forsuccess 当前离线
论坛元老
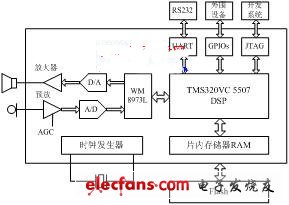
图1 语音识别系统硬件框图
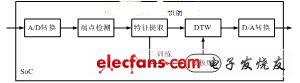
(a) 特定人系统
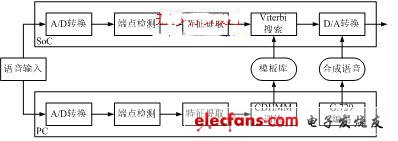
(b) 非特定人系统
图2 识别系统框架
3.2 语音传输与中断程序设计
(a) 端点检测基本流程
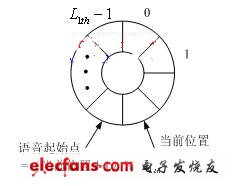
(b) 循环缓冲区设计
图3 基于循环缓冲区的端点检测流程
图4 非特定人系统第一阶段多候选识别率
订阅 TOP