1 引言
随着半导体技术的发展,DSP性能不断提高,被广泛应用在控制,通信,家电等领域中。DSP内部核心部件ALU具有极高的处理速度,而外部存储器的速度相对较低,存储系统已成为制约DSP发展的一个瓶颈。本文参照计算机存储结构,利用虚拟存储技术,对存储系统的结构进行了改进。在DSP中引入二级Cache存储器结构,在较小的硬件开销下提高了DSP的工作速度。结合高性能低功耗DSP cache设计这个项目,对两级cache的结构和算法做了探讨。
2 cache总体设计
传统的存储器主要由Dram组成,它的工作速度较慢,cache存储器主要由SRAM组成。在DSP中,存储系统可分层设计,将之分为两部分:容量较小的cache存储器和容量较大的主存储器,cache中存放着和主存中一致的较常用的指令与数据。DSP执行操作时可先向速度较快的cache取指令或数据,如果不命中则再从主存取指令或数据。通过提高cache的命中率可以大大加快DSP的整体运行速度,从而缓解由存储系统引起的瓶颈问题。
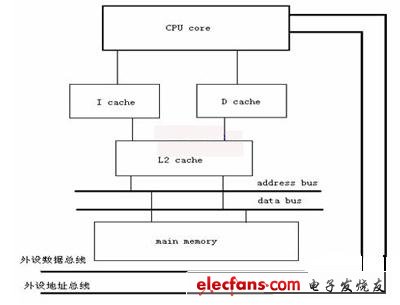
图1 cache的结构及互连简图
基于上述原理,我们设计了DSP的cache总体结构,如图1所示。图中设计采用了两级cache设计,第一级cache采用分立结构,将指令cache和数据cache分开设计,这样CPU可以对数据和指令进行平行操作,结合DSP取址,译码,读数,执行的四级流水线结构,充分提高系统效率。二级cache采用统一结构,数据和指令共用一个cache,此时可以根据程序执行的具体情况,二级cache自动平衡指令和数据间的负载,从而提高命中率。DSP若在一级cache中未找到需要的指令和数据,则可在二级cache中寻找。此结构下,一级cache找不到的数据和指令多数可在二级cache中找到,提高了整个cache系统的命中率。
增加一级cache的容量可提高命中率,但随着cache容量增大,电路结构将变得复杂,所用的芯片面积、功耗也会加大,而且cache的访问时间也会变长,从而影响到ALU的速度。综合考虑速度,面积,功耗等因素,我们把一级指令cache和数据cache的容量均定为4KB。
二级cache处于一级cache和主存储器之间,访问时间是3到4个ALU时钟周期,其容量一般是为一级cache的4到8倍。设计中我们将二级cache的容量为定位32KB。
3 cache的映射方式与地址结构
cache采用的映射方式通常有直接映射、关联映射、组关联映射三种,直接映射命中率低,容易发生抖动,关联映射虽然命中率较高,但电路复杂,权衡电路复杂性和命中率,我们主要采用组关联映射方法。在组关联映射中,可将主存空间分成块,cache空间分为组,一组包含多行,行的大小与块的大小相等。主存中的特定块只能映射到cache中的特定组,但可以映射到组内的不同行。若用j表示主存的块号,i表示cache中的组号,m表示cache的总行数,当cache分为v个组,每组k个行时,存在以下关系(见公式1、2),
设计中二级cache采用4路组相联的结构,分为共256组,每组4行,每行8个32位单元,总容量位32KB。cache的控制逻辑将存储器地址简单的分为三个域:标记域,组号和字。为了降低系统的功耗,采用了标记(tag)和数据体相分离的方案。为了加快访问速度,把cache中行号相同的块放在一个数据体中实现。这样cache就可分为4个标记存储器,4个数据存储器。每个标记存储器可放256个标记,每个数据存储体有256行数据。地址的划分如图2,tag的结构见图3。

图2 二级 cache的地址划分
 一级指令cache和数据cache采用组关联的结构,均分为32个组,每组4行,每行含有8个32位的单元,每个容量位4KB。一级cache的组和行与二级cache的组和行大小对应,在二级cache到指令cache和数据cache间,组之间我们采用直接映射的方式,组内用全关联方式。这样我们结合了组关联的灵活与全关联的命中率高的优点。 一级指令cache和数据cache采用组关联的结构,均分为32个组,每组4行,每行含有8个32位的单元,每个容量位4KB。一级cache的组和行与二级cache的组和行大小对应,在二级cache到指令cache和数据cache间,组之间我们采用直接映射的方式,组内用全关联方式。这样我们结合了组关联的灵活与全关联的命中率高的优点。
和二级cache相似,也把每组块号相同的数据放在同一个数据体中,共分为4个标记存储器,四个数据体存储器。每个标记存储器可放32个标记,每个数据存储体有32行数据。对主存地址的划分如图4。

图4 一级cache的地址划分
tag的结构见图5。

图5 一级cache tag结构
其中,P位是数据存在位, M位是数据修改的标记位,用于写策略的实现。
4 写策略及cache替换算法
写策略通常采用写回或写直达,采用写回法时,仅当cache中的某行数据被替换时,才更新存储器中相应数据。采用写直达法时,则每次写操作都要同时更新cache和主存储器中的数据。
所针对的DSP处于单处理器工作模式下,考虑到整个系统的数据处理效率,设计时我们采用写回法更新数据。写回法中,如果一级cache中的数据发生改变而未立即写回L2 cache和主存储器,或者L2 cache中的数据发生改变,未立即写回主存储器,那么就会造成数据不一致而导致错误。为保证数据的一致性,在驻留于cache中的某一块被替换之前,必须考虑它是否在cache中被修改。如果没有修改,则cache中原来的块就可以直接被替换掉,而不需回写;如果修改过,则意味着对cache这一行至少执行过一次写操作,那么在替换之前主存储器中的数据也必须随之做相应修改。为此我们在cache的tag中设置了修改位M,在执行回写操作前我们均对修改位进行判断,其值为1时表示数据被修改过,需回写,为0则表示未修改,不进行回写。
Cache的替换算法有很多种 ,为了提高命中率,在设计时采用了优化的LRU算法:栈链法[6]。栈链法的管理规则如下:
1) 把本次访问的块号与栈中保存的所有块号进行比较。如果发现有相等的,则cache命中,本次访问的块号从栈顶压入,栈内各单元的块号依次往下移,直至与本次访问的块号相等的那个单元为止,再往下的单元直至栈底都不改变。
2)如果相联比较没有发现相等的,则cache失效。栈底单元中的块号就是要被替换的块号。
实现时采用四个存储单元,每个单元两位,用来保存当前cache组的四个块号。首先是相联比较,以组号为地址,从四个标记寄存器中读取数据,和地址进行比较,然后就可以产生命中与否的信号,以及命中时相应的块号。
5 如何根据地址在cache中找到所需要的数据

图6 I cache查找数据的过程
能够映射到cache中某一行的数据很多,那么是怎样在cache中找到所需要的数据呢?主要是借助于标记。以 I cache 为例,当CPU发出读信号时,则首先以组号PA[7:3]为地址,从I cache的四组标记寄存器中读取标记,送往对应的比较器,和地址信号PA[31:8]进行比较,如果比较相等,且存在位有效,则表示命中。HIT1表示第1组命中,依次类推。HIT1 ,HIT2,HIT3,HIT4经过或门以后,就是总体命中与否的输出信号。如果HIT1有效,以PA[7:0]对cache的数据体1进行寻址,读取相应的数据。其它情况类似。在这个过程中,可以看出,地址和数据之间的一一对应关系。
6 数据块传输
数据块传输是对存储器的一种重要操作,根据译码电路的层次性,知道如果只是地址的低位发生改变,译码电路很快就可以达到稳定状态,选择对应的单元,进行读写。因此对数据进行整组传输,有利于提高传输的效率。在该cache中,对存储器的访问都是定长的,如果产生不命中的信号,则立即产生8拍定长的读写信号。具体实现时,设计了一个控制块传输信号的模块。每当产生不命中的信号,则把块传输的初始地址读入到该模块的初始地址寄存器,设置相应的传输单元数为8,以及对应的cache单元的读写信号。在每个时钟的上升沿,地址寄存器增1,传输单元个数寄存器减1,当传输单元个数寄存器的数据为0时,就结束传输。
由于L2 cache是个单端口的存储器,一级cache采用哈佛结构,对数据和指令同时进行操作,当D cache和I cache失效时,都会访问L2 cache,这样就有可能产生冲突。为了解决这个问题,在块传输控制的模块中,设置了一位busy位,用来标志总线忙状态。当某个请求得到响应,其余的请求只有进入等待状态。在设计时,制定了访问L2 cache的优先级协议:读指令不命中的优先级最高,写数据不命中的优先级次之,读数据不命中的优先级最低。当I cache和D cache同时产生不命中的信号时,根据优先级协议来访问L2 cache。
7 结束语
在命中率方面,采用两级cache结构及组关联映射方法提高了cache系统的命中率。在数据处理效率方面,由于一级cache采用哈佛结构,指令和数据可并行操作,显着提高了系统的数据处理能力。在功耗方面,采用了数据体和标记相分离的措施,这使得只有在cache命中的情况下,才会访问数据体,可降低系统的功耗。
整个设计采用自顶向下的设计流程,用Verilog语言描述整个系统,在synopsys工具下进行仿真和综合。在综合的结果中,指令cache的延迟最长,为4.3ns.整个cache系统的等效门数约24万个门。 |




