问题八:工厂模式和抽象工厂模式有何不同?
抽象工厂模式提供了多一级的抽象。不同的工厂类都继承了同一个抽象工厂方法,但是却根据工厂的类别创建不同的对象。例如,AutomobileFactory, UserFactory, RoleFactory都继承了AbstractFactory,但是每个工厂类创建自己对应类型的对象。下面是工厂模式和抽象工厂模式对应的UML图。
问题九:什么是单例模式?创建单例对象的时候是将整个方法都标记为synchronized好还是仅仅把创建的的语句标记为synchronized好?
在Java中,单例类是指那些在整个Java程序中只存在一份实例的类,例如java.lang.Runtime就是一个单例类。在Java 4版本及以前创建单例会有些麻烦,但是自从Java 5引入了Enum类型之后,事情就变得简单了。可以去看看我的关于如何使用Enum来创建单例类的文章,同时再看看问题五来看看如何在创建单例类的时候进行双重检查。
问题十:能否写一段用Java 4或5来遍历一个HashMap的代码?
事实上,用Java可以有四种方式来遍历任何一个Map,一种是使用keySet()方法获取所有的键,然后遍历这些键,再依次通过get()方法来获取对应的值。第二种方法可以使用entrySet()来获取键值对的集合,然后使用for each语句来遍历这个集合,遍历的时候获得的每个键值对已经包含了键和值。这种算是一种更优的方式,因为每轮遍历的时候同时获得了key和value,无需再调用get()方法,get()方法在那种如果bucket位置有一个巨大的链表的时候的性能开销是O(n)。第三种方法是获取entrySet之后用iterator依次获取每个键值对。第四种方法是获得key set之后用iterator依次获取每个key,然后再根据key来调用get方法。
问题十一:你在什么时候会重写hashCode()和equals()方法?
当你需要根据业务逻辑来进行相等性判断、而不是根据对象相等性来判断的时候你就需要重写这两个函数了。例如,两个Employee对象相等的依据是它们拥有相同的emp_id,尽管它们有可能是两个不同的Object对象,并且分别在不同的地方被创建。同时,如果你准备把它们当作HashMap中的key来使用的话,你也必须重写这两个方法。现在,作为Java中equals-hashcode的一个约定,当你重写equals的时候必须也重写hashcode,否则你会打破诸如Set, Map等集合赖以正常工作的约定。你可以看看我的另外一篇博文来理解这两个方法之间的微妙区别与联系。
问题十二:如果不重写hashCode方法会有什么问题?
如果不重写equals方法的话,equals和hashCode之间的约定就会被打破:当通过equals方法返回相等的两个对象,他们的hashCode也必须一样。如果不重写hashCode方法的话,即使是使用equals方法返回值为true的两个对象,当它们插入同一个map的时候,因为hashCode返回不同所以仍然会被插入到两个不同的位置。这样就打破了HashMap的本来目的,因为Map本身不允许存进去两个key相同的值。当使用put方法插入一个的时候,HashMap会先计算对象的hashcode,然后根据它来找到存储位置(bucket),然后遍历此存储位置上所有的Map.Entry对象来查看是否与待插入对象相同。如果没有提供hashCode的话,这些就都做不到了。
问题十三:我们要同步整个getInstance()方法,还是只同步getInstance()方法中的关键部分?
答案是:仅仅同步关键部分(Critical Section)。这是因为,如果我们同步整个方法的话,每次有线程调用getInstance()方法的时候都会等待其他线程调用完成才行,即使在此方法中并没有执行对象的创建操作。换句话说,我们只需要同步那些创建对象的代码,而创建对象的代码只会执行一次。一旦对象创建完成之后,根本没有必要再对方法进行同步保护了。事实上,从性能上来说,对方法进行同步保护这种编码方法非常要命,因为它会使性能降低10到20倍。下面是单例模式的UML图。

再补充一下,创建线程安全的单例对象有多种方法,你也可以顺便提一下。
问题十四:HashMap,在调用get()方法的时候equals()和hashCode()方法都起了什么样的作用?
这个问题算是对问题十二的补充,应聘者应该知道的是,一旦你提到了hashCode()方法,人们很可能要问HashMap是如何使用这个函数的。当你向HashMap插入一个key的时候,首先,这个对象的hashCode()方法会被调用,调用结果用来计算将要存储的位置(bucket)。
因为某个位置上可能以链表的方式已经包含了多个Map.Entry对象,所以HashMap会使用equals()方法来将此对象与所有这些Map.Entry所包含的key进行对比,以确定此key对象是否已经存在。
问题十五:在Java中如何避免死锁?
你可以通过打破互相等待的局面来避免死锁。为了达到这一点,你需要在代码中合理地安排获取和释放锁的顺序。如果获得锁的顺序是固定的,并且获得的顺序和释放的顺序刚好相反的话,就不会产生出现死锁的条件了。
问题十六:创建字符串对象的时候,使用字面值和使用new String()构造器这两种方式有什么不同?
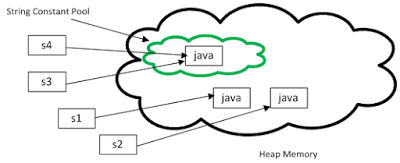
当我们使用new String构造器来创建字符串的时候,字符串的值会在堆中创建,而不会加入JVM的字符串池中。相反,使用字面值创建的String对象会被放入堆的PermGen段中。例如:
String str=new String(“Test”);
这句代码创建的对象str不会放入字符串池中,我们需要显式调用String.intern()方法来将它放入字符串池中。仅仅当你使用字面值创建字符串时,Java才会自动将它放入字符串池中,比如:String s=”Test”。顺便提一下,这里有个容易被忽视的地方,当我们将参数“Test”传入构造器的时候,这个参数是个字面值,因此它也会在字符串池中保存另外一份。想了解更多关于字面值字符串和字符串对象之间的差别,请看这篇文章。
下图很好地解释了这种差异。
问题十七:什么是不可修改对象(Immutable Object)?你能否写一个例子?
不可修改对象是那些一旦被创建就不能修改的对象。对这种对象的任何改动的后果都是会创建一个新的对象,而不是在原对象本身做修改。例如Java中的String类就是不可修改的。大多数这样的类通常都是final类型的,因为这样可以避免自己被继承继而被覆盖方法,在覆盖的方法里,不可修改的特性就难以得到保证了。你通常也可以通过将类的成员设置成private但是非final的来获得同样的效果。
另外,你同样要保证你的类不要通过任何方法暴露成员,特别是那些可修改类型的成员。同样地,当你的方法接收客户类传入的可修改对象的话,你应该使用一个复制的对象来防止客户代码来修改这个刚传入的可修改类。比如,传入java.util.Date对象的话,你应该自己使用clone()方法来获得一个副本。
当你通过类函数返回一个可修改对象的时候,你也要采取类似的防护措施,返回一个类成功的副本,防止客户代码通过此引用修改了成员对象的属性。千万不要直接把你的可修改成员直接返回给客户代码。
问题十八:如何在不使用任何分析工具的情况下用最简单的方式计算某个方法的执行所花费的时间? 在执行此方法之前和之后获取一个系统时间,取这两个时间的差值,即可得到此方法所花费的时间。
需要注意的是,如果执行此方法花费的时间非常短,那么得到的时间值有可能是0ms。这时你可以在一个计算量比较大的方法上试一下效果。
long start=System.currentTimeMillis();
method();
long end=System.currentTimeMillis();
System.out.println("Time taken for execution is "+(end-start));
问题十九:当你要把某个类作为HashMap的key使用的话,你需要重写这个类的哪两个方法? 为了使类可以在HashMap或Hashtable中作为key使用,必须要实现这个类自己的equals()和hashCode()方法。具体请参考问题十四。
问题二十:你如何阻止客户代码直接初始化你的类的构造方法?例如,你有一个名为Cache的接口和两个具体的实现类MemoryCache和DiskCache,你如何保证这两个类禁止客户代码用new关键字来获取它们的实例?
我把这最后一个问题留给你做练习吧,你可以在我给出答案之前好好思索一下。我确信你能够找到正确的方法的,因为这是将类的实现掌控在自己手中的一个重要的方法,同时也能为以后的维护提供巨大的好处。 |




