS将结果播放给用户。这时用户可以输入车牌号码中识别错误的位数,系统根据用户的输入提供7个备选结果让用户进行选择。用户选择确认无误后,系统将结果递交给后台数据库进行查询,并将检索到的信息播放给用户。
6 试验结果及分析
对于信息类别的识别由于其词汇量少,音节较多,所以识别率很高,达到了100%。但是对于字母和数字的组合识别,由于其词汇量较多,音节简单,而且有大量相同和相近的词汇,很容易受到噪声的干扰,所以识别率不是很理想。然而,当我们提供七个备选结果后,即使在有一定噪音的环境下,系统的识别率达也能达到96%以上。由此表明该系统是稳定的和实用的。 |
|


