基于Xilinx FPGA IP核的FFT算法的设计与实现
|

- UID
- 1023229
- 来自
- 中国
|

基于Xilinx FPGA IP核的FFT算法的设计与实现
摘要
本文介绍了一种基于Xilinx IP核的FFT算法的设计与实现方法。在分析FFT算法模块图的基础上,以Xilinx Spartan-3A
DSP系列FPGA为平台,通过调用FFT IP核,验证FFT算法在中低端FPGA中的可行性和可靠性。 1 FFT算法简介
FFT(Fast Fourier Transform)算法是计算DFT(Discrete Fourier Transform)的高效算法。算法最初由J.W.Cooley和J.W.Tukey于1965年提出,之后又有新的算法不断涌现,总的来说发展方向有两个:一是针对N等于2的整数次幂的算法,如基2算法、基4算法和分裂基算法等; 另一个是N不等于2 的整数次幂的算法, 如素因子算法、Winograd算法等。其中基2算法是目前所常用的FFT算法,其核心思想是将N点的序列逐次分解为(N-1)/2点,最后分解为2点DFT进行计算,从而消除DFT中大量的重复运算。FFT算法可从时域或频域对序列进行分解:①时间抽取法(decimation in time,DIT),即直接将序列x(n)按奇、偶逐次分成奇数子序列和偶数子序列,然后通过计算子序列的DFT来实现整个序列的DFT; ② 频率抽取法(decimation in frequency,DIF),即将频域X(k)的序号k按照奇、偶逐次分解成偶数点子序列和奇数点子序列,然后计算子序列的DFT,得到整个频域内的DFT。时间抽取法和频率抽取法的计算复杂程度和所需要的计算量都是相同的,且由两种方法不同的分解形式可知:时间抽取法需要对输入数据序列x(n)进行重新排序,频率抽取法需要对输出数据序列X[k]进行进行排序。目前FFT算法已经广泛应用于数字信号处理、图像处理、石油勘探和地震预测等众多领域。与此同时,为了便于FFT算法在工程实践中的应用,各大FPGA生产商也都纷纷推出了具有相关功能的IP(Intellectual Property)模块库。其中由Xilinx公司研发的IP核Fast Fourier Transform V5.0提供了FFT算法多种可选的计算参数、结构、数据输入输出流的顺序方式,可以根据用户的需求方便地实现FFT算法。
2 Xilinx FFT IP核功能实现
Xilinx IP核功能是基于复杂系统功能的硬件描述语言(HDL)设计文件,这些验证的功能对于所有的Xilinx FPGA器件的结构都能够达到最优化,且提供硬件描述语言(VHDL,Verilog)的功能仿真模型,可以在标准EDA仿真工具中进行设计和调试。
Xilinx FFT IP核V5.0是Xilinx公司配套其FPGA开发工具ISE10.1推出的,其最大的系统时钟频率达到了550MHz,最大的数据吞吐量达到550MSPS,最高可进行65536点的FFT运算,最大输入数据和相位因子位宽为24bit(位宽越大,动态范围越大),支持所有的主流Xilinx FPGA芯片。同时,Xilinx FFT IP核V5.0可以实现变换长度为N点实数或复数形式的FFT变换及FFT逆变换(IFFT),N的取值范围是(8~65536)。输入数据实部和虚部都要以位宽为Mbits的二进制补码(Two's-Complement)形式表示,M取值范围是(8~24);同样,相位因子位宽取值范围也是(8~24)。数据、相位因子以及输出数据重排序的缓存数据,在FFT实现的过程中,都可以用块RAM(Block RAM)或者分布式RAM(Distributed RAM)进行存储。对于Burst I/O结构, 块RAM可以存储任意点数的数据和相位因子,而分布式RAM则只能存储点数不大于1024点的数据和相位因子;对于Streaming I/O结构,可采用混合存储的方法,先选择使用块RAM存储器的阶数的数量,然后对剩余的采用分布式RAM。
Xilinx FFT IP核有四种结构可供选择,用户可以在逻辑资源使用的多少和转换时间的长短之间进行取舍,具体情况分别如下。① 流水线,Streaming I/O结构:允许连续的数据处理,使用最多的逻辑资源。② 基4,Burst I/O结构:提供数据导入/导出阶段和处理阶段,导入数据和处理数据时单独进行的。此结构拥有较小的结构,但是转换时间较长。③ 基2,Burst I/O结构:使用较少的逻辑资源,同基4阶段,提供两阶段的过程。④ 基2 Lite Burst I/O结构:这是一种基于基
2结构的变体,采用了时分复用的方法使用了最少的逻辑资源,但是转换时间最长。
对于Burst I/O结构,使用DIT抽取法;流水线,Streaming I/O结构则使用DIF抽取法。
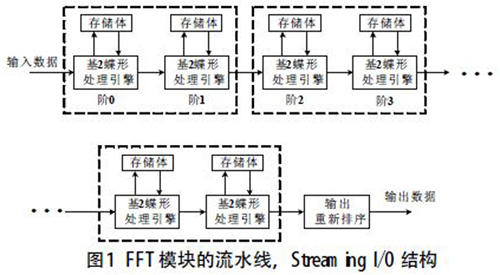
在实际硬件操作中,模块的执行速度是很重要的参数,因此本文进行的是基于流水线,Streaming I/O结构的仿真验证,进行连续的数据处理。流水线,Streaming I/O结构对一系列基2蝶形处理引擎采用流水线技术设计,且每个蝶形处理引擎都有自己独立的存储体对输入数据和中间数据进行存储(如图1)。这种结构下,FFT IP核具有同时处理当前帧N点数据,载入下一帧N点数据,输出前一帧N点数据的能力。
Xilinx FFT IP核V5.0支持三种算法类型:全精度无压缩、块浮点型和定点压缩(压缩比由用户自定义)。
对于全精度无压缩结构,数据通道内任意一位有意义的整数都将被保留,在运算过程中产生的小数部分都被截断或者取整。此种结构,对于定点算法,经过多级乘法操作以后,数据位宽将加倍递增,其输出位宽为(输入位宽+log2(数据转换长度)+1)bits。
对于块浮点型,对于一帧数据里面的任何一数据点有相同的压缩比,这个压缩比值由块指数(Block Exponent)作为输出值显示,而且只有在FFT IP核检测到将会产生数据溢出的时候,才会进行压缩运算。
本文所采用的是定点压缩结构。该结构相对于全精度无压缩结构,能够大大减少FPGA内部资源Xtreme DSP Slices和块RAM的使用,而相对于块浮点型,可灵活调节压缩比。定点压缩结构的压缩比例表(Scale_SCH)完全由用户自定义得到。压缩比例是按照1、2、4或者8对每一阶进行压缩,即对应于分别向右移位0、1、2或者3。如果压缩不充分,则蝶形输出结果会超出其动态范围,引起数据溢出。对于Burst I/O结构,Scale_SCH的表示方法:对于每一阶的压缩比都由指定的一个2bits的数表示,零阶的2bits数为最低位,具体形式为[⋯N4,N3,N2,N1,N0],每一个2bits数分别对应着相应阶数的压缩比。例:对于基4结构,数据转换长度N=1024,Scale_SCH=[01 10 00 1110]则表示对阶0右移位2,对阶1右移位3,对阶2右移位0,对阶3右移位2,对阶4右移位1。经验总结(可以防止产生数据溢出):对于1024点的基4,Burst I/O结构,Scale_SCH=[10 10 10 10 11];而对于1024点的基2结构,Scale_SCH=[01 01 01 01 01 01 01 01 01 10]。
对于流水线,Streaming I/O结构,把临近的一对基2阶组在一起,即阶0和阶1为组0,阶2和阶3为组1,等等。Scale_SCH的表示方法:对于每一组的压缩比都由指定的一个2bits的数表示,零组的2bits数为最低位,具体形式为[⋯N4,N3,N2,N1,N0],每一个2bits数分别对应着相应组的压缩比,表示同组内的两个基2阶有相同的压缩比。例:数据长度N=1024,Scale_SCH=[10 10 00 01 11]表示对组0(阶0和阶1)右移位3,对组1(阶2和阶3)右移位1,对组2(阶4和阶5)没有移位,对组3(阶6和阶7)右移位2,对组4(阶8和阶9)右移位2。若变换长度N不是4的幂次方的时候,最后一组只包含一个基2阶,只能用00或者01表示。经验总结(可以防止产生数据溢出):N=512时,Scale_SCH=[01 10 10 10 11];N=1024时,Scale_SCH=[10 10 10 10 11]。
压缩比例Scale_SCH的位宽,对于流水线,Streaming I/O结构和基4,Burst I/O结构,为2*ceil(0.5*log2(N));对于基2,Burst I/O结构和基2 Lite Burst I/O结构,为2* log2(N),其中N为转换数据长度。
3 FFT IP核的仿真验证
通过例化调用Xilinx IP核来实现一个512点、数据位宽和相位因子位宽都为16bit的FFT算法模块,时钟频率为50MHz(时钟频率越高,可以获得更高的复用倍数,节省更多的资源面积),采用流水线,Streaming I/O和定点压缩结构,完成在中低端FPGA上的调试,验证其可靠性和可行性。为了方便验证FFT IP核功能的正确性:以零开始计数,在每个时钟上升沿到来时,进行加一运算得到的数据,分别作为其输入信号的实部和输入信号的虚部。Scale_SCH=[01 10 10 10 11],在ISE10.1中建工程,例化调用Xilinx FFT IP核,然后利用ModelSimSE6.5进行仿真,其仿真时序如图2所示。

时序验证方面:可以看出整个时序在实现中是完全正确的。从时序图可以看出:busy信号高的的时候表明FFT IP核正在进行FFT运算,busy信号拉低后表明运算已经结束,要向外输出FFT运算结果;edone信号在done信号之前一个周期到达;此时,done信号拉高一个周期,表明FFT运算完成;而且,由于进行的是512点的FFT运算,所以,每间隔512个时钟周期,edone和done信号都会拉高一次;rfd信号一直拉高,表明输入数据一直传送到FFT IP核的输入端口,跟采用流
水线,Streaming I/O结构,可以进行连续数据处理是一致的;dv信号一直为高,表明输出的信号一直有效。
功能验证方面:根据FFT IP核在流水线,Streaming I/O结构下,间隔每一帧数据需要三帧才能输出计算结果的特点,可以推算出上面仿真图形里面输出结果时刻对应着[94:605]+ [94:605]*j的FFT输出结果。把Matlab里面通过仿真得到的结果,按照Scale_SCH的比例进行压缩,与上面得到的结果是一致的,表明了FFT IP核是正常工作的。
4 结语
本文主要通过对FFT IP核的整体测试,验证FFT算法在中低端FPGA中的可行性和可靠性。在选用流水线结构实现FFT的基础上,采用定点压缩结构,减少了数据的读取和处理时间,更好的满足了FFT处理数据的需要。
作者:刘彬杰,吴廷婷 |
|
|
|
|
|




