这是一篇脱胎于我在公司做的一个training里关于CPLD时序部分讲解的博客。
在此感谢网络上两篇流传度很广的关于建立保持时间的文章的原作者,一篇叫做“数字电路中的建立时间与保持时间”,另一篇叫做“FPGA时序分析,时序约束知识”。(由于转来转去,已经找不到原出处。)
本文将从三个层面(门级,芯片级和板级)上来分析数字电路中的建立保持时间,目的是理清CPLD设计和板级设计在时序上的关系,说明时序分析在设计过程中的必要性。
首先让我们来建立一个包含门级,芯片级和板级的电路的分析模型,如下图:
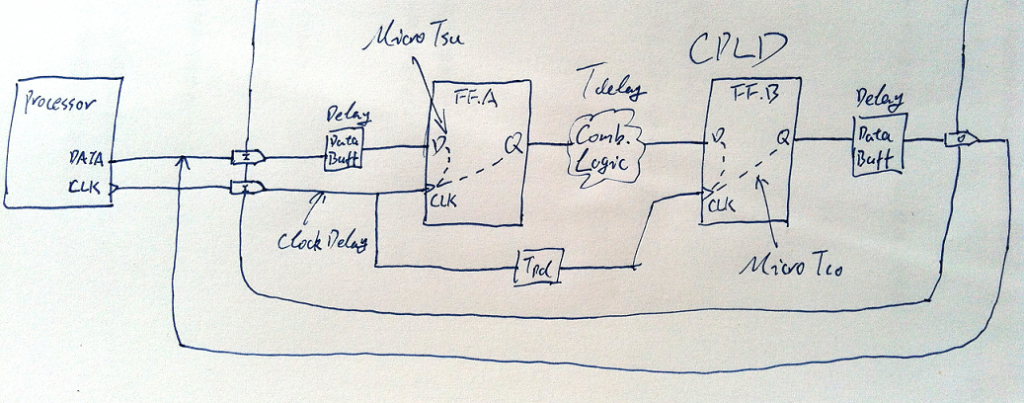
接下来需要搞清楚几个概念:
Micro Tco: 触发器输出的响应时间,也可以理解为触发器输出在clk上升沿到来后的时间内发生变化, 之后稳定,也可以理解输出延迟;
Micro Tsu: 触发器的建立时间;
Micro Th: 触发器的保持时间;
Tdelay: 触发器输出的变化经过组合逻辑元件和内部走线所需的附加时间,一般Tdelay = Tcomb + Tnet也就是等于组合逻辑延时加互联延时;
T: 时钟周期;
Tpd : propagation delay,不同地方定义不同,我们这里只作时钟skew,等于Tskew;
Tperiod: 时钟周期容限,要求实际的T>Tperiod;
Tsu: 芯片级建立时间;
Th: 芯片级保持时间;
Tco: 芯片级输出延迟。
*某些文章会加上建立保持时间容限的概念,个人觉得反倒让理解更困难。
**由于在CPLD设计中,参考时钟一般都是利用系统时钟资源和全局时钟管脚输入来进行分配的,这样在内部时钟到达各触发器的延时几乎完全相等,Tskew(Tpd)可以忽略不计。
1.先从门级电路的分析开始:
根据分析模型,我们可以得到如下时序图:
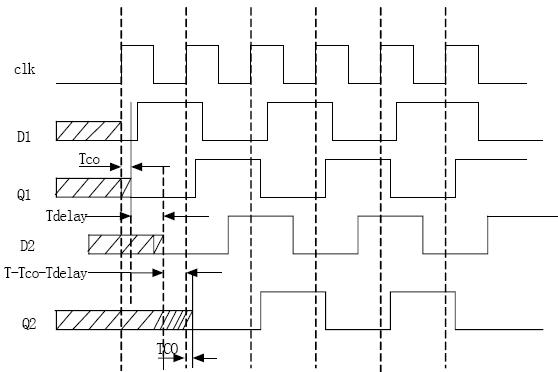
由时序图得出触发器B的建立时间T3需要满足以下条件:
T - Micro Tco - Tdelay >= T3
再来看保持时间。
首先对于数据接收端来说,任何时钟沿采样的数据,都是发送端前一时钟周期发送的数据。发送端可能每个时钟周期都要发送数据,那么对于接收端来说,任何一个时钟沿后一段时间,数据线上的数据都会被发送端第二次发送的数据改变,所以保持时间容限其实是由于下一个时钟节拍上的数据引起的。
有效数据在Micro Tco + Tdelay之后到达触发器,如果保持时间T4 > Micro Tco + Tdelay,则下一个有效数据到达后,保持时间T4仍然没结束,但前一个数据已经被破坏,所以触发器B的保持时间T4需要满足以下条件:
T4 <= Micro Tco + Tdelay。
至此,我还可以发现触发器B的建立时间T3的最大值加上保持时间T4的最大值就是一个完整的时钟周期T,即:
Max Micro Tsu + Max Micro Th = T
由于在实际的设计当中,CPLD内部触发器的建立保持时间是由工艺芯片系列所决定了的。所以时钟周期容限Tperiod将很大程度依赖于设计中组合逻辑的延迟和互联走线的延迟。
2.再说说芯片级电路的建立保持时间和Tperiod:
芯片级的时序分析主要是着眼于异步信号从芯片外部输入进来,到达第一个触发器时所需要满足的建立保持时间;或是从时钟管脚输入到数据管脚输出信号所需要的输出延时。
对于CPLD/FPGA来说,芯片级的时序多是用于全局管脚的constraint设置。在implement的时候,由开发环境自行去调整布局走线来满足芯片的时序要求。
对照着我们画的分析模型,就可以按图索骥的根据各个时序的定义列出表达式,分析相对来说比较简单。
Clock Setup Time (tsu) 要想正确采样数据,就必须使数据和使能信号在有效时钟沿到达前就准备好,所谓时钟建立时间就是指时钟到达前,数据和使能已经准备好的最小时间间隔。如下图所示:

所以,Tsu = Data Delay - Clock Delay + Micro Tsu
时钟保持时间(Th)是指能保证有效时钟沿正确采用的数据和使能信号的最小稳定时间。其定义如下图所示:

所以,Th = Clock Delay - Data Delay + Micro Th。(此式也可由 Tsu + Th = T得到。)
Clock-to-Output Delay (Tco) 这个时间指的是当时钟有效沿变化后,将数据推倒同步时序路径的输出端的最小时间间隔。如下图所示:

所以,Tco = Clock Delay + Micro Tco + Data Delay
最后,Clock Period根据定义可知 Tperiod = Micro Tco + Tdelay + Micro Tsu。
3.最后让我们从板级的角度来时间分析一个local bus总线的传输时序:
板级的分析,比芯片级的分析更加简单,只要在此前的基础上加上一个trace走线延迟的时间就可以了。而且由于在实际走线当中,我们已经做了等长处理,所以大部分时候都可以忽略掉传输线的延迟。
但是,由于站在板级的角度,我们的CPLD/FPGA将需要和别的芯片进行互连通信,这里面涉及到软件的时序寄存器设置,也涉及到SI信号完整性的测试标准,所以我将同时从收发读写两个角度来分析时序在实际应用中的需求。
以local bus为例。
local bus是典型的点对多点的总线结构,设备由片选信号来进行区分。在Processor内部针对不同片选,通常都有两个寄存器来控制——BR和OR(沿用freescale的叫法,其他处理器类同)。BR控制片选映射到Memory map中的基地址,OR就是用来调节时序的。也就是说针对不同的片选下挂的设备,可以独立的调整读写时序。
local bus读操作:Processor在OE的上升沿去采样来自CPLD发出的数据。
local bus写操作:CPLD在WE的上升沿去采样来自Processor发出的数据。
对于写操作来说,CPLD是输入端,采样端,所以Processor的WE和DATA的时序要满足CPLD的建立保持时间:
Twp >= CPLD Tsu + Trace delay (如果走线采用等长处理,可忽略trace delay)
对于读操作来说,CPLD是数据输出端,Processor是接收端,CPLD需要在OE上升沿来到前和来到后满足processor的建立保持时间。通常processor的保持时间很短,几乎等于0,而且考虑到传输线的延迟和CPLD Tco的延迟,保持时间通常都是可以满足的,所以这里只说建立时间。由于OE本身不是clock,不具有周期性,所以不能再套用上面门级电路分析时,对于建立时间范围的计算公式。
在实际的RTL的设计当中,对于IO信号,我们通常用这样的HDL语句来实现:
assign data_in = lbi_d;
assign lbi_d = (!lbi_cs2_l && !lbi_oe_l && rst_l)? data_out : 8'hzz;
其中,lbi_d是inout port,即local bus的数据位总线。由这个语句可知,当CS和OE都为低时,(通常是OE下降沿时)数据就被打出。根据分析模型列出式子:
OE Trace delay + CPLD Tco + Data Trace delay + Processor Tsu <= Trc
不等号左边的都为已知量,不等号右边的Trc正是我们需要写进processor寄存器的值,即OE保持为低电平的时间长度的最小值,要满足processor的建立时间,Trc必须要大于这个值。
4.总结:
综上,要想在板级设计中满足读写操作时序要求,需要从一开始就在硬件,软件,RTL设计的层面做出如下考虑和优化:
- RTL设计中,尽量拆分和转移组合逻辑的级数;
- RTL设计中,可以采用partition,局部constraint的办法来优化内部互连走线延迟;
- 设置全局的IO端口constraint,包括Tsu, Th, Tco 和 Clock Period;
- 硬件和layout设计时,并行总线尽量做等长处理;
- 最后软件根据实际计算或仿真出的时序进行调整。
特别是对于组合逻辑的拆分和转移处理,可行办法有如下几点:
- 4输入LUT,减少输入条件
- pipelining流水线 —— 如拆分长进位链的计数器
- 三段式状态机
“目前大部分CPLD都基于4输入 LUT的,如果一个输出对应的判断条件大于四输入的话就要由多个LUT级联才能完成,这样就引入一级组合逻辑时延,我们要减少组合逻辑,无非就是要输入条件尽可能的少,这样就可以级联的LUT更少,从而减少了组合逻辑引起的时延。
一个32 位的计数器,该计数器的进位链很长,必然会降低工作频率,我们可以将其分割成4位和 8位的计数,每当4位的计数器计到15后触发一次8位的计数器,这样就实现了计数器的切割,也提高了工作频率。
在状态机中,一般也要将大的计数器移到状态机外,因为计数器这东西一般是经常是大于4输入的,如果再和其它条件一起做为状态的跳变判据的话,必然会增加LUT的级联,从而增大组合逻辑。以一个6输入的计数器为例,我们原希望当计数器计到111100后状态跳变,现在我们将计数器放到状态机外,当计数器计到111011后产生个enable信号去触发状态跳变,这样就将组合逻辑减少了。状态机一般包含三个模块,一个输出模块,一个决定下个状态是什么的模块和一个保存当前状态的模块。组成三个模块所采用的逻辑也各不相同。输出模块通常既包含组合逻辑又包含时序逻辑;决定下一个状态是什么的模块通常又组合逻辑构成;保存现在状态的通常由时序逻辑构成。“
关于pipelining有的同学会问:为了分拆组合逻辑引入了更多的FF,信号从两个level的流过时间将由于这几个FF的插入而变慢了好几个时钟周期,对于IO接口信号来说岂不是更难meet时序要求了么?
关于这个问题,其实是混淆了bit rate和latency概念的区别。下面就以引用旭明兄关于这个问题精彩解答来作为本文的结尾:
"首先。要精确理解在不同的context情况下“时序”究竟说的是啥。“时序”--英文timing,在绝大多数情况下,“时序”说的就是数据(data)相对于时钟(clock)采样的setup/hold。满足了setup/hold,我们就说“满足了timing” 或者“满足了时序要求”。数据传输不能出错,这是数字系统里的最基本的要求。所以,timing(setup/hold)在任何情况下都必须设法满足。至于说“插入FF使得I/O慢了几个clock cycle”的问题。首先,插入FF为的是解决timing问题,很多情况下是必须的。这是一个常用的解决方案。其次。这里所谓的“慢”不是真正的“慢”。准确的说,这叫做“latency”。而描述数据传输快慢的是“bit rate”,不是“latency”。对于某个参考点,“latency”说的是其output data相对于其input data延迟的clock cycle。很多情况下我们并不care latency(需要关注的情况另当别论)。要把传输数据理解成为“流动”的,output数据相对于input数据,它其实只是被“延迟”了,数据流的比特率(bit rate)没有变慢。"
|




