首页
|
新闻
|
新品
|
文库
|
方案
|
视频
|
下载
|
商城
|
开发板
|
数据中心
|
座谈新版
|
培训
|
工具
|
博客
|
论坛
|
百科
|
GEC
|
活动
|
主题月
|
电子展
注册
登录
论坛
博客
搜索
帮助
导航
默认风格
uchome
discuz6
GreenM
»
DSP技术
» 利用多目标建模技术降低ECU软件成本
返回列表
回复
发帖
发新话题
发布投票
发布悬赏
发布辩论
发布活动
发布视频
发布商品
利用多目标建模技术降低ECU软件成本
发短消息
加为好友
苹果也疯狂
当前离线
UID
852722
帖子
10369
精华
0
积分
5185
阅读权限
90
在线时间
277 小时
注册时间
2011-8-30
最后登录
2016-7-18
论坛元老
UID
852722
1
#
打印
字体大小:
t
T
苹果也疯狂
发表于 2015-7-30 18:23
|
只看该作者
利用多目标建模技术降低ECU软件成本
控制系统
,
软件开发
,
微处理器
,
控制器
,
嵌入式
多目标建模是一种电子控制单元(ECU)开发技术,它采用了基于模型的设计方法和自动嵌入式代码生成技术。
利用多目标建模技术可以为各种嵌入式DSP、微处理器和微控制器建立算术模型,并实现代码的自动生成。软件开发人员也因此可以节省许多时间和精力,因为他们不再需要为每个嵌入式目标器件编写、测试和重编代码。
在这方面,Visteon公司正在使用多目标建模技术开发动力控制系统。他们的方法以数据字典的创建为基础,而数据字典用来控制模型仿真和嵌入式代码生成时使用的数据类型。利用这种方法可以仿真设计思路,并根据各种嵌入式处理器选项试验各种处理器的算法功能。仿真环境有助于设计师在软件实现前就确定数据分辨率和量化对系统性能的影响。一旦选好了合适的嵌入式处理器,代码就能自动生成和创建,并被集成进产品ECU。仿真和代码生成环境由MathWorks公司的Simulink及Real-Time Workshop Embedded Coder提供。本文将介绍使用多目标建模方法开发动力ECU的技术、工具以及因此带来的好处。
人工的多目标实现方法
支持各种硬件架构的传统方法是人工开发代码。这些代码接口方便,并且很容易从一种架构改成另一种架构。这种方法的挑战是,工程师很难将他们的浮点算法转换成定点设计。转换过程要求提供各种变量和参数的换算系数和其它定点信息。另外,也很难创建和维持这样一种软件层,它能以一种易用的方式提供高层算法和定点软件实现之间的足够的抽象(abstraction)。
从浮点到定点架构的软件设计和接口会给开发过程带来其它问题,包括:
1. 建立换算信息要花很长时间;
2. 测试定点上溢和下溢是一件很繁琐的工作。每次数学运算都要求用最小和最大值进行分析和测试,才能满足上溢和下溢检查的需求;
3. 人工设计和编码技术很容易出错。
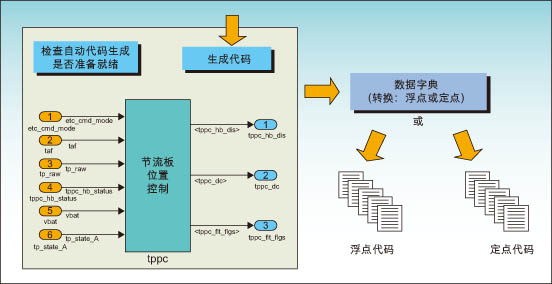
图1:Visteon公司动力系统的多目标建模架构
基于模型的多目标实现方法
在20世纪90年代,Visteon公司开始研究模型和自动代码生成在动力传动系统中的应用。调查结果使Visteon公司决定从人工开发方法转向模型设计方法。这种方法的转换在过去六年中一直在进行,因为已有的手工编码生产模块需要根据要求逐步转换成Simulink模型。在这段时间内也引入了Real-Time Workshop Embedded Coder的自动代码生成功能。该功能已在产品ECU实现中用来从模型中自动产生代码。
目前模型设计方法已在汽车产业中得到广泛使用,使用建模、仿真和自动代码生成的好处也已众所周知。Visteon公司建立了完整的建模环境,可以帮助设计师使用多目标、自动代码生成方法快速部署不同的硬件架构。该方法需要利用外部数据字典来约束从模型架构生成的代码的格式和结构。
模型设计环境
多目标模型与数据类型无关。最初模型使用的数据类型是主机执行仿真时可用的最大字长度(例如双精度实数)。这样就提供了被建议算法的理想行为。如果行为能令人满意,就可以再增加特定的目标实现,使模型适合产品ECU的要求。
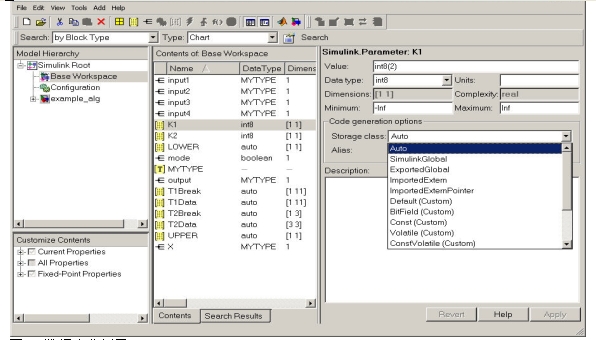
图2:数据字典例子。
为了使模型符合特定目标要求,需要将数据字典和特定硬件信息装载进MATLAB工作区。同时提供数据字典和基准通用模型的链接机制。自动化换算工具可以使转换和验证过程更加便利。自动化代码生成就是将定点设计翻译成产品代码的过程。接着Visteon公司工程师将软硬件组件集成进最终的产品ECU中,以便今后进一步的验证和确认操作。
图1给出了Visteon公司动力系统使用的通用模型架构,并说明了如何使用多个数据字典实现特定目标细节。
一旦行为令人满意,通用模型就被纳入Visteon公司的配置管理系统中,并作为动力算法库中的一个组件放置在知识架上。工程师可以随时通过复用存储在算法库中的模型组件创建新的算法。
模型设计工具
Simulink公司通过使用信号和参数数据对象支持面向数据字典的数据规范。可以利用加载进MATLAB工作区的外部数据字典确定数据对象。一旦开始仿真或代码生成,Simulink或Real-Time Workshop Embedded Coder就开始检查模型中已被命名的信号或参数在工作区中是否有对应的数据对象。如果工作区中存在对象,就可以在仿真和代码生成过程中使用数据对象的属性。
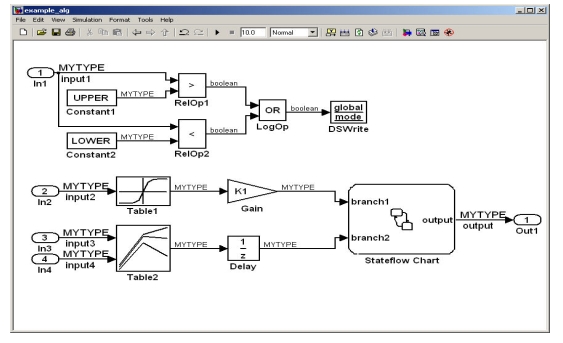
图3:通用模型例子。
图2就是具有数据对象的工作区例子。可以赋于数据对象的数据属性包括了初始值、数据类型、存储类、描述、最小和最大值等。除此之外,还可以赋于定点属性,如字长度、小数长度或二进制小数点、有符号或无符号等等。使用数据对象进行仿真和代码生成的通用模型如图3所示。这些例子描述的技术并不代表Visteon公司专有的产品数据或模型。
在建立通用模型后,Visteon公司的软件工程师就要为他们需要的目标架构创建并换成特定的数据字典,然后使用这个数据字典进行仿真和代码生成。然而,创建一个优秀的定点数据字典需要花很长的时间,这是因为在确定换算系数时需要做多方面的折衷考虑。工程师需要选择能够提供足够精度但在已知范围内的换算系数。如果换算系数的选择不够充分,那么当结果超过字长时可能发生数字上溢或下溢。
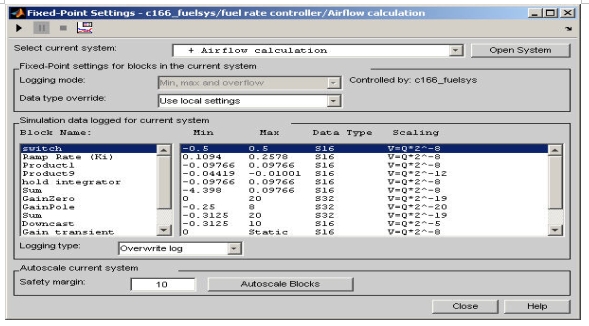
在选择换算系数时自动换算工具被证明是非常有用的。这些工具能够非常容易地确定仿真期间是否会发生上溢或下溢。图4是来自Simulink定点用户接口工具的输出例子。在这个例子中,数据记录显示了仿真过程中信号获得的最小和最大值。在这种情况下,所有信号都在范围之内。如果发生上溢或饱和,数据记录会标志这一事件,从而促使设计工程师调查问题原因,并选择新的正确的换算系数。
如果需要额外的保护,设计师可以使用由Simulink在模块参数对话框中提供的饱和设置在计算中增加上溢保护。饱和检查对生成代码的效率来说非常重要,下面的结论部分将提到这一点。
产品ECU程序的结果
Visteon动力系统实现了用于发动机管理系统的产品化浮点和定点的应用。对开发过程来说最大的好处是显著减少了时间和成本。在有个案例中,Visteon公司在三个月内就完成了ECU软件的开发,如果采用手工编码方案的话起码要6个月。
图4:自动换算工具和记录结果例子
收藏
分享
评分
回复
引用
订阅
TOP
返回列表
电商论坛
Pine A64
资料下载
方案分享
FAQ
行业应用
消费电子
便携式设备
医疗电子
汽车电子
工业控制
热门技术
智能可穿戴
3D打印
智能家居
综合设计
示波器技术
存储器
电子制造
计算机和外设
软件开发
分立器件
传感器技术
无源元件
资料共享
PCB综合技术
综合技术交流
EDA
MCU 单片机技术
ST MCU
Freescale MCU
NXP MCU
新唐 MCU
MIPS
X86
ARM
PowerPC
DSP技术
嵌入式技术
FPGA/CPLD可编程逻辑
模拟电路
数字电路
富士通半导体FRAM 铁电存储器“免费样片”使用心得
电源与功率管理
LED技术
测试测量
通信技术
3G
无线技术
微波在线
综合交流区
职场驿站
活动专区
在线座谈交流区
紧缺人才培训课程交流区
意见和建议