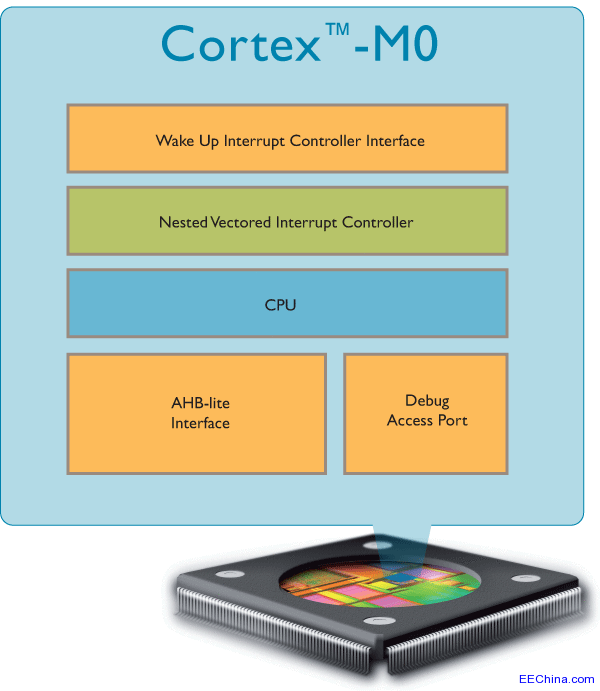
MOV A, XL;2 字节
MOV B, YL;3 字节
MUL AB;1 字节
MOV R0, A;1 字节
MOV R1, B;3 字节
MOV A, XL;2 字节
MOV B, YH;3 字节
MUL AB;1 字节
ADD A, R1;1 字节
MOV R1, A;1 字节
MOV A, B;2 字节
ADDC A, #0;2 字节
MOV R2, A;1 字节
MOV A, XH;2 字节
MOV B, YL;3 字节
| MUL AB;1 字节
ADD A, R1;1 字节
MOV R1, A;1 字节
MOV A, B;2 字节
ADDC A, R2;1 字节
MOV R2, A;1 字节
MOV A, XH;2 字节
MOV B, YH;3 字节
MUL AB;1 字节
ADD A, R2;1 字节
MOV R2, A;1 字节
MOV A, B;2 字节
ADDC A, #0;2 字节
MOV R3, A;1 字节
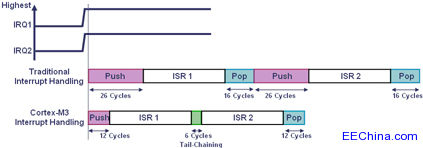
| MOV R4,&0130h
MOV R5,&0138h
MOV SumLo,R6
MOV SumHi,R7
(操作数被移入或移出内存映射的硬件乘法单元)
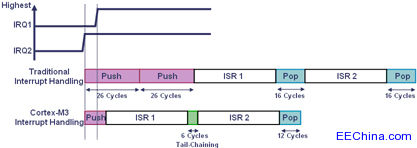
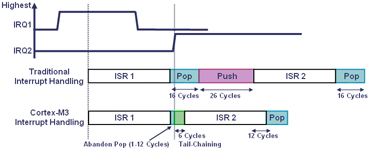
| MULS r0,r1,r0 |