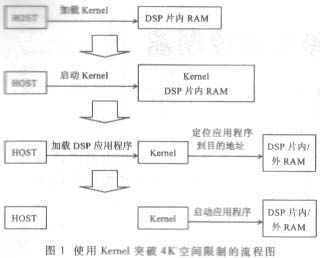
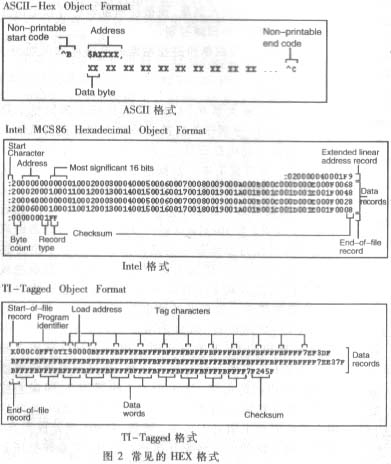
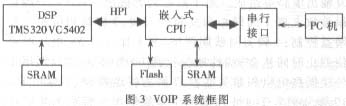
����HPI��ʽ�Ծ���TMS320VC5402 DSPоƬ��ʵ��
|
ƻ��Ҳ��� ��ǰ����


��̳Ԫ��
|

|
|
|
ƻ��Ҳ��� ��ǰ����
��̳Ԫ��
|
|
|
�е��� ( ��ICP��17063136��-2)|��ϵ���� |��̳ͳ��|Archiver|WAP|
GMT+8, 2025-6-12 18:00, Processed in 0.055233 second(s), 5 queries, Gzip enabled.
Powered by Eccn! 7.0.0
© 2001-2014 ChinaECnet Inc.