|

- UID
- 863084
|

一 研究的目的和意义
计算机智能化一直是计算机科学人员研究的重点和计算机发展的方向,计算机智能化首先离不开的就是人机交互,早期计算机通过键、鼠标、扫描仪等等就像与计算机的交互作业,
但是随着人们对计算机的功能和需求日益增长,这些最基本的交互工具已经不能满足人们的要求了,人们希望计算机能像一个人一样跟自然人进行交流,希望能够有更好的交互设备的出现。 人类的感知能力很强,可以通过声音、图像、触觉等等来认识这个世界,同样我们也希望计算机能做到这一点,语音识别无疑是在这方面领域的一大突破。
语音识别技术是集声学、语音学、语言学、计算机、信息处理和人工智能等诸领域的一项综合技术。其根本目的在于让人机交互更方便、自然、易用。为了对语音识别技术的了解和研究。我们应用xilinx公司的fpga平台软件和XUPV2Pro开发板,运用语音来控制选频滤波器的的滤波范围。选择xilinx的XUPV2Pro开发板主要是因为XUPV2Pro开发板中包括了LM4550音频编解码芯片,可以实现语音信号的采集、编码。 另外此开发板的核心芯片Virtex2 Pro包含了1万3千多个Slice,嵌入了PowerPC和MircoBlaze,功能强大,可以实现各种逻辑运算和算术运算,在本设计中用它实现了语音识别和选频滤波器的功能。
二 研究主要内容和结构安排
目前许多语音识别的算法研究都是基于软件平台的,真正的语音识别硬件实现很少,我们的研究针对小词汇量孤立词非特定人的语音识别系统,学习并研究当前主流的语音识别算法。
主要内容:
(1)研究并使用多种fpga设计方法对数字信号处理:硬件DSP的Matlab建模设计方法;IP核设计方法等等。运用这些算法实现 FFT 、DCT、和乘法、对数运算,在fpga中综合运用这些方法。
(2)首先语音识别的第一步就是从XUPV2Pro开发板上的ac97芯片中得到语音的数字信号,即从ac97中提取出声音信号,以待处理。
(3)语音识别的前端处理(预处理和端点检测),这部分算法直接由同学根据其软件算法用hdl语言编程实现成硬件模块,留出端口。
(4)在前端处理后,下面的工作就是对语音信号进行特征提取的工作。在比较各种语音特征参数的优缺点之后,我们选定MFCC参数作为非特定人的语音特征。采用矢量量化来进行编码压缩来节约存储空间。此项处理我们也采用硬件结构来实现。
(5)对于语音识别过程中的训练与匹配问题,我们采用隐马尔可夫模型。对于隐马尔可夫同样用硬件描述语言编写代码实现该算法。
三 基本结构图
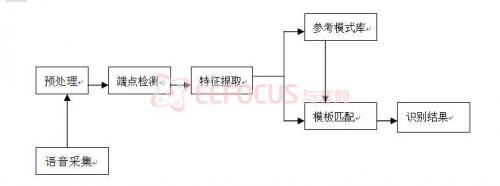
四 模块具体实现介绍
1、语音信号的提取
语音识别的第一步就是要将话筒传来的信号转成计算机能处理的数字信号,实现模拟信号向数字信号的转换。XUPV2Pro开发板自带lm4550 ac‘97芯片,我们可以通过ac97芯片来获得所需要的数字信号。
2、前端处理部分(预处理和端点检测部分)
前端处理包括预加重、分帧、加窗、以及本设计基于状态机的端点检测,是语音识别的前端处理,我们采用传统的hdl语言设计模块的方法。
(1) 为了便于实现,FIR预加重滤波器用差分方程表示为:
S=S-0.94*S[i-1] 0≦i≦N
其中,S为原始语音信号序列,N为语音长度,上面显示其在时域上的特性。又因为0.94接近15/16,所以将上面的式子变为
S=S-15/16*S[i-1] =S-(-S[i-1]-S[i-1]/16)
除以16可以用右移4位来实现,这样就将除法运算化简为移位运算,降低了计算的复杂度。在后面的模块设计中,也称以或者除以一些这样的数,这些数为2的幂次,都可以用移位来实现。
预加重的硬件实现图如下:
 |
|




