浅析人脸检测之Haar分类器方法:Haar特征、积分图、 AdaBoost 、级联(3)
|

- UID
- 1029342
- 性别
- 男
|

浅析人脸检测之Haar分类器方法:Haar特征、积分图、 AdaBoost 、级联(3)
2.3、强分类器的强强联手
至今为止我们好像一直在讲分类器的训练,实际上Haar分类器是有两个体系的,训练的体系,和检测的体系。训练的部分大致都提到了,还剩下最后一部分就是对筛选式级联分类器的训练。我们看到了通过AdaBoost算法辛苦的训练出了强分类器,然而在现实的人脸检测中,只靠一个强分类器还是难以保证检测的正确率,这个时候,需要一个豪华的阵容,训练出多个强分类器将它们强强联手,最终形成正确率很高的级联分类器这就是我们最终的目标Haar分类器。
那么训练级联分类器的目的就是为了检测的时候,更加准确,这涉及到Haar分类器的另一个体系,检测体系,检测体系是以现实中的一幅大图片作为输入,然后对图片中进行多区域,多尺度的检测,所谓多区域,是要对图片划分多块,对每个块进行检测,由于训练的时候用的照片一般都是20*20左右的小图片,所以对于大的人脸,还需要进行多尺度的检测,多尺度检测机制一般有两种策略,一种是不改变搜索窗口的大小,而不断缩放图片,这种方法显然需要对每个缩放后的图片进行区域特征值的运算,效率不高,而另一种方法,是不断初始化搜索窗口size为训练时的图片大小,不断扩大搜索窗口,进行搜索,解决了第一种方法的弱势。在区域放大的过程中会出现同一个人脸被多次检测,这需要进行区域的合并,这里不作探讨。
无论哪一种搜索方法,都会为输入图片输出大量的子窗口图像,这些子窗口图像经过筛选式级联分类器会不断地被每一个节点筛选,抛弃或通过。
它的结构如图所示。
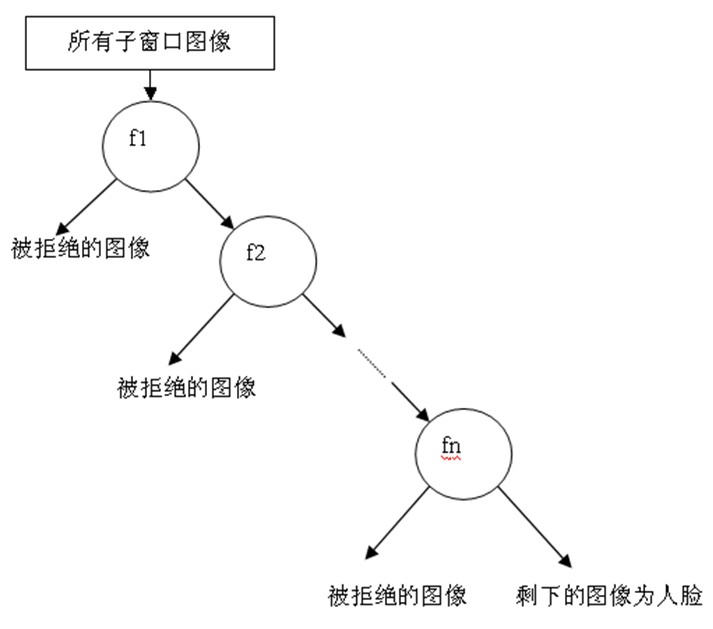
我想你一定觉得很熟悉,这个结构不是很像一个简单的决策树么。
在代码中,它的结构如下:
/* internal tree cascade classifier node */
typedef struct CvTreeCascadeNode
{
CvStageHaarClassifier* stage;
struct CvTreeCascadeNode* next;
struct CvTreeCascadeNode* child;
struct CvTreeCascadeNode* parent;
struct CvTreeCascadeNode* next_same_level;
struct CvTreeCascadeNode* child_eval;
int idx;
int leaf;
} CvTreeCascadeNode;
/* internal tree cascade classifier */
typedef struct CvTreeCascadeClassifier
{
CV_INT_HAAR_CLASSIFIER_FIELDS()
CvTreeCascadeNode* root; /* root of the tree */
CvTreeCascadeNode* root_eval; /* root node for the filtering */
int next_idx;
} CvTreeCascadeClassifier; |
|
|
|
|
|


