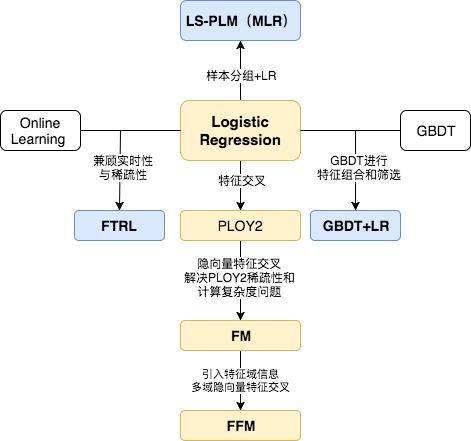
CTR模型特征交叉方向的演化
本章我们沿着传统CTR模型演化图中黄色的部分,朝着特征交叉的演化方向,依次介绍了LR、POLY2,FM和FFM四个模型。
我们再用图示方法回顾一下从POLY2到FM,再到FFM进行特征交叉方法的不同。
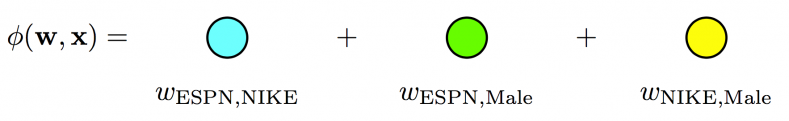
POLY2模型直接学习每个交叉特征的权重,权重数量共n2个。
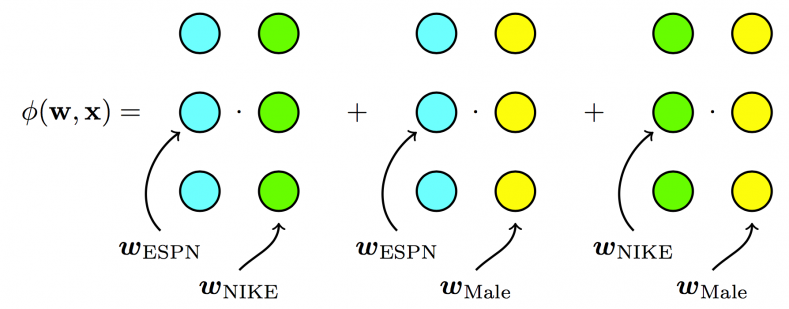
FM模型学习每个特征的k维隐向量,交叉特征由相应特征隐向量的内积得到,权重数量共n*k个。
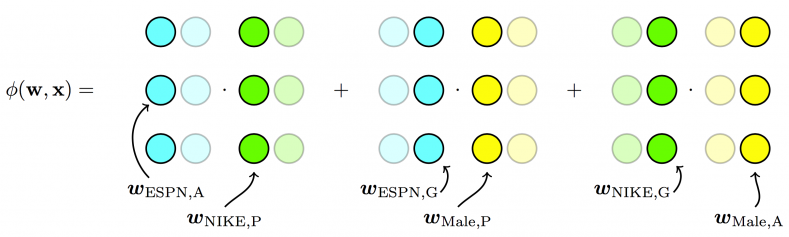
FFM模型引入了特征域这一概念,在做特征交叉时,每个特征选择与对方域对应的隐向量做内积运算得到交叉特征的权重。参数数量共nkf个。
但无论怎样FFM只能够做到二阶的特征交叉,如果要继续提高特征交叉的维度,不可避免的会发生组合爆炸和计算复杂度过高的情况。
下一节的专栏文章将回顾模型演化图中蓝色部分的模型。我将沿着特征工程的角度带大家一起回顾Facebook的CTR模型GBDT+LR,并从时效性的角度看看Google是如何使用FTRL解决模型online learning问题的,最后介绍阿里的LS-PLM,看其是如何从样本聚类的动机出发为传统线性模型引入非线性能力的。期待与大家继续探讨CTR预估模型的内容。 |




