|

- UID
- 1023166
- 性别
- 男
- 来自
- 燕山大学
|

AMBA APB4 与 AMBA3 AHB-Lite 1.0 协议介绍
关键词: AMBA , APB4 , AHB-Lite
作者:Allen Zhan
[介绍]
根据 ARM 的说法, 今天 AMBA 已经成为了业界事实上的总线标准. 本文我们简单对AMBA4 中的 APB v2.0(也称为 APB4), 以及 AMBA3 AHB-Lite v1.0 进行简单的了解. 我们的介绍集中在, 我们比较有兴趣的地方. 尽管如此, 也可能几乎覆盖了协议中几个最重要的部分.
[AMBA APB]
AMBA
Advanced Microcontroller Bus Architecture, 由ARM定义的总线架构(标准), 由一个协议家族组成. ARM 声称这一标准已经称为事实上的 uController 业界通用标准.
APB
The Advanced Peripheral Bus(APB) 是 AMBA 协议家族中一个组成部分.
它被定义为一个 low-cost 的接口, 为了最小能耗与减小接口的复杂性进行的优化设计.
被用于连接通用外围, 比如 timers, inerrupt controllers, UART是, and IOs.
通过 system-to-peripheral bus bridge 与 main system bus 相连, 有助于降低能耗.
APB 版本
当前(2013年9月), 最近的 APB协议版本是 AMBA APB Protocol Specification v2.0. 或者因为属于 AMBA4 家族中的发布协议, 一般也被称为 APB4.
而在第一个版本(APB2 )中, APB 的基本组元, APB bridge 与 APB slave 被定义.
而在 APB3 中, Ready signal 被引入, 这意味着增加了操作状态中, 增加了 wait state. 另外增加了 PSLVERR, 用于错误报告的 signal.
最近的 APB4, 增加了 PPROT 与 PSTRB signal.
APB bridge 与 APB slave
我们可以挂载各种"慢速"的外设在 APB 上, 比如 IO, 比如 UART, 比如 SPI, etc. 它们都作为 slave 的角色存在.
但是, 我们想想看, bridge 这个 role 就蛮有意思. 它实际上暗示我们, APB 不能"单独存在". 我们这里所谓不能"单独存在"的意思, 是说 APB 一定不能直接连接在 processor 上(或者说 arm core上). 而最可能的, 是通过 APB bridge 而连接在高速的 bus 上.
实际上, 在 AHB-Lite 协议中, 我们发现 APB bridge 被作为 AHB-Lite 的 slave 而被定义.
Data buses
APB 协议有两个独立的 data bus, 一个用来读 data, 一个用来写 data.
因为没有独立的握手信号, 所以在两根bus上, 同一时刻数据传输不能同时发生.
Write Transfers
我们简单对 APB 的 trasfers 过程进行分析, 比如我们分析 write transfer with no wait states:
[图例1: Write transfer with no wait states]
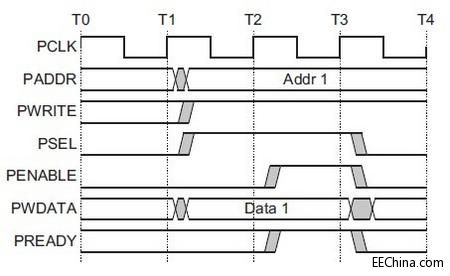
T0: Idle state
T1: Setup state
write address PADDR, write data PWDATA
setup state 仅仅只保持 1pcs clock cycle, 而在下一个 PCLK 的上升沿, 一定进入 Access state.
T2: Access state
APB bridge 通过拉高 PENABLE, 通知slave 第二阶段(也就是 access phase) 开始.
因为是 no wait states, 我们见到了 PREADY 在此被拉高, 表示 slave 通知 bridge, 在下一个 PCLK 的上升沿, 本次 transfer 的过程可以结束.
T3: finish transfer, then enter Idle state again or the next setup.
PREADY 拉低, 说明 slave 通知本次 transfer 结束. 在 PREADY unasserted 之前, PADDR, PWDATA, 以及其他的 signals 都应该保持有效.
从上述时序中, 我们了解到, write transfer 看来至少需要 3 cycles. setup - access - finish
而在一个 write transfer with wait states 时序中,
[图例2: Write transfer with wait states]
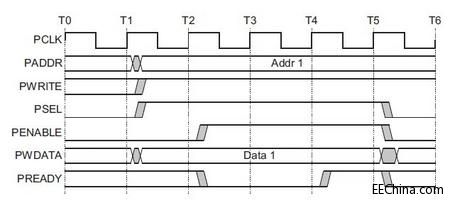
我们见到了, Slave 通过 unassert 的方式(拉低), 延迟了2pcs cycles(根据图例的例子), 这样在 T2 状态上的拉高动作, 被延时到 T4 进行拉高. 也就是 Slave 通知在 T5 cycle 中结束本次 transfer.
这就是通过 PREADY 引入了 wait state 后现象, 我们注意到, 一般的术语被称为"extend the transfer".
Operating States
Read Transfer 的情形与 Write Transfer 类似, 这样, 我们就基本完备讲述了 APB protocol, 附上 Operating States 进行理解:
[图例3: State Diagram]
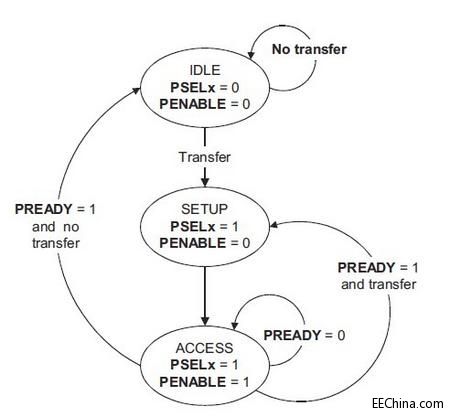
transfer cycles
APB protocol 中, 明确指出: "每个 Transfer 至少消耗 2 cycles".
而我们检查, 即使是 transfer with no wait state, 也最少消耗了 3 cycles. 这里我们理解, 在图例1中, T3 状态下, finish 本次 transfer后, 如果要连续操作下一个写传递的过程, 那么则在 T3 状态下保持 PSEL asserted, 配合 PREADY unasserted, 恰好又进入了如 T1 cycle 相同的 setup state, 这时需要 bridge 更新地址 PWRITE, 以及数据 PWDATA. 也就是在连续 transfer(针对同一个 slave)的操作中, transfer 最少只消耗 2 cycle.
我们没有在 APB 协议中, 获得上述猜测的详解, 我们保留上述对 "2 cycles" 的理解猜测于此.
总结
我们通过对 APB protocol 的理解, 得知 APB 是 unpipeline 的 bus. 无论如何, setup state 将占据一个 cycle, 而 access state 将占据另一个.
这种 unpipeline 的设计, 很可能就是 APB 被作为连接外围的, 而不是用于 processor 之间的 memory 连接的 BUS 的重要原因. 因其不要求外围在一个 cycle 中对 address 进行取样, 这也给外围更多的时间反应, 至少比较而言, 使用 APB 的外围可以具备更小的 bandwidth.
[AMBA AHB-Lite]
AHB-Lite
AHB: Advanced High-performance Bus
用于高表现力高clock频率的系统. 最经常的使用是连接 internal memeory device, external memory interface, 以及 high bandwidth 外围. 其基本组元是: Master, Slave, Decoder, Multiplexor.
在 address/control phase 与 data phase 中, 存在 fixed pipeline.
AHB: 仅仅支持 AMBA AXI protocol 的功能子集(subset).
AHB-Lite: 如果除去在 master 与 slave IP 开发中不需要的部分, 则 AHB protocol 的这个 subset 则定义为 AHB-Lite.
Operation
每一个 trasfer 都包括 Address phase 与 Data Phase.
Address 不允许被 extend, 即便是来自 Slave 的请求, 因此我们可以想象, 全部的 Slaves 都必须在 Address phase(1 cycle) 完成 sampling address.
但是与 APB 一样, Slave 也可以通过 HREADY signal 请求 extend data phase, 增加额外的时间去 sample data.
HRESP signal 被用来说明 transfer 的成功与否.
Address 总是可以在一个 single HCLK cycle 中完成, 除非是之前的 bus transfer 被 extend(我们理解, 这里应该是只有 data 才能做这个 extend).
Data 可以占有数个 HCLK cycle, 这取决于 HREADY signal 是否 extend transfer.
因此, Address phase 可以与 Data phase 的 overlapping, 就是 pipeline 的基础.
[图例4: 在不同地址上的3个transfer的例子]
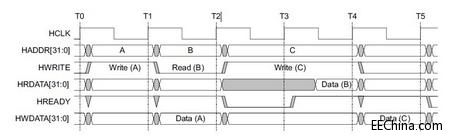
Transfer types
Transfer types 包括: IDLE, BUSY, NONSEQ, SEQ
同猜想的一样, 对于 Slave, 可以通过 HREADY 实现 extend transfer, 我们觉得, 这或者就是"较为慢速"的 Slave 实现 delay 的方式.
而 Master 如果在 HTRANS[1:0] 中使用 BUSY, 也可以在 burst transfer 的过程中, 插入idle cycles. 这让人觉得, 这应算是 master 试图做 delay 的方式.
[图例5: BUSY Transfer type]
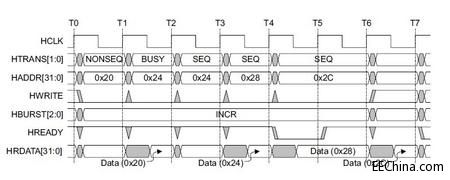
值得注意的是, 该例子, 使用了 4-beat 的 burst operation.
Locked transfers
通过 HMASTLOCK, master 可以要求完成"锁定"的 transfer, 不能被打断. 而这个用法, 往往在多个 master 的用法中存在.
[图例6: Locked transfers]
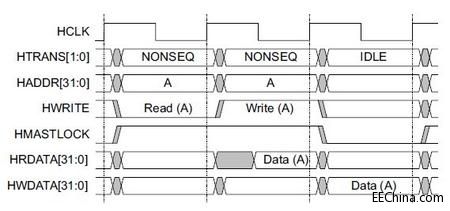
Default slave
如果不存在的的 memory map 被 master 点中, AHB-Lite 协议给出了一个解决方案, 就是必须存在一个增加的 default slave 来进行回应.
Slave transfer responses
AHB-Lite 协议中指出, Master 一旦开始一个 transfer后, 将无法主动取消这个 transfer.
因此, 通过来自 Slave 的 HRESP signal 的状态, 判断 transfer 的成功与否将是重要的.
HWDATA 与 HRDATA
同 APB 协议一样, data bus 的 read 与 write 是分离的.
所以不需要"三态"的 drivers. 我们此时有点大脑短路, 不太理解这里的意思, 这应该是说, 如果我们在单一的, 而不是分离的 data bus 上实现 read data 以及 write data, 那么我们就需要"三态驱动器"? 这里的 tristate 为何意? --有知道的同行, 这里定能有教于我.
[参考文献]
1. AMBA3 AHB-Lite Protocol v1.0 Specification
2. AMBA APB protocol v2.0 Specification
[结语]
让我们引用 Sailing 的文章 "ARM与x86之4--EAGLE is Coming!" (From:http://blog.sina.com.cn/s/blog_6472c4cc0100mnza.html) 中的论述 AMBA 的片段作为结语:
<剪切>
"最令Intel尴尬的是,x86处理器并没有一个与 AMBA 总线类似的 SoC 平台总线,这是Intel 进军嵌入式领域一个不小的障碍。Intel 或者定义一条全新的SoC平台总线,或者集成AMBA总线。从加速推出产品的角度上,直接使用 AMBA 总线无疑是一条捷径。而世上没有捷径,从更长远的时间上看,借用AMBA总线,会使ARM阵营更加强大。最初的所谓捷径不过是为他人做的嫁衣裳。"
"面对ARM内核,Intel并不畏惧,面对AMBA总线阵营,Intel只剩下无奈。可以预计在相当长的一段时间里,Intel无法推出一条能和AMBA总线抗衡的SoC平台总线。Intel只能暂时向AMBA总线示弱。"
<剪切>
Written by Allen Zhan |
|
|



