|
 
- UID
- 1023230
|

介绍了一种以ARM为核心的嵌入式语音识别模块的设计与实现。模块的核心处理单元选用ST公司的基于ARM Cortex-M3内核的32位处理器STM32F103C8T6。本模块以对话管理单元为中心,通过以LD3320芯片为核心的硬件单元实现语音识别功能,采用嵌入式操作系统μC/OS-II来实现统一的任务调度和外围设备管理。经过大量的实验数据验证,本文设计的语音识别模块具有高实时性、高识别率、高稳定性的优点。
服务机器人以服务为目的,因此人们需要一种更方便、更自然、更加人性化的方式与机器人交互,而不再满足于复杂的键盘和按钮操作。基于听觉的人机交互是该领域的一个重要发展方向。目前主流的语音识别技术是基于统计模式。然而,由于统计模型训练算法复杂,运算量大,一般由工控机、PC机或笔记本来完成,这无疑限制了它的运用。嵌入式语音交互已成为目前研究的热门课题。
嵌入式语音识别系统和PC机的语音识别系统相比,虽然其运算速度和内存容量有一定限制,但它具有体积小、功耗低、可靠性高、投入小、安装灵活等优点,特别适用于智能家居、机器人及消费电子等领域。
模块整体方案及架构
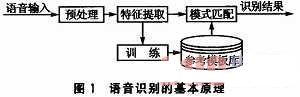
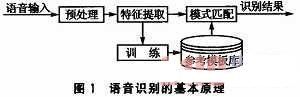
语音识别的基本原理如图1所示。语音识别包括两个阶段:训练和识别。不管是训练还是识别,都必须对输入语音预处理和特征提取。训练阶段所做的具体工作是通过用户输入若干次训练语音,经过预处理和特征提取后得到特征矢量参数,最后通过特征建模达到建立训练语音的参考模型库的目的。而识别阶段所做的主要工作是将输入语音的特征矢量参数和参考模型库中的参考模型进行相似性度量比较,然后把相似性最高的输入特征矢量作为识别结果输出。这样,最终就达到了语音识别的目的。
现有的语音识别技术按照识别对象可以分为特定人识别和非特定人识别。特定人识别是指识别对象为专门的人,非特定人识别是指识别对象是针对大多数用户,一般需要采集多个人的语音进行录音和训练,经过学习,达到较高的识别率。
基于现有技术开发嵌入式语音交互系统,目前主要有两种方式:一种是直接在嵌入式处理器中调用语音开发包;另一种是嵌入式处理器外围扩展语音芯片。第一种方法程序量大,计算复杂,需要占用大量的处理器资源,开发周期长;第二种方法相对简单,只需要关注语音芯片的接口部分与微处理器相连,结构简单,搭建方便,微处理器的计算负担大大降低,增强了可靠性,缩短了开发周期。
语音识别技术在国内外的发展十分迅速。目前国内在PC应用领域,具有代表性的有:科大讯飞的InterReco2.0、中科模式识别的Pattek ASR3.0、捷通华声的jASRv5.5;在嵌入式应用领域,具有代表性的有:凌阳的SPCE061A、ICRoute的LD332X、上海华镇电子的WS-117。
本文的语音识别方案是以嵌入式微处理器为核心,外围加非特定人语音识别芯片及相关电路构成。语音识别芯片选用ICRoute公司的LD33 20芯片。
硬件电路设计
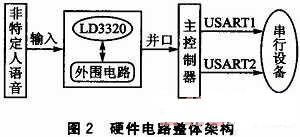
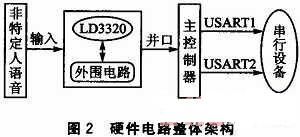
如图2所示,硬件电路主要包括主控核心部分和语音识别部分。语音进入语音识别部分后,将处理过的数据并行传输到主控制器,主控制器经过处理后,发送命令数据到USART,USART可用于扩展外围串行设备,如语音合成模块等。
主控制器电路
本文的主控制器选用的是ST公司的STM32F103C8T6芯片。该芯片基于ARM Cottex-M3 32位的RISC内核,工作频率最高可达72 MHz,内置高速存储器(64 KB的闪存和20 KB的SRAM),丰富的增强I/O端口和联接到两条APB总线的外设。STM32系列提供了全新的32位产品选项,结合了高性能、实时、低功耗、低电压等特性,同时保持了高集成度和易于开发的优势,将32位MCU世界的性能和功效引向一个新的级别。 |
|