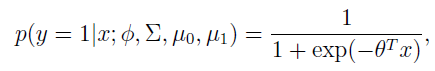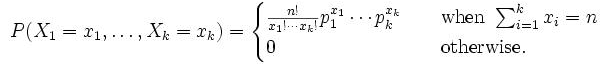首页
|
新闻
|
新品
|
文库
|
方案
|
视频
|
下载
|
商城
|
开发板
|
数据中心
|
座谈新版
|
培训
|
工具
|
博客
|
论坛
|
百科
|
GEC
|
活动
|
主题月
|
电子展
注册
登录
论坛
博客
搜索
帮助
导航
默认风格
uchome
discuz6
GreenM
»
DSP技术
» 判别模型、生成模型与朴素贝叶斯方法(2)
返回列表
回复
发帖
发新话题
发布投票
发布悬赏
发布辩论
发布活动
发布视频
发布商品
判别模型、生成模型与朴素贝叶斯方法(2)
发短消息
加为好友
yuyang911220
当前离线
UID
1029342
帖子
9914
精华
0
积分
4959
阅读权限
90
在线时间
286 小时
注册时间
2014-5-22
最后登录
2017-7-24
论坛元老
UID
1029342
性别
男
1
#
打印
字体大小:
t
T
yuyang911220
发表于 2016-7-11 10:01
|
只看该作者
判别模型、生成模型与朴素贝叶斯方法(2)
模型
,
高斯
3) 高斯判别分析(GDA)与logistic回归的关系
将GDA用条件概率方式来表述的话,如下:
y是x的函数,其中
都是参数。
进一步推导出
这里的
是
的函数。
这个形式就是logistic回归的形式。
也就是说如果p(x|y)符合多元高斯分布,那么p(y|x)符合logistic回归模型。反之,不成立。为什么反过来不成立呢?因为GDA有着更强的假设条件和约束。
如果认定训练数据满足多元高斯分布,那么GDA能够在训练集上是最好的模型。然而,我们往往事先不知道训练数据满足什么样的分布,不能做很强的假设。Logistic回归的条件假设要弱于GDA,因此更多的时候采用logistic回归的方法。
例如,训练数据满足泊松分布,
,那么p(y|x)也是logistic回归的。这个时候如果采用GDA,那么效果会比较差,因为训练数据特征的分布不是多元高斯分布,而是泊松分布。
这也是logistic回归用的更多的原因。
3朴素贝叶斯模型在GDA中,我们要求特征向量x是连续实数向量。如果x是离散值的话,可以考虑采用朴素贝叶斯的分类方法。
假如要分类垃圾邮件和正常邮件。分类邮件是文本分类的一种应用。
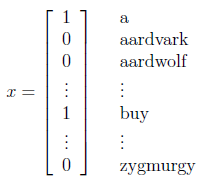
假设采用最简单的特征描述方法,首先找一部英语词典,将里面的单词全部列出来。然后将每封邮件表示成一个向量,向量中每一维都是字典中的一个词的0/1值,1表示该词在邮件中出现,0表示未出现。
比如一封邮件中出现了“a”和“buy”,没有出现“aardvark”、“aardwolf”和“zygmurgy”,那么可以形式化表示为:
假设字典中总共有5000个词,那么x是5000维的。这时候如果要建立多项式分布模型(二项分布的扩展)。
多项式分布(multinomial distribution)
某随机实验如果有k个可能结局A1,A2,…,Ak,它们的概率分布分别是p1,p2,…,pk,那么在N次采样的总结果中,A1出现n1次,A2出现n2次,…,Ak出现nk次的这种事件的出现概率P有下面公式:(Xi代表出现ni次)
对应到上面的问题上来,把每封邮件当做一次随机试验,那么结果的可能性有
种。意味着pi有
个,参数太多,不可能用来建模。
收藏
分享
评分
继承事业,薪火相传
回复
引用
订阅
TOP
返回列表
FPGA/CPLD可编程逻辑
无线技术
MCU 单片机技术
汽车电子
测试测量
电商论坛
Pine A64
资料下载
方案分享
FAQ
行业应用
消费电子
便携式设备
医疗电子
汽车电子
工业控制
热门技术
智能可穿戴
3D打印
智能家居
综合设计
示波器技术
存储器
电子制造
计算机和外设
软件开发
分立器件
传感器技术
无源元件
资料共享
PCB综合技术
综合技术交流
EDA
MCU 单片机技术
ST MCU
Freescale MCU
NXP MCU
新唐 MCU
MIPS
X86
ARM
PowerPC
DSP技术
嵌入式技术
FPGA/CPLD可编程逻辑
模拟电路
数字电路
富士通半导体FRAM 铁电存储器“免费样片”使用心得
电源与功率管理
LED技术
测试测量
通信技术
3G
无线技术
微波在线
综合交流区
职场驿站
活动专区
在线座谈交流区
紧缺人才培训课程交流区
意见和建议